Оператор фиксации результатов работы с БД
COMMIT;
Данный оператор фиксирует результаты выполнения предшествующих операторов.
12. Выборка данных в SQL
ОПЕРАТОР ВЫБОРКИ SELECT
Оператор выборки SELECT предназначен для описания и исполнения запросов к БД на выборку данных. Он является наиболее проработанным и идеологически важным оператором языка SQL. Основная форма оператора имеет вид:
SELECT <поля выборки>
FROM <таблицы>
WHERE <условия отбора записей>
GROUP BY <поля группирования>
HAVING <условия отбора группы>
Оператор описывает:
- откуда брать данные,
- каким требованиям должна удовлетворять отобранная информация,
- в каком виде представить результаты выборки.
Таким образом, в операторе SELECT определяется, «что должно быть получено», а не «как это получить», что показывает связь оператора SELECT с реляционным исчислением. Дополнительно оператор SELECT включает нереляционные операции.
Исполнение оператора SELECT можно представить последовательностью действий:
1) Формирование единой таблицы:
Формирование выполняется в соответствии с информацией, заданной фразой FROM. Во фразе FROM перечисляются через запятую входные элементы. Элементом может быть исходная таблица или соединение исходных таблиц.
Соединение таблиц задается в виде:
<таблица1> <вид соединения> JOIN <таблица2> ON <условие>
Вид соединения может принимать значения:
INNER – внутреннее соединение: содержит все соединения записей, для которых выполняется заданное условие
LEFT – левое внешнее соединение: к допустимым соединениям записей добавляются соединения с пустой строкой для записей таблицы 1, не имеющих соответствия в таблице 2. Таким образом, в таблицу соединения хотя бы однократно входят все записи таблицы 1 (левой таблицы соединения)
RIGHT – правое внешнее соединение: к допустимым соединениям записей добавляются соединения с пустой строкой для записей таблицы 2, не имеющих соответствия в таблице 1.
FULL – полное внешнее соединение: в результат соединения включаются все записи как левой, так и правой таблицы соединения.
После формирования соединений общая таблица образуется декартовым произведением полученных табличных элементов. Декартово произведение также образуется соединениями строк, но допустимыми являются все сочетания.
Пример:
Таблица «А_сотрудники» содержит сведения о сотрудниках фирмы X:
| Таб_ном | ФИО |
| 01 | Диго |
| 02 | Афанасьев |
| 03 | Сидоров |
Таблица «Б_разработки» содержит информацию о том, какие программные продукты разработаны в фирме X и кто является автором каждой разработки.
| ФИО | Продукт |
| Диго | П1 |
| Диго | П2 |
| Афанасьев | П3 |
| Чистов | П4 |
Если в предложении FROM перечислено несколько таблиц, то все они неявно считаются соединяемыми. Если тип соединения явно не задан, то считается, что каждая строка первой таблицы соединяется с каждой строкой второй таблицы. Такое соединение и называется перекрестным.
Результат перекрестного соединения для приведенных выше таблиц представлен ниже.
| Таб_ном | А_сотрудники.фио | Б_разработки.фио | Продукт |
| 01 | Диго | Диго | П1 |
| 01 | Диго | Диго | П2 |
| 01 | Диго | Афанасьев | ПЗ |
| 01 | Диго | Чистов | П4 |
| 02 | Афанасьев | Диго | П1 |
| 02 | Афанасьев | Диго | П2 |
| 02 | Афанасьев | Афанасьев | ПЗ |
| 02 | Афанасьев | Чистов | П4 |
| 03 | Сидоров | Диго | Ш |
| 03 | Сидоров | Диго | П2 |
| 03 | Сидоров | Афанасьев | ПЗ |
| 03 | Сидоров | Чистов | П4 |
Запрос на SQL может иметь следующий вид:
SELECT а_сотрудники.таб_ном, а_сотрудники.фио, б_разработки.фио, б_разработки.продукт
FROM а_сотрудники, б_разработки;
Чаще всего при создании запросов используется тип соединения INNER JOIN, при котором соединенная таблица будет включать только те строки, для которых есть соответствующие друг другу значения полей связи в обеих таблицах.
