Основная теорема Шеннона для дискретного канала с шумом
Формулировка
Для дискретного канала в шумом существует такой способ кодирования, при котором может быть обеспечена безошибочная передача все информации, поступающей от источника сообщений, если только пропускная способность канала превышает производительность источника сообщений, т.е. если выполняется условие:
Vк max [ log2m – H(B/B’)] > Vи * H(A),(4.1)
где H(A) – энтропия источника.
Здесь обозначения соответствуют схеме, изображенной на рис. 4.6.
 В – символы на входе, а В’ – на выходе канала;
Vи и Vк – скорость поступления символов от источника на вход кодирующего устройства и с выхода кодирующего устройства на вход линии связи.
В – символы на входе, а В’ – на выходе канала;
Vи и Vк – скорость поступления символов от источника на вход кодирующего устройства и с выхода кодирующего устройства на вход линии связи.
|
Доказательство
Согласно полученной ранее формуле, число типичных последовательностей длительностью Т равно:
Nтип(А) = 2Vи*T*H(A) (4.2)
Максимально возможное число различных последовательностей на выходе кодера, которое сможет иметь ту же длительность, Т равна:
N(B) = mVк*T,
где m – объем вторичного алфавита.
Эту формулу можно записать также в виде:
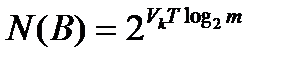 (4.3)
(4.3)
Предположим, что условие теоремы Vк [ log2m – H(B/B’)] > Vи * H(A) выполняется. Тогда, поскольку H(B/B’)>0, неравенство условия теоремы только усилится, если его записать в виде: Vк log2m > Vи * H(A).
Домножим левую и правую части неравенства на Т и сделаем их показателями двойки:
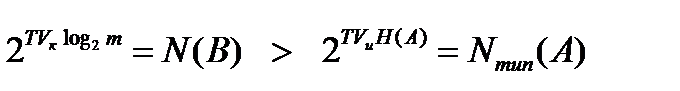 .
.
Таким образом, возможное число последовательностей длительностью Т на выходе кодера больше числа типичных последовательностей той же длительности, которое может выдать источник.
Если установить однозначное соответствие между последовательностями на выходе кодера с последовательностями на входе, остаются последовательности, которые не могут использоваться для кодирования, т.е. запрещенные кодовые слова. Если все же такая последовательность получается с выхода канала связи – это верный признак ошибки.
Каждому способу кодирования будет соответствовать определенный вариант установки соответствия между каждой из множества типичных последовательностей, генерируемых источником и кодовым словом, взятым из множества разрешенных кодовых слов N(B).
Требуется теперь доказать, что среди всех возможных способов установки этого соответствия существует такой, который обеспечивает однозначную идентификацию любого принятого кодового слова, даже если оно получилось в результате искажения помехой передаваемого слова.
Для доказательства найдем вероятность правильного приема, усредненную по всем возможным способам кодирования, т.е. установки соответствия между принятым и возможно искаженным кодовым словом и закодированной информационной последовательностью.
По условной энтропии H(B/B’) можно найти количество возможных типичных последовательностей на входе канала, которые после искажения в нем могли бы дать определенную последовательность на выходе канала:
Nтип(B/B’) = 2T Vк H(B/B’) . (4.4)
Вывод аналогичен сделанному ранее при исследовании свойств типичных последовательностей. Только в данном случае энтропия символа на выходе канала – функция того, какой символ получен на входе канала – H(B/B’).
Правильный прием возможен только тогда, когда на [Nтип(B/B’)-1] не разрешенных кодовых слов приходится одно разрешенное, т.е. число возможных кодовых слов вообще должно быть в Nтип(B/B’) раз больше числа типичных Nтип(A) последовательностей, которые может выдать источник.
Предположим теперь, что соответствия между типичными последовательностями, выдаваемыми источником, и кодовыми словами устанавливаются равновероятно. Тогда вероятность pразр того, что определенное кодовое слово среди Nтип(А) является разрешенным, равна: pразр=Nтип(А)/N(B) (кодируются только типичные последовательности).
Соответственно, вероятность того, что кодовое слово является запрещенным равна 1- pразр= 1 - Nтип(А)/N(B).
Правильное декодирование возможно только тогда, если среди Nтип(B/B’) кодовых слов только одно выбрано в качестве разрешенного.
Вероятность этого равна:
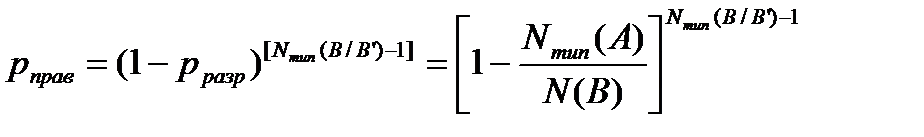 .
.
