Регресійний аналіз і аналіз дисперсії
У цьому параграфі ми звернемося до регресійного аналізу з погляду аналізу дисперсії.
Раніше нами була доведена така рівність:
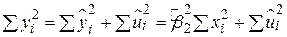 , ,
| (3.8.1) |
тобто TSS=ESS+RSS, яке розкладає загальну суму квадратів (TSS) на два доданки: пояснена сума квадратів (ESS) і сума квадратів залишків (RSS). Вивчення цих доданків у TSS відоме під терміном (ANOVA, analysis variance) аналізу дисперсії з погляду регресії.
З кожною сумою квадратів пов’язані кількість її степенів вільності df, кількість незалежних спостережень, на яких вона заснована. TSS має (N–1) степінь вільності, оскільки ми втрачаємо один степінь при підрахунку середньої величини вибірки 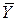 . RSS має (N–2) степені вільності (оскільки
. RSS має (N–2) степені вільності (оскільки 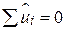 ,
, 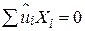 ). ESS має всього один степінь вільності, з огляду на те, що
). ESS має всього один степінь вільності, з огляду на те, що 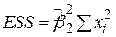 є функція тільки від
є функція тільки від 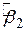 , оскільки
, оскільки 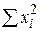 відома. Відзначимо, що вказана кількість степенів вільності справедлива тільки для випадку рівняння регресії з двома змінними.
відома. Відзначимо, що вказана кількість степенів вільності справедлива тільки для випадку рівняння регресії з двома змінними.
Помістимо перераховані суми квадратів і відповідні їм степені вільності в табл. 3.3, що є стандартним видом таблиці ANOVA.
Таблиця 3.3
ANOVA таблиця для регресійної моделі з двома змінними
| Джерела дисперсії | SS | df | MSS |
| Унаслідок дисперсії (ESS) | 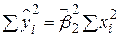
| 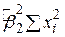
| |
| Унаслідок залишків (RSS) | 
| N–2 | 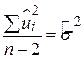
|
| TSS | 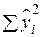
| N–1 | |
| SS - сума квадратів (sum squares) MSS – середня сума квадратів (mean sum squares) |
Розглянемо таку змінну:
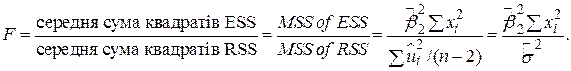
| (3.8.2) |
Якщо ми припустимо, що збурення 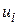 розподілені нормально і
розподілені нормально і 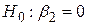 , то можна показати, що змінна F з (3.8.2) задовольняє умови такої теореми: якщо Z1 і Z2 незалежні змінні з k1 і k2, відповідно, степенями вільності, що розподіляється за законом розподілу
, то можна показати, що змінна F з (3.8.2) задовольняє умови такої теореми: якщо Z1 і Z2 незалежні змінні з k1 і k2, відповідно, степенями вільності, що розподіляється за законом розподілу 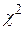 , тоді змінна
, тоді змінна
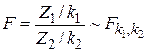
|
розподіляється за законом F-розподілу з k1 і k2 степенями вільності, де k1 називають чисельником степеня вільності, а k2 – знаменником.
Отже, змінна F з (3.8.2) розподіляється за законом F –розподілу з 1 і (N–2) степенями вільності.
Таким чином, можна показати, що
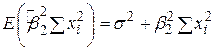 і
і
| (3.8.3) |
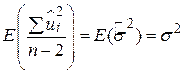 . .