Результат соединения типа INNER JOIN для приведенных выше таблиц представлен ниже.
| Таб_ном | ФИО | Продукт |
| 01 | Диго | П2 |
| 01 | Диго | П1 |
| 02 | Афанасьев | ПЗ |
Этот запрос показывает разработки, выполненные сотрудниками фирмы X.
На SQL такой запрос будет иметь следующий вид:
SELECT а_сотрудники.таб_ном, а_сотрудники.фио, б_разработки.продукт
FROM а_сотрудники INNER JOIN б_разработки
ON а_сотрудники.фио = б_разработки.фио;
При использовании соединения типа LEFT JOIN в результатную таблицу попадают все записи из первой таблицы и только те записи из второй таблицы, для которых есть соответствующие значения полей связи в первой таблице. Соединение типа LEFT JOIN для рассматриваемого примера даст в результате список всех сотрудников фирмы X с указанием их разработок:
| Таб_ном | ФИО | Продукт |
| 01 | Диго | П2 |
| 01 | Диго | П1 |
| 02 | Афанасьев | ПЗ |
| 03 | Сидоров | Null |
На SQL такой запрос будет выглядеть следующим образом:
SELECT а_сотрудники.таб_ном, а_сотрудники.фио, б_разработки.продукт
FROM а_сотрудники LEFT JOINб_разработки
ON а_сотрудники.фио = б_разработки.фио;
При использовании соединения типа RIGHT JOIN, напротив, в результатную таблицу попадают все записи из второй таблицы и только те записи из первой таблицы, для которых есть соответствующие значения полей связи во второй таблице. Соединение типа RIGHT JOIN для рассматриваемого примера даст в результате список всех продуктов с указанием разработчика и его табельного номера:
| Таб_ном | ФИО | Продукт |
| 01 | Диго | П1 |
| 01 | Диго | П2 |
| 02 | Афанасьев | ПЗ |
| Null | Чистов | П4 |
На SQL такой запрос будет выглядеть следующим образом:
SELECT а_сотрудники.таб_ном, б_разработки.фио, б_разработки.продукт
FROM а_сотрудники RIGHT JOIN б_разработки
ON а_сотрудники.фио = б_разработки.фио;
Во всех приведенных выше примерах предполагалось, что условием соединения является равенство значений полей связи. Обычно именно этот тип сравнения и используется.
FULL JOIN для нашего примера даст следующий результат:
| Таб_ном | ФИО | Продукт |
| 01 | Диго | П1 |
| 01 | Диго | П2 |
| 02 | Афанасьев | ПЗ |
| 03 | Сидоров | Null |
| Null | Чистов | П4 |
2) Ограничение единой таблицы по строкам:
Данная операция выполняется при наличии фразы WHERE, которая содержит условие ограничения.
Условие проверяется для каждой записи единой таблицы. При невыполнении условия запись исключается из единой таблицы. Условие выборки включает одно или несколько простых условий. При наличии нескольких простых условий они объединяются в условие ограничения с помощью логических функций AND и OR.
Простые условия могут иметь следующие формы:
· <поле> <сравнение> <выражение>
Выполняется сравнение значения поля со значением выражения. Для задания вида сравнения используются символы < > = и их сочетания. Сравнение «не равно» может быть задано в виде != или <>.
· <поле> IS NULL
· <поле> IS NOT NULL
Выполняется проверка отсутствия или наличия значения поля.
Например, если в таблице «Сотрудник» (sotr) есть поле «Ученая_степень» (ych_st), то запрос, выводящий список сотрудников, не имеющих ученых степеней, будет выглядеть следующим образом:
SELECT fio FROM sotr WHERE ych_st IS NULL;
· <поле> BETWEEN <выражение> AND <выражение>
· <поле> NOT BETWEEN <выражение> AND <выражение>
Выполняется проверка попадания значения поля в заданный интервал или вне интервала.
· <поле> IN (<список>)
· <поле> NOT IN (<список>)
Выполняется проверка наличия или отсутствия значения поля в заданном наборе значений. Набор значений может быть создан запросом SELECT, т.е. условие может иметь форму: <поле> IN (оператор SELECT).
· EXISTS (оператор SELECT)
· NOT EXISTS (оператор SELECT)
Выполняется проверка наличия или отсутствия записей в выборке, выполненной с использованием данных проверяемой записи.
· <поле> <сравнение> ALL (оператор SELECT)
Выполняется проверка выполнения условия сравнения для каждого элемента набора, созданного запросом SELECT.
