ТЕХНИКА СТОХАСТИЧЕСКОГО МОДЕЛИРОВАНИЯ
Понятие «случайный» - одно из самых фундаментальных как в математике, так и в повседневной жизни. Моделирование случайных процессов - мощнейшее направление в современном математическом моделировании.
Событие называется случайным, если оно достоверно непредсказуемо. Случайность окружает наш мир и чаще всего играет отрицательную роль в нашей жизни. Однако есть обстоятельства, в которых случайность может оказаться полезной.
В сложных вычислениях, когда искомый результат зависит от результатов многих факторов, моделей и измерений, можно сократить объем вычислений за счет случайных значений значащих цифр. Из теории эволюции следует, что случайность проявляет себя как конструктивный, позитивный фактор. В частности, естественный отбор реализует как бы метод проб и ошибок, отбирая в процессе развития особи с наиболее целесообразными свойствами организма. Далее случайность проявляется в множественности ее результатов, обеспечивая гибкость реакции популяции на изменения внешней среды.
В силу сказанного имеет смысл положить случайность в основу методов получения решения посредством проб и ошибок, путем случайного поиска.
Отметим, что выше, приведя пример имитационного моделирования - игру «Жизнь», мы уже имели по сути дела стохастическую модель. В данном параграфе обсудим методологию такого моделирования более детально.
Итак, пусть в функционале модели значения некоторых входных параметров определены лишь в вероятностном смысле. В этом случае значительно меняется сам стиль работы с моделью.
При серьезном рассмотрении в обиходе появляются слова «распределение вероятностей», «достоверность», «статистическая выборка», «случайный процесс» и т.д.
При компьютерном математическом моделировании случайных процессов нельзя обойтись без наборов, так называемых, случайных чисел, удовлетворяющих заданному закону распределения. На самом деле эти числа генерирует компьютер по определенному алгоритму, т.е. они не являются вполне случайными хотя бы потому, что при повторном запуске программы с теми же параметрами последовательность повторится; такие числа называют «псевдослучайными».
Рассмотрим вначале генерацию чисел равновероятно распределенных на некотором отрезке. Большинство программ - генераторов случайных чисел - выдают последовательность, в которой предыдущее число используется для нахождения последующего. Первое из них - начальное значение. Все генераторы случайных чисел дают последовательности, повторяющиеся после некоторого количества членов, называемого периодом, что связано с конечной длиной машинного слова. Самый простой и наиболее распространенный метод - метод вычетов, или линейный конгруэнтный метод, в котором очередное случайное число xn определяется«отображением»
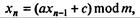
где a, с, m - натуральные числа, mod - так называемая, функция деления по модулю (остаток от деления одного числа на другое по модулю). Наибольший возможный период датчика (7.69) равен т; однако, он зависит от а и с. Ясно, что чем больше период, тем лучше; однако реально наибольшее m ограничено разрядной сеткой ЭВМ. В любом случае используемая в конкретной задаче выборка случайных чисел должна быть короче периода, иначе задача будет решена неверно. Заметим, что обычно генераторы выдают отношение 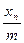 , которое всегда меньше 1, т.е. генерируют последовательность псевдослучайных чисел на отрезке [0,1].
, которое всегда меньше 1, т.е. генерируют последовательность псевдослучайных чисел на отрезке [0,1].
Вопрос о случайности конечной последовательности чисел гораздо сложнее, чем выглядит на первый взгляд Существует несколько статистических критериев случайности, но все они не дают исчерпывающего ответа. Так, последовательно генерируемые псевдослучайные числа могут появляться не идеально равномерно, а проявлять тенденцию к образованию групп (т е. коррелировать) Один из тестов на равномерность состоит в делении отрезка [0, 1] на М равных частей - «корзин», и помещения каждого нового случайного числа в соответствующую «корзину». В итоге получается гистограмма, в которой высота каждого столбика пропорциональна количеству попавших в «корзину» случайных чисел (рис. 7.54).
