Моделирование непрерывных распределений
Большинство методов моделирования случайных величин на ЭВМ с различными законами распределения основано на использовании следующей теоремы:
Если случайная величина x имеет плотность распределения f(x), то распределение случайной величины y=F(x) является равномерным на интервале (0,1).
Здесь под F(x) понимается интегральная функция распределения случайной величины x.
Следовательно, можно поступить наоборот: построить функцию распределения F(x); выбрать случайное значение y из равномерного распределения в интервале (0,1) и определить то значение аргумента х, для которого F(x)=y.
Полученная таким образом случайная величина x будет иметь заданную функцию распределения F(x).
Эта же задача может быть решена не только графическими построениями, но и рядом других способов. В частности, аналитический способ основан на обратном преобразовании x=F –1(y), где F –1 – функция, обратная F.
Это преобразование сводится к решению интегрального уравнения относительно xi
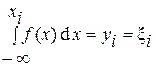 , (1)
, (1)
т.е. определяется такое значение xi, при котором функция распределения равна yi = ξi, где ξi – значение случайной величины, равномерно распределенной на интервале (0,1).
В общем случае применение аналитических способов решения этого уравнения связано со значительным расходом машинного времени. Однако в частных случаях, когда решение уравнения (1) можно получить в явном виде, этот способ очень удобен.
Одним из наиболее экономных (по затратам машинного времени) методов получения случайных чисел с заданным законом распределения является способ кусочной аппроксимации плотности распределения f(x).
Сущность этого метода состоит в том, что область возможных значений случайной величины х разбивается на n интервалов, количество которых определяется точностью аппроксимации плотности распределения f(x). Левую границу k–го интервала обозначим аk.
Будем считать, что в пределах интервала (аk, аk+1), значение функции fk(x) не изменяется, тем самым мы заменяем кривую f(x) ступенчатой функцией.
Если случайным образом из n интервалов выбрать интервал (аk, аk+1), то получение случайного числа хi с плотностью f(x) сводится к формированию равномерного распределения в интервале (аk, аk+1)
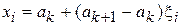 . (2)
. (2)
Для использования этой формулы необходимо располагать n значениями аk, которые рассчитываются для заданного закона распределения f(x) и вводятся в оперативную память ЭВМ в порядке возрастания. Простейшая процедура расчета величин аk основана на предположении, что вероятность попадания в любой из n интервалов одинакова и равна, очевидно, 1/n. Это означает, что мы выбираем такие интервалы, в которых приращение функции распределения F(x) при переходе от k–го к (k+1)–му интервалу было постоянным и равным 1/n, т.е.
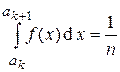 . (3)
. (3)
Вследствие нелинейности функции распределения F(x) (за исключением равномерного распределения) длина интервалов (аk, аk+1) получается различной.
Начальное значение аk =а0 всегда известно – оно равно минимальному значению случайной величины х. Следовательно, соотношение (3) позволяет последовательно вычислить все аk (k = 1, …, n), т.е. решается оно относительно верхнего предела интегрирования. Значение n обычно принимается равным 2m, где m=4…6 (n=16…64).
Для организации случайной выборки k–го интервала из равномерного распределения извлекается случайное целое число 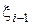 и первые m разрядов используются в качестве адреса для выбора из таблицы значений аk и аk +1. Затем по формуле (2) определяется значение хi, при этом используется уже новое случайное число
и первые m разрядов используются в качестве адреса для выбора из таблицы значений аk и аk +1. Затем по формуле (2) определяется значение хi, при этом используется уже новое случайное число 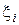 .
.
Данный метод формирования случайных чисел находит широкое практическое применение благодаря своей универсальности и экономичности. Его недостатком является неравномерная точность аппроксимации.
Из рассмотрения методов моделирования случайных величин следует, что для их реализации необходимо иметь случайную величину ξ с равномерным распределением либо на интервале (0,1), либо на интервале (аk,аk +1), в общем случае на интервале (a, b).
Дата добавления: 2016-06-22; просмотров: 1819;
Поиск по сайту
Узнать еще
- Автоматизация ТП. Моделирование техпроцесса.
- Автоматическое регулирование непрерывных процессов.
- Аппроксимация на основе типовых распределений
- Аппроксимация на основе универсальных семейств распределений
- Биологическое моделирование
- Введение в математическое моделирование.
- ВЫЧИСЛЕНИЕ ЦЕН НЕПРЕРЫВНЫХ ФЬЮЧЕРСОВ
- Геометрическое моделирование и синтез форм деталей

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