· <поле> <сравнение> ANY (оператор SELECT)
Выполняется проверка выполнения условия сравнения хотя бы для одного элемента набора, созданного запросом SELECT.
В выражении, использующемся для сравнения, разрешается применять заполнители (трафаретные символы):
· символ подчеркивания (_) - используется вместо любого единичного символа в проверяемом значении;
· символ процента (%) - заменяет набор любых символов в проверяемом значении.
Предположим, что коды металлов начинаются с буквы «м». Тогда запрос, позволяющий вывести сведения о поставке металлов, будет иметь вид
SELECT * FROM post WHERE kod_mat LIKE "м%";
3) Отбор выходных столбцов выборки:
Во фразе SELECT перечисляются через запятую выходные элементы. Выходным элементом может быть поле таблицы, задаваемое именем, или вычисляемое поле, задаваемое выражением.
Для уточнения ссылки на поле может быть указан псевдоним его таблицы в виде:
<псевдоним>.<поле>.
Псевдоним - имена, которые станут заголовками столбцов вместо исходных названий столбцов в таблице
Для элемента может быть задан псевдоним в виде:
<элемент> AS <псевдоним>.
Задание псевдонима позволяет присвоить имена вычисляемым полям, разрешить конфликты совпадения имен и определить понятный пользователю заголовок.
Кроме задания выходного списка фраза SELECT может содержать необязательные опции, ограничивающие дублирование выходных строк выборки. Ограничение повтора может принимать значения:
- ALL – повторяющиеся записи включаются в выборку (значение по умолчанию);
- DISTINCT – повторяющиеся записи не включаются в выборку.
Примечание: символ * задает включение всех имеющихся столбцов в выходной список без необходимости полного перечисления.
4) Группирование строк таблицы выборки:
Фраза GROUP BY содержит список полей, по которым выполняется группировка. Группирование используется для определения групп выходных строк, к которым могут применяться те или иные агрегатные функции. Предложение GROUP BY обычно используется со встроенными агрегатными функциями. Если агрегатные функции используются без предложения GROUP BY, то они будут применяться ко всему набору строк, удовлетворяющему условию запроса.
Поле группировки может быть задано именем или порядковым номером в выходном списке. Для группы формируется итоговая запись, в полях которой размещается агрегированная по группе информация.
Агрегирование данных выполняется с помощью функций:
· COUNT(<выражение>) – количество записей в группе;
· SUM(<выражение>) – суммарное значение выражения по записям группы;
· MIN(<выражение>) – минимальное значение выражения по записям группы;
· MAX(<выражение>) – максимальное значение выражения по записям группы;
· AVG(<выражение>) – среднее значение выражения по записям группы.
При использовании группировки выходной список должен содержать только элементы, имеющие постоянное значение внутри группы (например, поля группировки) или являющиеся агрегированными функциями.
Например, в таблице «Zarpl», содержащей сведения о заработной плате рабочих, имеются колонки FIO (фамилия, инициалы), «ТаbNum» (табельный номер), «Uch» (участок), «Zpl» (заработная плата). Требуется определить среднюю заработную плату по каждому участку:
SELECT uch, AVG(zpl)
FROM zarple
GROUP BY uch;
В данном примере рассматривается группировка по одной колонке. В принципе можно группировать строки таблицы по любой комбинации ее колонок. В этом случае имена колонок в предложении GROUP BY перечисляются через запятую.
5) Ограничение по групповым строкам:
Данная операция выполняется при наличии фразы HAVING. Она задает условие ограничения для групповых строк аналогично тому, как фраза WHERE задает условие ограничения для исходных строк. Обычно используется вместе с фразой GROUP BY.
Например, запрос на выдачу списка кодов тех материалов, по которым было выполнено более чем по одной поставке, будет выглядеть следующим образом:
SELECT codmat
FROM post
GROOUP BY codmat
HAVING COUNT(*)>1;
Выражение во фразе HAVING должно принимать единственное значение для группы. Формат COUNT(*) означает подсчет всех строк таблицы.
6) Объединение выборки:
Данная операция выполняется при наличии фразы UNION.
