Управление транзакциями. Основные стратегии.
Для управления взаимодействием транзакций используются уровни изолированности. Изолированность – состояние работы, при котором пользователь не ощущает присутствия других лиц. Уровень изолированности определяет уровень, при котором в транзакции допускаются несогласованные данные, то есть степень изолированности одной транзакции от другой. Более высокий уровень изолированности повышает точность данных, но при этом может снижаться количество параллельно выполняемых транзакций. С другой стороны, более низкий уровень изолированности позволяет выполнять больше параллельных транзакций, но снижает точность данных.
Стандарт SQL-92 определяет следующие четыре уровня изоляции, установка которых предотвращает определенные конфликтные ситуации («+» – предотвращает, «–» – не предотвращает):
| Уровень | Запрет читать измененные данные | Запрет изменять прочитанные данные | Запрет добавления | Примечание |
| read uncommitted (чтение незафиксированных данных) | – | – | – | Низший уровень изоляции. Гарантирует только отсутствие потерянных обновлений. |
| read committed (чтение фиксированных данных) | + | – | – | Принятый по умолчанию уровень для Microsoft SQL Server. Отсутствует черновое, «грязное» чтение. Тем не менее в процессе работы одной транзакции другая может быть успешно завершена и сделанные ею изменения зафиксированы (не решена проблема неповторяемого чтения) |
| repeatable read (повторяемость чтения) | + | + | – | Уровень, при котором чтение одной и той же строки или строк в транзакции дает одинаковый результат |
| Serializable (упорядочиваемость) | + | + | + | Самый высокий уровень изолированности; транзакции полностью изолируются друг от друга |
Под сериализацией параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения.
Сериальный план выполнения смеси транзакций – это такой план, который приводит к сериализации транзакций. Если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций.
1) Последовательное исполнение: выполняется только одна транзакция, остальные ждут ее завершения. Приводит к большим задержкам времени ожидания. Для ускорения следует разрешить любую работу с различными данными и одновременное чтение одних и тех же данных;
2) Использование синхронизационных блокировок: транзакция при обращении к данным накладывает блокировку (захват). Обычно используется два типа блокировок: на чтение и на запись. Если транзакции требуются данные и они свободны, то выполняется работа с данными; если они заблокированы, проверяется возможность совместимости: при совместимости работаем с данными, при несовместимости – ожидаем их освобождения. Блокировки снимаются при завершении транзакции. Для поддержки захватов используется двухфазный протокол синхронизации (двухфазное блокирование).
- 1 фаза – транзакция захватывает данные по мере обращения к ним:
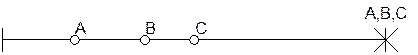
- 2 фаза – одновременное освобождение всех данных по завершению транзакции.
Основной недостаток: возможность взаимоблокировок (тупиков):
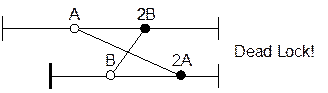
При наличии тупика (deadlock) ожидание будет бесконечным, поэтому необходимо нестандартное разрешение. Конфликты блокировок решаются следующими методами:
─ полуавтоматический вариант: при обнаружении конфликта посылается запрос пользователю. Пользователь принимает решение – продолжить ожидание или произвести откат транзакции;
─ автоматический вариант: при обнаружении конфликта после заданного времени ожидания выполняется автооткат транзакции, первой обнаружившей тупик;
─ анализ наличия тупика: автоматически определяется разрешимость конфликта, при этом используется граф ожидания, в котором указаны транзакции и обрабатываемые объекты. Если обнаруживается тупик, откатывается одна из транзакций.
Граф ожидания – инструмент, используемый при разработке СУБД и многопоточных систем и используемый, в частности, для определения ситуации взаимной блокировки. Представляет собой ориентированный двудольный граф, содержащий вершины двух типов:
─ вершины типа T, соответствующие транзакциям или выполняющимся потокам. Они образуют первую долю графа;
─ вершины типа R, соответствующие ресурсам и объектам, которые могут быть захвачены транзакциями. Они образуют вторую долю графа.
Дуги графа ожидания также имеют двоякий смысл:
─ дуги (T, R), идущие из вершины-транзакции T в вершину-ресурс R, обозначают, что данный ресурс уже захвачен транзакцией
─ дуги (R, T), идущие из вершины-ресурса R в вершину-транзакцию T обозначают, что транзакция T ожидает, пока ресурс R будет освобождён.
Простейшие свойства:
1. Ресурс, не имеющий ни одной входящей дуги, является свободным.
2. Если вершина-транзакция имеет некоторое ненулевое количество входящих дуг, то соответствующая транзакция находится в состоянии ожидания.
3. Если между двумя транзакциями T1 ® T2 существует путь, то транзакция T1 должна быть выполнена (завершена) раньше, чем начнётся выполнение T2, поскольку последняя требует освобождения некоторых ресурсов, захваченных транзакцией T1.
