Хэшированная организация
Записи размещаются в отведенной области по вычисляемым адресам. Адрес хранения записи расчитывается по значениям ключа хэширования (поля или набора полей) для данной записи. Выборка записи выполняется из адреса, вычисленного для требуемого значения ключа хэширования. Таким образом, вместо поискового перебора записей выполняется прямое обращение к нужному адресу памяти. Проблемой хэшированной организации являются возможные конфликты наложения записей.
В целом можно указать, что последовательная организация имеет простую реализацию, но низкое быстродействие для всех операций, кроме выборки при равной длине записей. Списковая и индексная организации связаны с более сложной реализацией, но обеспечивают высокое быстродействие для большинства операций.
17. Методы поиска в БД
Производительность программной системы во многом зависит от методов доступа к данным. Поэтому, если есть возможность выбора СУБД, знание используемых в ней алгоритмов работы с данными может быть полезным.
Простейший вариант поиска в таблице БД состоит в поиске (выборке) записи с заданным порядковым номером. При последовательном равномерном размещении записей выполняется быстрый поиск путем прямого вычисления местонахождения записи, при других вариантах организации размещения записей приходится использовать медленный последовательный поиск. Однако поиск по номеру записи не является для БД основным, а играет чаще вспомогательную техническую роль в других видах поиска. Характерным же для БД является поиск записи по содержанию информации, хранящейся в ней.
Рассмотрим методы поиска подходящей записи в БД по информации, содержащейся в некотором поле записи (поиск по ключу). Типичными являются следующие методы поиска:
1. Последовательный поиск:
Записи просматриваются последовательно, начиная с первой. Для каждой записи значение поля поиска сравнивается со значением ключа поиска. Окончание поиска – по соответствию значения поля искомому значению.
В целом, последовательный поиск имеет очень низкое быстродействие и применим только для небольших таблиц. К достоинствам поиска относятся простота выполнения и универсальность, основывающаяся на отсутствии необходимости в поддержке служебных данных, упорядочиваний и т.д.
Для ускорения поиска можно использовать упорядочивание по значению записей. Выигрыш - если при просмотре запись не нашлась, то часть таблицы, которая ниже нужной, не просматривается. Но при этом проигрываем в том, что необходимо поддерживать упорядоченность.
Можно упорядочить по важности информации. И если чаще нужна наиболее важная информация, то чаще всего поиск будет заканчиваться на наиболее важной информации.
Последовательный поиск используется в последовательной и списковой организации. Метод не применяется там, где необходим быстрый доступ к данным большого объема. Но его можно использовать в тех случаях, когда по характеру задачи следует выбирать записи последовательно (например, полное копирование данных), а также при очень небольших объемах данных в силу простоты алгоритма доступа.
Блочный поиск.
Записи разбиты на блоки, упорядочены по значению поля поиска. Выполняется последовательная проверка, но, в отличие от предыдущего метода, производится не сплошная, а выборочная проверка записей. Проверяются записи, выбираемые с принятым шагом (по числу записей, по размеру блока памяти). В итоге для проверяемого блока определяется возможность наличия записи. Если это так, то выполнется поиск внутри блока.
Данный вид поиска характерен для страничной организации памяти. При этом записи размещаются по страницам упорядоченно по ключу, и каждая проверка определяет наличие искомой записи в очередной проверяемой странице.
Бинарный поиск
Записи для применения поиска должны быть упорядочены по ключу. При каждой проверке проверяется центральная запись области поиска. В результате проверки либо обнаруживается искомая запись, либо из поиска исключается верхняя или нижняя половина области поиска. В оставшейся области снова проверяется центральная запись и так далее. Таким образом, в бинарном поиске реализуется алгоритм деления пополам.
Если записи имеют фиксированную длину, то смещаемся на нужную запись, если длина записей нефиксированная, то смотрим по меткам, то есть обращаемся в середину памяти и смещаемся далее до первой встретившейся метки.
Теоретически данный метод является самым быстрым, но реальная его эффективность снижается из-за потерь на обращение к внешнему носителю для считывания отдельных разрозненный записей.
Индексный поиск
Наиболее распространенный в БД метод поиска. В основе индексных методов доступа лежит создание вспомогательной структуры – индекса, содержащего ключи поиска и ссылки на физические адреса данных. Термин «ключ поиска» не обязательно подразумевает его уникальность, это просто атрибут (комбинация атрибутов), который должен удовлетворять критерию поиска. Индекс хранит описание логической последовательности записей по заданному ключу. Он представляет собой структуру, при обращении к которой входными данными является искомое значение ключа, а выходным – указатель на запись, содержащую это значение (или указание на отсутствие подходящей записи).
Требуемая упорядоченность по ключу поиска поддерживается индексом, в котором и проводится поиск. Доступ к данным производится в два этапа. Вначале в индексе (индексном файле) находятся требуемые значения ключей, затем из основного файла по ссылке извлекается требуемая информация. Производительность системы в целом может стать достаточно высокой. Для ее увеличения обычно требуют, чтобы индекс целиком размещался в оперативной памяти.
Факторами ускорения поиска являются:
- меньшее число проверок при выполнении поиска за счет упорядоченности данных в индексе;
- быстрая выборка проверяемой позиции индекса за счет небольшого объема индекса и выравненности размеров позиций;
- отсутствие необходимости расчета проверяемого значения для записей, т.к. в индексе хранятся уже рассчитанные значения.
Индексы могут быть устроены по-разному. Различаются первичные и вторичные индексы в зависимости от вида ключа поиска. Если поиск и выборка производится по комбинации атрибутов (индексному выражению), соответствующий индекс называется составным. Индекс, построенный на иерархии ссылок, называется многоуровневым. Индекс, который содержит ссылки не на все записи, а на некоторый диапазон, называется неплотным. Плотный индекс содержит ссылки на все записи. Элемент индекса часто называют статьей.
Существует множество индексных методов доступа. Внутренняя организация индекса может основываться на последовательной или списковой организации данных. Простейшей и сравнительно малоэффективной является последовательная организация. В этом случае в индексе хранятся упорядоченные по значению ключа пары «значение ключа – указатель на запись».