Объединяет результаты двух или более запросов в один результирующий набор, в который входят все строки, принадлежащие всем запросам в объединении. Основные правила объединения результирующих наборов нескольких запросов с помощью операции UNION:
- Количество и порядок столбцов должны быть одинаковыми во всех запросах.
- Типы данных должны быть совместимыми.
Операция UNION указывает на то, что несколько результирующих наборов следует объединить и возвратить в виде единого результирующего набора.
Пример:
SELECT ProductModelID, Name
FROM Production
UNION
SELECT ProductModelID, Name
FROM Gloves;
7) Упорядочивание записей выборки:
Данная операция выполняется при наличии фразы ORDER BY.
Она содержит список полей, по которым выполняется упорядочивание. Каждое поле упорядочивания должно присутствовать в выходном списке.
Порядок сортировки определяется порядком следования полей в списке упорядочивания. Сначала выполняется сортировка по первому полю списка, затем внутри каждой сортировочной группы – по второму полю и т.д.
После каждого поля можно указать направление сортировки по этому полю.
Допустимыми значениями указателя сортировки являются ASC (по возрастанию) и DESC (по убыванию).
При использовании фразы UNION упорядочивание может быть задано только однократно. Фраза ORDER BY в этом случае размещается в самом конце и относится ко всему объединению.
Например, следующая инструкция позволяет получить список лучших студентов выпуска 2002 г., средний балл которых больше 4,5:
SELECT Имя, Фамилия
FROM Студенты
WHERE ГодВыпуска =2002
AND СреднийБалл>4.5
ORDER BY СреднийБалл DESC;
13. Восстановление данных
Одним из основных требований к развитым СУБД является надежность хранения баз данных. Это требование предполагает, в частности, возможность восстановления согласованного состояния базы данных после любого рода аппаратных и программных сбоев. Очевидно, что для выполнения восстановлений необходима некоторая дополнительная информация. В подавляющем большинстве современных реляционных СУБД такая избыточная дополнительная информация поддерживается в виде журнала изменений базы данных.
Поскольку основой поддержания целостного состояния базы данных является механизм транзакций, журнализация и восстановление тесно связаны с понятием транзакции.
Средства восстановления не стандартизированы и являются специфичными для разных СУБД. В целом обобщенная схема восстановления имеет вид:
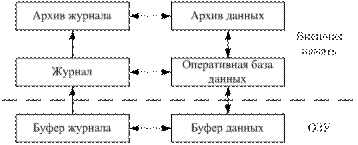
Буфер данных – для временного хранения обрабатываемых данных. Данные записываются в буфер, который находится в ОЗУ. Он может быть как на стороне сервера, так и клиента.
Буфер журнала (операций или транзакций) – для буферирования текущей информации по операциям изменения.
Оперативная база данных – база данных, с которой выполняется работа.
Журнал – хранит историю операций с данными.
Архив данных – хранятся резервные копии оперативной базы данных.
Архив журнала – хранятся сведения об операциях, не требующих оперативной работы.
НОРМАЛЬНЫЙ РЕЖИМ
В нормальном режиме работы с клиентских мест поступают обращения к СУБД, нужные данные загружаются в буфер данных, при выполнении операций с данными действия фиксируются с помощью буфера журнала. Эти действия могут регистрироваться различными способами. Самый простой – записываются все операции. При этом возможно отменять действия. Другой способ – расставляют метки об удалении, тогда при необходимости можно будет восстановить эти записи. При подтверждении изменений делается новая копия, затем удаляются записи, помеченные для удаления.
По ходу работы информация из буферов переносится на диск. Основные ситуации:
1) Буфер данных переписывается на диск при заполнении буфера.
2) Буфер журнала перезаписывается:
- по переполнению буфера.
- по завершению транзакций.
- перед перезаписью данных из буфера данных. Обеспечивается протоколом WAL (Write-Ahead Logging). Данное упреждающее журнализирование является ключевым методом обеспечения требований физической целостности данных. WAL позволяет обеспечить сброс на диск записей из журнала транзакций, относящихся к изменениям данных, раньше того, как будут сброшены на диск сами эти изменённые страницы данных. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя/
Для последующего восстановления используются архивы данных и журнала. Архивация данных может быть по заданным событиям или по явной команде пользователя. При этом копируется вся база или её часть.