Из последнего свойства очевидным образом следует, что ситуации взаимной блокировки соответствует цикл на графе ожидания.
Для обнаружения цикла используется редукция графа. При этом поочередно выполняются два шага:
─ удаление дуг от неожидающих транзакций;
─ удаление дуг от свободных данных к транзакциям.
Если не удается удалить некоторый набор дуг, то это - цикл. Для разрешения тупика откатывается одна из транзакций.
3) Временные метки – транзакция при инициализации получает метку – это время начала. При обращении к данным, транзакция помечает его своей меткой. При обнаружении конфликта, метки сравниваются. Более молодая транзакция откатывается
При высоком уровне изолированности возникают большие затраты на ожидание. Для повышения быстродействия могут использоваться дополнительные возможности управления многопользовательским доступом:
─ многоуровневое блокирование: для записи, ячейки, массива записей, или всей таблицы (обычно при мелкой блокировке – много меток, при высокой – сразу блокируется большой кусок);
─ многоверсионная организация. Применена в InterBase.. Сущность её состоит в том, что все изменения, проводимые над конкретными записями, производятся не над самой записью, а над ее версией. Версия записи - это копия записи, которая создается при попытке ее изменить. Если какой-то транзакции нужно работать с какой-либо записью, транзакция обращается к последней зафиксированной версии записи;
─ использование оптимистического буферирования. При этом данные храниться в буфере до тех пор, пока принудительно не выполняется запись в базу. Различают пессимистическое (запись в БД при записи в буфер) и оптимистическое буферирование (запись выполняется после завершения транзакции, но потом проверяется - были ли изменения в данных. Если изменения были, то пользователь получает сообщение об этом.
15. Защита от несанкционированного доступа
Безопасность данных (data security) — концепция защиты программ и данных от случайного либо умышленного изменения, уничтожения, разглашения, а также несанкционированного использования.
Безопасность базы данных заключается в защите базы данных от несанкционированного доступа со стороны пользователей. Без привлечения соответствующих мер безопасности интегрированные в БД данные становятся более уязвимыми, чем данные в файловой системе. Однако интеграция позволяет определить требуемую систему безопасности базы данных, а СУБД привести ее в действие.
Защита данных от несанкционированного доступа предполагает:
─ предотвращение несанкционированного доступа к базе данных (обеспечение парольного входа в систему: регистрация пользователей, назначение и изменение паролей);
─ обеспечение защиты конкретных данных: определение прав доступа групп пользователей и отдельных пользователей, определение допустимых операций над данными для отдельных пользователей, выбор/создание программно-технологических средств защиты данных, шифрование информации в целях защиты данных от несанкционированного использования;
─ фиксация попыток несанкционированного доступа к информации;
─ аудит действий пользователей в базе данных;
─ исследование возникающих случаев нарушения защиты данных и проведение мероприятий по их предотвращению.
Безопасность базы данных можно разделить на две части:
1) Безопасность системы, которая охватывает доступ к базе данных на системном уровне. Безопасность системы включает в себя:
─ проверка правильности комбинации имени и пароля пользователя;
─ контроль системных операций, которые пользователю разрешено выполнять.
2) Безопасность данных включает механизмы, которые управляют доступом к объектам базы данных. Безопасность данных определяет:
─ к каким объектам базы данных имеет доступ пользователь;
─ какие действия пользователь может выполнять с объектами базы данных (извлечение, вставка, обновление, удаление).
Защита может выполняться на разных уровнях:

1. Защита от непосредственного доступа к базе данных.Применяются следующие методы:
1) Использование закрытого (сложного для чтения, уникального) формата данных.
2) Шифрование данных. Могут шифроваться как файлы целиком, так и отдельные поля.
Методика введения полного шифрования – шифрование в конце, расшифровка в начале программы.
Важнейшими характеристиками алгоритмов шифрования являются криптостойкость, длина ключа и скорость шифрования.
В криптографии обычно рассматриваются два типа криптографических алгоритмов. Это классические криптографические алгоритмы, основанные на использовании секретных ключей, и новые криптографические алгоритмы с открытым ключом, основанные на использовании ключей двух типов: секретного (закрытого) и открытого, так называемые двухключевые алгоритмы.
3) Самый популярный метод защиты – перенос базы на защищенный носитель (защищённый сервер).
Дата добавления: 2016-12-27; просмотров: 2401;
Поиск по сайту
Узнать еще
- Arthropoda.Систематика.Тараканы и мухи.Географическое распространение.Основные представители.Морфология,развитие,патогенное действие.Медицинское знаение.Меры борьбы.
- Cущность организации и ее основные признаки
- I. Назначение унифицированных газозарядных станций и основные тактико-технические требования, предъявляемые к ним.
- I. ОСНОВНЫЕ ПОЛОЖЕНИЯ
- I. Политический режим: понятие, сущность и основные типы.
- I.2. Основные категории водопотребления промышленных предприятий и их особенности
- II. Основные задачи ГО
- II. Основные задачи службы торговли и питания

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