Недостаток такого индекса состоит в трудоемкости его модификации при добавлении, удалении, модификации контролируемых записей, что ограничивает область его применения в основном работой с постоянной и условно-постоянной информацией.
При списковой организации индекса он строится в виде дерева. В основном используются два вида деревьев: бинарные и В-деревья. Узел бинарного дерева содержит одно значение ключа и две ссылки на подчиненные узлы: левую – на код дерева с меньшими значениями ключа, правую – на код дерева с большими значениями.

Бинарное дерево характеризуется большой глубиной и несбалансированностью ветвей, что снижает эффективность поиска.
Например, заполнение дерева следующими значениями записей: 12, 35, 40, 100, 1, 2, 83, 5, 10, получим дерево, имеющее некоторые очень большие ветви, в то время как другие могут отсутствовать.
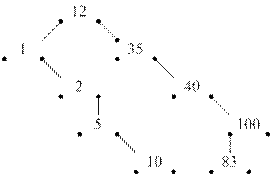
Реализация бинарного дерева позволяет сократить время поиска данных по сравнению с бинарным поиском, однако возрастает требуемый объем внешней памяти.
Более сложные в организации В-деревья обеспечивают малую глубину дерева за счет размещения оптимального числа ключей и ссылок в узлах и сбалансированность ветвей за счет специальных алгоритмов построения дерева.
Дата добавления: 2016-12-27; просмотров: 2072;
Поиск по сайту
Узнать еще
- II. Организация дезинфекционных и стерилизационных мероприятий в организациях, осуществляющих медицинскую деятельность
- II. Функционально-структурная организация и программное обеспечение персонального компьютера
- XXII. ОРГАНИЗАЦИЯ РАБОТ ПО ОБЕСПЫЛИВАНИЮ РУДНИЧНОГО ВОЗДУХА
- Автобусные маршруты и их организация
- Анатомическая организация мозга
- Базальные ганглии. Морфофункциональная организация. Функции
- Безопасная организация земляных работ
- Безопасная организация работ по очистке полосы отвода земли для строительства

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