В итоге: есть база данных, с которой работаем. Чтобы её не потерять, делается её копия, функция полного копирования обычно есть во всех СУБД. Но эта операция требует монопольного режима работы. Создаваемая копия может быть в другом формате, отличном от формата исходной базы данных. Резервная копия обычно не копирует записи, помеченные на удаление. Копирование может вестись по какому-то событию. Резервное копирование может также позволить перейти в более высокую версию СУБД.
Архивация в архив журнала обычно выполняется для сокращения оперативной части журнала. Архивация выполняется в рабочем режиме. Для этого журнал делится на два блока – один для записи данных из буфера журнала, второй для архивации. После выполнения архивации выполняется смена частей местами. В некоторых системах есть больше частей, это позволяет сгладить пиковые режимы (когда данные не успевают архивироватся). При отсутствии архива журнала реализуется освобождение журнала через архивацию данных, тогда журнал стирается при архивации данных.
СБОЙНЫЕ СИТУАЦИИ
Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных:
- Индивидуальный откат транзакции. Тривиальной ситуацией отката транзакции является ее явное завершение оператором ROLLBACK. Возможны также ситуации, когда откат транзакции инициируется системой (возникновение исключительных ситуаций в прикладной программе, например, деление на ноль). Для восстановления согласованного состояния базы данных при индивидуальном откате транзакции нужно устранить последствия операторов модификации базы данных, которые выполнялись в этой транзакции.
- Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой). Такая ситуация может возникнуть при аварийном выключении электрического питания, при возникновении неустранимого сбоя процессора (например, срабатывании контроля оперативной памяти) и т.д. Ситуация характеризуется потерей той части базы данных, которая к моменту сбоя содержалась в буферах оперативной памяти.
- Восстановление после поломки основного внешнего носителя базы данных (жесткий сбой). Эта ситуация при достаточно высокой надежности современных устройств внешней памяти может возникать сравнительно редко, но тем не менее, СУБД должна быть в состоянии восстановить базу данных даже и в этом случае. Основой восстановления является архивная копия и журнал изменений базы данных.
Соответственно трём вариантам сбойных ситуаций существуют три основных вида восстановления:
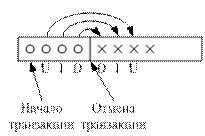
1) Восстановление одиночной транзакции.
Для отката транзакции используется буфер журнала и журнал. Для восстановления выполненные операции просматриваются в обратном порядке и выполняются инверсные действия. Например, вместо операции INSERT выполняется соответствующая операция DELETE, вместо DELETE - INSERT, вместо UPDATE - обратная операция UPDATE, восстанавливающая предыдущее состояние объекта базы данных. Любая из этих обратных операций также журнализируется.
2) Восстановление после мягкого сбоя (теряются данные в ОЗУ).
Для восстановления используется журнал. Будем считать, что в журнале отмечаются точки физической согласованности базы данных - моменты времени, в которые во внешней памяти содержатся согласованные результаты операций, завершившихся до соответствующего момента времени, и отсутствуют результаты операций, которые не завершились, а буфер журнала вытолкнут во внешнюю память. Тогда к моменту мягкого сбоя возможны следующие состояния транзакций:
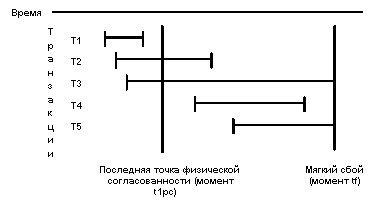
Предположим, что некоторым способом удалось восстановить внешнюю память базы данных к состоянию на момент времени tlpc. Тогда:
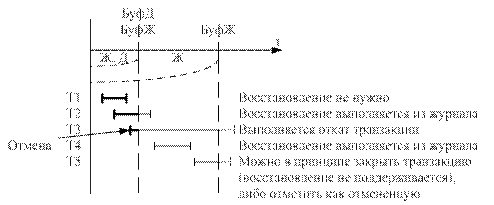
- Для транзакции T1 никаких действий производить не требуется. Она закончилась до момента tlpc, и все ее результаты отражены во внешней памяти базы данных.
- Для транзакции T2 нужно повторно выполнить оставшуюся часть операций, поскольку во внешней памяти полностью отсутствуют следы операций, которые выполнялись после момента tlpc, но в журнале содержатся записи обо всех изменениях, произведенных этой транзакцией до момента мягкого сбоя.
