Первичная обработка лингвистической информации.
Цель: Овладеть навыком первичной обработки лингвистической информации, получения её числовых характеристик «вручную» и с помощью программы SPSS на компьютере.
Задание.Проведите первичную обработку полученных данных. Получите числовые характеристики (описательные статистики) полученного распределения (на занятии обрабатываются данные по количеству глаголов в указанных фрагментах, а данные по количеству местоимений и существительных обрабатываются самостоятельно).
1. Постройте интервальный статистический ряд :
| xi | [x0;x1) | [x1;x2) | … | [xk-1;xk) |
| ni | n1 | n2 | … | nk |

| 
| 
| … | 
|
ni -частота попадания значений выборки в i-тый интервал;
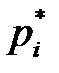 - относительная частота попадания в i-тый интервал.
- относительная частота попадания в i-тый интервал.
Ширина каждого интервала разбиения равна h: 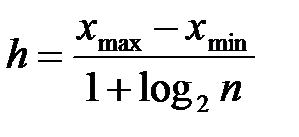 .
.
Начало первого интервала: 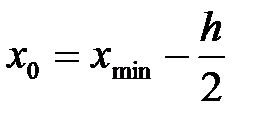
2. Постройте гистограмму относительных частот (частостей). Высота прямоугольников гистограммы вычисляется по формуле 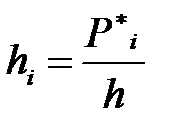
Проведите кривую через середины вершин прямоугольников гистограммы (аналог графика функции f(x) плотности распределения сравнивается с графиком f(x) для нормального распределения).
3. Найдите середины интервалов и постройте соответствующий дискретный статистический ряд.
4. Для получившегося дискретного ряда определите:
а) среднее выборочное 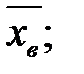
б) выборочную дисперсию 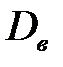 ;
;
в) исправленную выборочную дисперсию 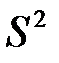 ;
;
г) исправленное среднее квадратическое отклонение 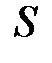 ;
;
д) асимметрию, стандартное отклонение асимметрии (вычислить только в программе SPSS);
е) эксцесс, стандартное отклонение эксцесса (вычислить только в программе SPSS).
Произведите вычисление всех описательных статистик на компьютере в программе SPSS.
Для решения приведённой задачи с использованием программы SPSS- необходимо выполнить следующие действия:
Открыть программу SPSS. Кнопки «Пуск», «Все программы», «SPSSstatistics»
1) В меню File(Файл) выбрать Open(Открыть)>Data(Данные).
2) В открывшемся окне установить тип файла Excel(`*.xls;`*xlsx;`*xlsm) и выбрать файл с вашими данными.
3) Выбрать Analyze(Анализ) > Descriptivestatistics(Описательные статистики) > Frequencies(частоты)…
4) В открывшемся диалоговом окне переместить Х в раздел ”Variable(s)”(переменные).
5) Открыть вкладку `Statistics ` «статистики».
Ставим флажок в квадратиках `Mean`(среднее),`Wariance`(дисперсия), `Std. deviation` (стандартное отклонение), Range (размах), `Kurtosis` (Асимметрия) и `Skewness` (Эксцесс), нажимаем `Continue` (продолжить).
6) Открыть вкладку Chats(диаграммы). Ставим флажок в квадратиках Histograms(гистограммы) и With normal curve (с нормальной кривой), нажимаем `Continue` (продолжить).
7) Снять флажок в квадратике Displayfrequencytables(выводить частотные таблицы), т.к. данные таблицы неинформативны.
8) Нажимаем OK
В полученном окне вывода получаем нужные описательные статистики, а также гистограмму частот с кривой нормального распределения.
Сравните статистики, полученные «вручную» и с помощью программы SPSS.
Сделайте вывод о приближённом соответствии распределения числа глаголов (существительных, местоимений) нормальному распределению.
Дата добавления: 2016-06-05; просмотров: 1795;
Поиск по сайту
Узнать еще
- I. Обработка поверхности изделий.
- I. Обработка результатов журнала технического нивелирования.
- III. Последующая обработка.
- Абразивная обработка
- Автоматизация обработки табличных данных (обработка списков)
- Автоматизированная тематическая обработка радиолокационных снимков.
- Амминирование и гидразинная обработка питательной воды
- Анатомическое строение корней. Первичная и вторичная структура корня.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
