Последовательная организация.
Если отведенная память для СУБД – это логически связанная последовательность, то для файловой системы – это последовательность кластеров.
Последовательное распределение – простой и естественный способ хранения линейного списка. В этом случае узлы списка размещаются в последовательных элементах памяти.
Нужно иметь доступ к любой записи и обеспечить эффективность следующих операций с ними:
– чтение записи;
– модификация записи;
– удаление записи.
Длина записи может быть фиксированной или переменной.
а) Записи фиксированной длины
Записи размещаются последовательно непосредственно друг за другом. Вектор данных логически отделен от описания структуры хранимых данных. Например, если структура данных представляет собой линейный список (файл записей фиксированной длины), то описание структуры хранится в отдельной записи и содержит:
а) N – размер вектора данных, т.е. количество элементов списка записей;
б) т – размер элемента списка, т.е. размер записи, например, в байтах;
в) β – адрес базы, указывающий на начало вектора данных в памяти.

В этом случае адрес каждой записи можно вычислить с помощью адресной функции, отображающей логический индекс, идентифицирующий запись в структуре, в адрес физической памяти
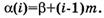
б) Записи имеют различную длину
При неравной длине записей для определения границ между записями требуются дополнительные средства. Это может быть хранение в записи адреса начала следующей записи или длины текущей записи, введение специальных меток начала (конца) записи.
При неравной длине записи выборка замедляется из-за необходимости последовательного перебора до нужной записи. Для повышения быстродействия в этом случае может использоваться искусственное выравнивание записей.

1) Хранение адреса следующей записи
2) Хранение длины следующей записи
3) Выравнивание записей.
Добавление записи при последовательной организации трудоемко из-за необходимости перемещения всех записей, следующих за добавляемой, для освобождения места под новую запись. Поэтому прямая вставка не эффективна, рекомендуется добавление в конец.
При страничной организации для улучшения характеристик применяют неполное заполнение страниц, что позволяет локализовать перемещение записей одной страницей.
Аналогичные трудности возникают при операции удаления, когда записи перемещаются для заполнения освободившегося места. Здесь для повышения быстродействия и для избавления от массовой перезаписи файла часто используется пометка записей на удаление без немедленного сжатия данных. При этом разделяют физическое и логическое удаление (например, в Visual Fox Pro: PACK – физическое удаление, DELETE – логическое удаление. Физическое удаление предполагает монопольный режим и выполняется медленно, поэтому вызывается редко).
Модификация записи при равной длине выполняется просто, но при неравной длине записей снова могут возникать проблемы, связанные с необходимостью перезаписи больших объемов данных. При записях одинаковой длины, просто добавляется в пустое место или в конец, иначе при записях неодинаковой длины – запись в конец.
Для повышения эффективности доступа применяют также выравнивание записей. Для этого существует два метода:
1) Выполняется поиск записи максимальной длины, выполняется расширение до этого размера (плюс некоторый запас) всех строк. Используется: когда разброс длин невелик и длина небольшая. (VARCHAR – строка переменной длины).
2) Невыравненные части записей выносятся в отдельное хранение. Используется при большом разбросе длин записей (Например, в VisualFoxPro используется описание "memo", в InterBase – "blob", указатель занимает 4 байта).
Списковое хранение
Связанное представление линейного списка называется связанным списком. При связанном распределении памяти для построения структуры необходимо задать отношения следования и предшествования элементов с помощью указателей. Указателями служат адреса, хранимые в записях данных. В отличие от последовательного распределения памяти, при котором с помощью адресной функции вычисляется адрес следующего элемента, при связанном распределении памяти значение адресной функции можно получить только путем просмотра хранящихся указателей. Такой метод распределения памяти позволяет расширить либо сократить структуру без перемещения самих данных в памяти ЭВМ, однако при этом требуется больше памяти для хранения структуры по сравнению с последовательным распределением.
Связанное распределение – более сложный, но и более гибкий способ хранения линейного списка. Каждый узел содержит указатель на следующий узел списка, т.е. адрес следующего узла списка. При связанном распределении не требуется, чтобы список хранился в последовательных элементах памяти. Наличие адресов связи в данном способе хранения позволяет размещать узлы списка произвольно в любом свободном участке памяти. При этом линейная структура списка обеспечивается указателями.
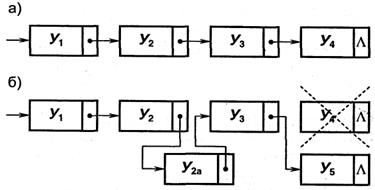
Примеры связанных линейных списков:
а) однонаправленный список; б) тот же список после удаления узла 4 и включения узлов 2а и 5
Свободное размещение записей, связанных указателями, затрудняет выборку нужной записи из-за необходимости последовательного перемещения по указателям до нужного места. Для операций же добавления, удаления и модификации записи списковая организация обеспечивает высокое быстродействие, т.к. обработке подвергаются только обрабатываемая запись и связанные с ней указатели в смежных записях.
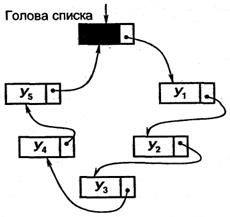
Для повышения эффективности и возможности перемещения по списку в обоих направлениях используется двунаправленный список.
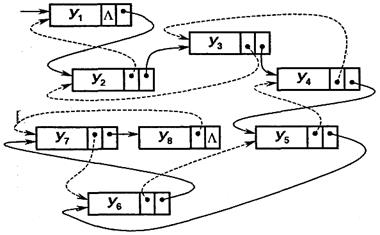
Важной разновидностью представления в памяти линейного списка является циклический список.Циклически связанный линейный список обладает той особенностью, что связь от последнего узла идет к первому узлу списка. Циклический список позволяет получить доступ к любому узлу списка, отправляясь от любого заданного узла. Циклические списки называются также кольцевыми структурами или кольцами.
Однонаправленный циклический список
Использование списковой организации приводит к необходимости решать дополнительную задачу управления свободной памятью, которая по мере работы с записями динамично меняет свой размер и подвергается все большей фрагментации (разбросана мелкими кусками по всей базе). Для учета свободных мест в отведенной области используются два основных подхода:
1) Пометка свободных позиций специальным кодом. Недостаток – потеря времени на поиск достаточного свободного места для размещения новой записи.

2) Ведения списка пустых (свободных) блоков, связанных аналогично записям указателями, для соединения их в одну последовательность. В каждой пустой записи хранится указатель на следующий блок и длина этого свободного блока.
Дата добавления: 2016-12-27; просмотров: 1927;
Поиск по сайту
Узнать еще
- А. Последовательная ООС по току
- Базальные ганглии. Морфофункциональная организация. Функции
- В. Последовательная ООС по напряжению
- Гипоталамус. Морфофункциональная организация. Функции
- Двухпроводная последовательная шина данных
- Конструкция формы, как ее пространственная организация.
- Основы организации пассажирских перевозок. Транспортная подвижность населения. Автобусные маршруты и их организация.
- Параллельная и последовательная работа двух центробежных насосов

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