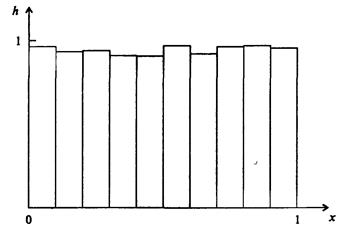
Рис. 7.54. Вид гистограммы для равномерно распределенных на отрезке [0,1] чисел при достаточно большой выборке
Понятно, что при большом числе испытаний высоты столбиков должны быть почти одинаковыми. Однако, этот критерий является необходимым, но не достаточным; например, он «не замечает» даже очень короткой периодичности Для не слишком требовательного пользователя обычно достаточны возможности датчика (генератора) случайных чисел, встроенного в большинство языков программирования. Так, в PASCAL есть функция random, значения которой - случайные числа из диапазона [0, 1). Ее использованию обычно предшествует использование процедуры randomize, служащей для начальной «настройки» датчика, т.е. получения при каждом из обращений к датчику разных последовательностей случайных чисел. Для задач, решение которых требует очень длинных некоррелированных последовательностей, вопрос осложняется и требует нестандартных решений Равномерно распределенные случайные числа - простейший случай Располагая датчиком случайных чисел, генерирующим числа r Î [0, 1], легко получить числа из произвольного интервала [а, b].
X = a + (b - a)∙r.
Более сложные распределения часто строятся с помощью распределения равномерного. Упомянем здесь лишь один достаточно универсальный метод Неймана (часто называемый также методом отбора-отказа), в основе которого лежит простое геометрическое соображение. Допустим, что необходимо генерировать случайные числа с некоторой нормированной функцией распределения f(x) на интервале [а, b]. Введем положительно определенную функцию сравнения w(x) такую, что w(x) = const и w(x) > f(x) на [а, b] (обычно w(x) равно максимальному значению f(x) на [а, b]). Поскольку площадь под кривой f(x) равна для интервала [х, х + dx]вероятности попадания х в этот интервал, можно следовать процедуре проб и ошибок. Генерируем два случайных числа, определяющих равновероятные координаты в прямоугольнике A BCD с помощью датчика равномерно распределенных случайных чисел:
x = a + (b - a)∙r, y = w∙r
и если точка М(х, у) не попадает под кривую f(x), мы ее отбрасываем, а если попадает - оставляем (рис. 7.55). При этом множество координат х оставленных точек оказывается распределенным в соответствии с плотностью вероятности f(x).
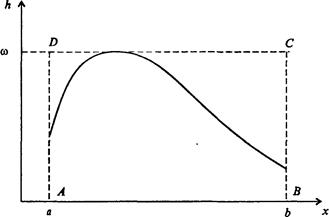
Рис. 7.55. Метод отбора-отказа. Функция w(x) = fmax
Этот метод для ряда распределений не самый эффективный, но он универсален, прост и понятен. Эффективен он тогда, когда функция сравнения w(x) близка к f(х). Заметим, что никто не заставляет нас брать w(x)= const на всем промежутке [а, b]. Если f(x) имеет быстро спадающие «крылья», то разумнее взять w(x) в виде ступенчатой функции.
6.2. МОДЕЛИРОВАНИЕ СЛУЧАЙНЫХ ПРОЦЕССОВ В СИСТЕМАХ МАССОВОГО ОБСЛУЖИВАНИЯ
Комуне случалось стоять в очереди и с нетерпением прикидывать, успеет ли он сделать покупку (или заплатить за квартиру, покататься на карусели и т.д.) за некоторое имеющееся в его распоряжении время? Или, пытаясь позвонить по телефону в справочную и натыкаясь несколько раз на короткие гудки, нервничать и оценивать - дозвонюсь или нет? Из таких «простых» проблем в начале XX века родилась весьма непростая наука - теория массового обслуживания, использующая аппарат теории вероятностей и математической статистики, дифференциальных уравнений и численных методов. Основоположником ее стал датский ученый А.К.Эрланг, исследовавший проблемы функционирования телефонных станций.
Впоследствии выяснилось, что новая наука имеет многочисленные выходы в экономику, военное дело. организацию производства, биологиюи экологию; по нейнаписаны десятки книг, тысячи журнальных статей.
Компьютерное моделирование при решении задач массового обслуживания. реализуемое в виде метода статистических испытаний (метода Монте-Карло), хоть и не является в теории массового обслуживания основным, но играет в ней важную роль. Основная линия в ней - получение результатов аналитических, т.е. представленных формулами. Однако, возможности аналитических методов весьма ограничены, в то время как метод статистических испытаний универсален и весьма прост для понимания (по крайней мере кажется таковым).
Типичная задача: очередь к одному «продавцу». Рассмотрим одну из простейших задач данного класса. Имеется магазин с одним продавцом, в который случайным образом входят покупатели. Если продавец свободен, он начинает обслуживать покупателя сразу, если покупателей несколько, выстраивается очередь.