Так как основание степени 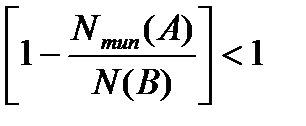 , то, увеличивая показатель степени с Nтип(B/B’)-1 до Nтип(B/B’), получим неравенство:
, то, увеличивая показатель степени с Nтип(B/B’)-1 до Nтип(B/B’), получим неравенство:
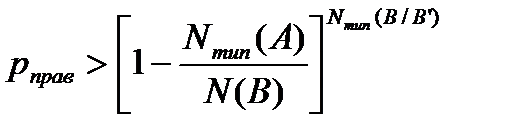 . (4.5)
. (4.5)
Разложим правую часть этого неравенства в ряд по степеням 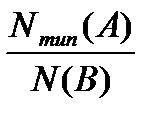 (ряд Тэйлора[15]):
(ряд Тэйлора[15]):
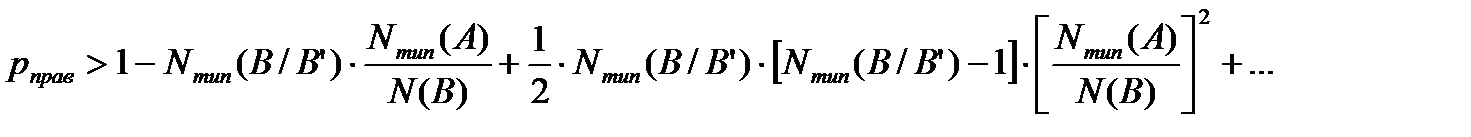
Поскольку 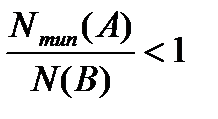 и члены ряда по абсолютной величине убывают, неравенство (5) только усиливается, если отбросить все члены ряда выше первого порядка:
и члены ряда по абсолютной величине убывают, неравенство (5) только усиливается, если отбросить все члены ряда выше первого порядка:
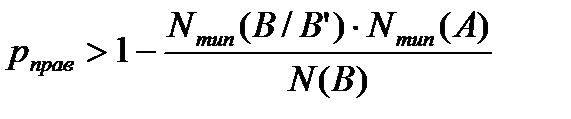 .
.
Подставив в это выражение выражения (2), (3), (4), получим:
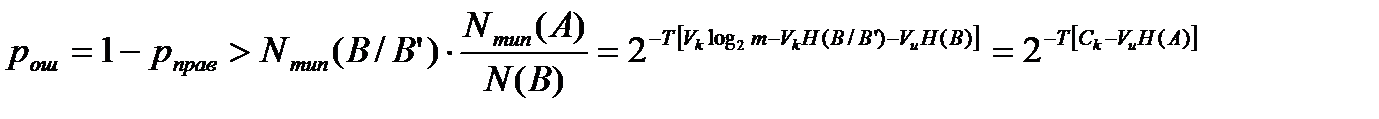 ,
,
где Сk =Vk*log2m-Vk*H(B/B’) – пропускная способность канала связи с учетом потерь информации в результате действия помех (шума).
Заметим, что, если Ck > Vи*H(A) (условие теоремы Шеннона), с ростом Т вероятность ошибки Рош стремится к 0.
Помимо ошибки, возможной при приеме типичных последовательностей, вероятность которой определяется последней формулой, возможны ошибки за счет появления на выходе источника нетипичных последовательностей, кодирование которых вообще не предусматривается описанной процедурой. При вероятностях появления нетипичной последовательности 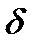 и типичной
и типичной  суммарная вероятность ошибочной передачи равна:
суммарная вероятность ошибочной передачи равна: 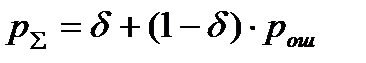 .
.
При 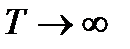 , как было показано ранее,
, как было показано ранее, 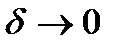 .
.
Если Сk-VиH(A) > 0 (т.е. при условии выполнения теоремы Шеннона), то при и  суммарная ошибка
суммарная ошибка 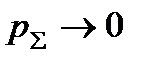 .
.
Поскольку среди всех вариантов кодирования обязательно существует хотя бы один, для которого вероятность ошибки не превышает среднего по всем вариантам кодирования значения 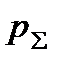 , теорему Шеннона можно считать доказанной.
, теорему Шеннона можно считать доказанной.
Дата добавления: 2021-04-21; просмотров: 664;
Поиск по сайту
Узнать еще
- Andantino con moto А. Бородин. Для берегов отчизны дальней
- C) Теорема затухания (Теорема смещения)
- I тип реакций. Реакции, характерные для органических кислот.
- I. 5. Тесты для контроля знаний раздела I
- II закон термодинамики. Теорема Карно-Клаузиуса
- II раздел. Организация работы логопеда в группе для детей с ОНР
- II. Основная часть занятия
- II. Основная часть занятия

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