| (3.8.4) |
Отже, якщо 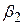 дорівнює 0, обидва рівняння (3.8.3) і (3.8.4) дають нам оцінку істинного значення
дорівнює 0, обидва рівняння (3.8.3) і (3.8.4) дають нам оцінку істинного значення 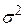 . У цьому випадку пояснювальна змінна Х не впливає лінійно на Y, і зміна Y пояснюється тільки за рахунок випадкового . Водночас, якщо не дорівнює нулю, (3.8.3) і (3.8.4) будуть різними і частину дисперсії в Y можна пояснити за рахунок Х. Отже, коефіцієнт F у (3.8.1) являє собою тест нульової гіпотези
. У цьому випадку пояснювальна змінна Х не впливає лінійно на Y, і зміна Y пояснюється тільки за рахунок випадкового . Водночас, якщо не дорівнює нулю, (3.8.3) і (3.8.4) будуть різними і частину дисперсії в Y можна пояснити за рахунок Х. Отже, коефіцієнт F у (3.8.1) являє собою тест нульової гіпотези 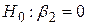 . Оскільки всі величини, що входять у вираз (3.8.1), отримані з вибірки, коефіцієнт дозволяє перевірити гіпотезу про те, що
. Оскільки всі величини, що входять у вираз (3.8.1), отримані з вибірки, коефіцієнт дозволяє перевірити гіпотезу про те, що 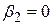 . Усе, що необхідно для цього зробити, це підрахувати F і порівняти його з критичною величиною F, отриманою з таблиць розподілу густини F з вибраним рівнем значимості, або отримати р-величину, обчислену за статистикою F.
. Усе, що необхідно для цього зробити, це підрахувати F і порівняти його з критичною величиною F, отриманою з таблиць розподілу густини F з вибраним рівнем значимості, або отримати р-величину, обчислену за статистикою F.
Для ілюстрації звернемося до нашого прикладу “споживання - дохід” (табл. 3.4).
Таблиця 3.4
ANOVA-таблиця для прикладу “споживання - дохід”
| Джерело дисперсії | SS | df | MSS | F-відношення |
| Унаслідок регресії (ESS) | 8552,73 | 8552,73 | F=85552,73/42,159= =202,87 | |
| Унаслідок залишків (RSS) | 337,27 | 42,159 | ||
| TSS | 8890,00 |
Із таблиці бачимо, що обчислена величина F = 202,87. Величина р, відповідна цій статистиці, з 1 і 8 степенями вільності не може бути отримана з таблиці розподілу F, але, використовуючи електронні комп’ютерні таблиці, можна показати, що ця величина є 0,0000001, тобто дуже малою. Якщо ви при перевірці гіпотез застосуєте підхід за рівнем значимості a=0,01 або 1%, то побачите, що обчислений коефіцієнт F = 202,87 є значимим для цього рівня. Отже, якщо ми відкинемо нульову гіпотезу про те, що , то імовірність виникнення помилки 1типу (відкидається правильна гіпотеза) дуже мала. Отже, з великою імовірністю ми можемо зробити висновок, що дохід Х впливає на витрати і споживання Y.
Пригадаємо теорему про те, що квадрат величини t з k степенями вільності дорівнює F з 1 степенем вільності чисельника і k степенями вільності знаменника, тобто 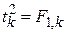 . Для нашого прикладу моделі “споживання - дохід”, якщо ми покладемо , то з формули для t (3.3.2) легко отримати
. Для нашого прикладу моделі “споживання - дохід”, якщо ми покладемо , то з формули для t (3.3.2) легко отримати
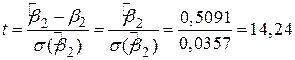 . .
|
Це значення змінної t має 8 степенів вільності. При тій же нульовій гіпотезі F = 202,87 має 1 і 8 степенів вільності. Отже, з точністю до округлення маємо 14,242=202,87.
Таким чином, t- і F-тести дають нам два альтернативних, але взаємодоповнюючих шляхи перевірки нульової гіпотези про те, що . Якщо це так, то чому не обмежитися t-тестом і не перевіряти F-тест? Виявляється, що для моделі з двома змінними це можна припустити. Але для моделі множинної регресії ми побачимо, що F тест має деякі цікаві додатки, що робить його дуже корисним і потужним методом перевірки статистичних гіпотез.
Дата добавления: 2016-07-27; просмотров: 2302;
Поиск по сайту
Узнать еще
- Інтегральний метод в економічному аналізі
- АНАЛІЗ І ПРОЕКТУВАННЯ КУЛАЧКОВИХ МЕХАНІЗМІВ
- Аналіз існуючих виробів та визначення завдань проекту
- Аналіз автоматів з D-тригерами
- Аналіз автоматів з JK-тригерами
- Аналіз відходів у виробництві
- Аналіз вікового складу устаткування
- Аналіз валового прибутку від реалізації продукції, тис. грн.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