Вот аналогичные задачи:
• ремонтная зона в автохозяйстве и автобусы, сошедшие с линии из-за поломки;
•травмопункт и больные, пришедшие на прием по случаю травмы (т.е. без системы предварительной записи);
• телефонная станция с одним входом (или одной телефонисткой) и абоненты, которых при занятом входе ставят в очередь (такая система иногда практикуется);
• сервер локальной сети и персональные машины на рабочем месте, которые шлют сообщение серверу, способному воспринять разом и обработать не более одного сообщения.
Будем для определенности говорить о магазине, покупателях и продавце. Рассмотрим возникающие здесь проблемы, которые заслуживают математического исследования и, как выясняется, весьма серьезного.
Итак, на входе этой задачи случайный процесс прихода покупателей в магазин. Он является «марковским», т.е. промежутки между приходами любой последовательной пары покупателей - независимые случайные события, распределенные по некоторому закону. Реальный характер этого закона может быть установлен лишь путем многочисленных наблюдений; в качестве простейшей модельной функции плотности вероятности можно взять равновероятное распределение в диапазоне времени от 0 до некоторого Т - максимально возможного промежутка между приходами двух последовательных покупателей. При этом распределении вероятность того, что между приходами двух покупателей пройдет 1 минута, 3 минуты или 8 минут одинакова (если T > 8).
Такое распределение, конечно, малореалистично; реально оно имеет при некотором значении t = τ максимум и быстро спадает при больших t, т.е. имеет вид, изображенный на рис. 7.56.
Можно, конечно, подобрать немало элементарных функций, графики которых похожи на тот, что изображен на рис. 7.56. Например, семейство функций Пуассона, широко используемых в теории массового обслуживания:
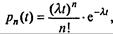 (7.70)
(7.70)
где λ - некоторая константа, п - произвольное целое. Функции (7.70) имеют максимум при 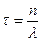 и нормированы:
и нормированы:  pn(t)dt = 1.
pn(t)dt = 1.
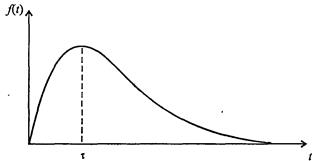
Рис. 7.56. Типичная плотность вероятности распределения времени между приходами покупателей
Второй случайный процесс в этой задаче, никак не связанный с первым, сводится к последовательности случайных событий - длительностей обслуживания каждого из покупателей. Распределение вероятностей длительности обслуживания качественно имеет тот же вид, что и в предыдущем случае; при отработке первичных навыков моделирования методом статистических испытаний вполне уместно принять модель равновероятного распределения.
В таблице 7.8 в колонке А записаны случайные числа - промежутки между приходами покупателей (в минутах), в колонке В - случайные числа - длительности обслуживания (в минутах). Для определенности взято аmax = 10 и bmах = 5. Из этой короткой таблицы, разумеется, невозможно установить, каковы законы распределения приняты для величин А и В; в данном обсуждении это не играет никакой роли. Остальные колонки предусмотрены для удобства анализа; входящие в них числа находятся путем элементарного расчета. В колонке С представлено условное время прихода покупателя, в колонке D - момент начала обслуживания, Е - момент конца обслуживания, F - длительность времени, проведенного покупателем в магазине в целом, G - в очереди в ожидании обслуживания, Н - время, проведенное продавцом в ожидании покупателя (магазин пуст). Таблицу удобно заполнять по горизонтали, переходя от строчки к строчке. Приведем для удобства соответствующие формулы (в них i = 1, 2, 3,...):
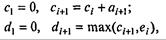
так как начало обслуживания очередного покупателя определяется либо временем его прихода, если магазин пуст, либо временем ухода предыдущего покупателя;
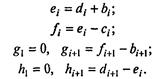
Таблица 7.8
Дата добавления: 2020-02-05; просмотров: 792;
Поиск по сайту
Узнать еще
- IV.Техника настройки
- А) Бронетанковая техника
- А. Возникновение и эволюция глобального моделирования
- А. Классификация видов моделирования (Л.5)
- Алгоритм моделирования по принципу особых состояний.
- Алгоритм моделирования процесса управления комплексной информатизацией образовательных систем на основе функционального подхода
- Алгоритм моделирования системы электропривода по методу структурных схем
- Алгоритм моделирования системы электропривода по методу уравнений состояния

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
