Моделирование случайных величин
При моделировании случайныхдискретных величин наиболее часто используют метод последовательных сравнений, или метод интерпретации.
Метод последовательных сравнений.Для моделирования случайной дискретной величины X, заданной законом распределения
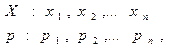
необходимо:
разыграть случайное число r в интервале (0,1) по равномерному закону;
Число r последовательно сравнивать со значением суммы 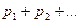 где
где 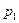 – вероятность наименьшего значения случайной величины X,
– вероятность наименьшего значения случайной величины X, 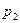 – вероятность второго по величине значения. При первом же выполнении следующего условия проверка прекращается и случайная дискретная величина X считается принявшей значение
– вероятность второго по величине значения. При первом же выполнении следующего условия проверка прекращается и случайная дискретная величина X считается принявшей значение 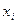 :
:
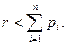
Процесс можно ускорить, применяя методы оптимизации перебора: дихотомии, ранжирования p и т.д. Величины pi рассчитывают по функциям распределения вероятности, соответствующим моделируемому закону.
Метод интерпретации.Метод основан на физической трактовке моделируемого закона распределения. Например, биномиальное распределение описывает число успехов в n независимых испытаниях с вероятностью успеха в каждом испытании p и вероятностью неудачи g=1-p.
При моделировании этого распределения с помощью метода интерпретации выбирают n независимых случайных чисел, равномерно распределенных на интервале (0,1), и подсчитывают количество тех из них, которые меньше p. Это число и является моделируемой случайной величиной.
При моделировании случайной непрерывной величины с заданным законом распределения используют метод преобразования закона распределения случайной величины [4] специальным расчетным соотношением, которое позволяет вычислять значение случайной величины по значению случайного числа, равномерно распределенного на интервале (0,1).
Для того чтобы разыграть возможное значение случайной непрерывной величины X, зная ее функцию распределения 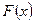 , надо выбрать случайное число
, надо выбрать случайное число 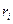 , приравнять его функции распределения и решить относительно полученное уравнение
, приравнять его функции распределения и решить относительно полученное уравнение 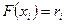 .
.
Если известна плотность вероятности 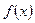 , то уравнение, с помощью которого можно определить значения имеет вид
, то уравнение, с помощью которого можно определить значения имеет вид
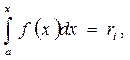
где a – конечное наименее возможное значение X.
Такие соотношения получены практически для всех наиболее распространенных видов распределений и приведены в справочной литературе. В качестве примера ниже даны расчетные соотношения для двух законов распределения – показательного и нормального:
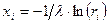 ,
, 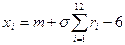 .
.
Здесь λ – параметр показательного распределения, а m, σ – параметры нормального закона распределения.
Технологию моделирования случайных непрерывных величин поясним на примерах [3].
Из практики известно, что интервалы времени между отказами в технических системах распределены по экспоненциальному закону. Чтобы получить в модели величину промежутка времени между двумя соседними отказами, достаточно сгенерировать случайное число r и подставить его в указанное выше выражение для показательного закона распределения при известном параметре распределения λ.
Нормальный закон имеет более широкий диапазон применения, поскольку любая величина, зависящая от большого числа случайных факторов, может считаться распределенной по нормальному закону. Например, при стрельбе в центр мишени координаты точек попадания можно считать распределенными по нормальному закону с параметрами m и σ, где m – координаты точки прицеливания, а σ характеризует отклонение от нее по каждой из координат. Для определенности предположим, что 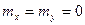 , а
, а 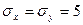 , то есть центр мишени имеет координаты (0,0), а отклонение составляет 5см. Чтобы смоделировать координаты очередной точки попадания, следует получить от датчика две последовательности из 12 случайных чисел для каждой из координат в отдельности и подставить их вместе с параметрами закона в выражение для нормального закона распределения:
, то есть центр мишени имеет координаты (0,0), а отклонение составляет 5см. Чтобы смоделировать координаты очередной точки попадания, следует получить от датчика две последовательности из 12 случайных чисел для каждой из координат в отдельности и подставить их вместе с параметрами закона в выражение для нормального закона распределения:
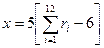 ,
, 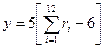 .
.
В одной и той же имитационной модели могут фигурировать несколько случайных факторов, одни из них могут быть представлены как случайные события, другие – как случайные величины или функции. Более того, если моделируется поведение достаточно сложной системы, то ее функционирование может быть связано с возникновением нескольких типов событий и учетом большого числа случайных величин, распределенных по различным законам. Если же моделирование всех случайных факторов основано на использовании одного датчика, генерирующего одну «общую» последовательность случайных чисел, то с математической точки зрения их нельзя считать независимыми. В связи с этим для моделирования каждого случайного фактора стараются использовать отдельный генератор, или, по крайней мере, обеспечивать создание новой последовательности случайных чисел. Во многих специализированных языках и пакетах моделирования такая возможность предусмотрена.
Дата добавления: 2016-10-18; просмотров: 4656;
Поиск по сайту
Узнать еще
- Pиc. 67. Зависимость скорости осаждения от величины катодно-анодного отношения
- Інвестиції: сутність, фактори, які впливають на їх величину
- Індекси середніх величин.
- Абсолютні статистичні величини та одиниці їх вимірювання
- Абсолютная величина и норма матрицы.
- Абсолютные и относительные величины
- Абсолютные и относительные величины.
- Абсолютные статистические величины

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