- Для транзакции T3 нужно выполнить в обратном направлении первую часть операций, поскольку во внешней памяти базы данных полностью отсутствуют результаты операций, которые были выполнены после момента tlpc, но гарантированно присутствуют результаты операций T3, которые были выполнены до этого момента. Следовательно, обратная интерпретация операций T3 приведет к согласованному состоянию базы данных (поскольку транзакция T3 не завершилась к моменту мягкого сбоя, при восстановлении необходимо устранить все последствия ее выполнения).
- Для транзакции T4, которая успела начаться после момента tlpc и закончиться до момента мягкого сбоя, нужно выполнить полную повторную прямую интерпретацию операций.
- Наконец, для начавшейся после момента tlpc и не успевшей завершиться к моменту мягкого сбоя транзакции T5 никаких действий предпринимать не требуется. Результаты операций этой транзакции полностью отсутствуют во внешней памяти базы данных.
Рассмотренные варианты можно графически представить следующим образом:
3) Восстановление после жесткого сбоя (теряется база данных на диске).
Основой восстановления в этом случае являются журнал и архивная копия базы данных.
Восстановление начинается с обратного копирования базы данных из архивной копии. Затем для всех закончившихся транзакций операции повторно выполняются в прямом смысле, в соответствии с архивом журнала. Если есть журнал, то выполняются операции по журналу. Для транзакций, которые не закончились к моменту сбоя, выполняется откат.

Для успешного восстановления данных необходимо хранение блоков на разных носителях, причем журналы желательно хранить на съемных дисках.
Данная схема восстановления реализуется в разном объеме, в зависимости от функциональности СУБД:
1) восстановление невозможно, если СУБД этого не поддерживает (отсутствуют архивы данных, буфер журнала, журнал и архив журнала):
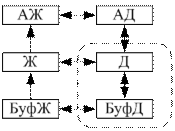
2) система поддерживает создание резервных копий:
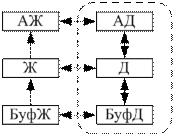
Простая система, вести журналов не нужно. Но создание архивных копий требует много времени.
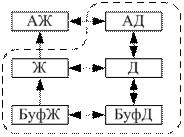
3) практически полная система восстановления:
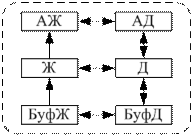
4) полная реализация:
Как часто требуется производить архивные копии базы данных? Самый простой способ - архивировать базу данных при переполнении журнала. В журнале вводится так называемая "желтая зона", при достижении которой образование новых транзакций временно блокируется. Когда все транзакции закончатся, и, следовательно, база данных придет в согласованное состояние, можно производить ее архивацию, после чего начинать заполнять журнал заново.
ДОПОЛНИТЕЛЬНЫЕ СРЕДСТВА ВОССТАНОВЛЕНИЯ:
1) Зеркалирование – параллельно пишется зеркальная копия базы. Основная база – на основном диске, но то же самое одновременно пишется на второй, дополнительный диск. Достоинство – быстрое восстановление, недостаток – невозможность выполнения откатов.
2) Аппаратное резервирование, например, с использованием RAID-массивов. Это массив из нескольких дисков (запоминающих устройств), управляемых контроллером, связанных между собой скоростными каналами передачи данных и воспринимаемых внешней системой как единое целое. В зависимости от типа используемого массива может обеспечивать различные степени отказоустойчивости и быстродействия. Служит для повышения надёжности хранения данных и/или для повышения скорости чтения/записи.
14. Организация многопользовательского доступа
В многопользовательской среде с одними и теми же записями могут одновременно работать несколько человек. Поскольку в то время, когда один пользователь пытается редактировать записи, другие пользователи также могут вносить в них изменения или даже удалять данные, при работе иногда возникают противоречия и потеря целостности.
Возможными путями устранения противоречий являются:
1. Организация параллельного доступа.
2. Разделение прав доступа. Разные пользователю обладают различными правами (только чтение, чтение/запись, возможность доступа к разным уровням данным…).
Ниже будет рассмотрена возможность организация параллельного доступа к БД.
При соединении потоков транзакций от разных пользователей могут возникнуть следующие проблемы, приводящие к искажению данных:
1) потерянное обновление — при одновременном изменении одного блока данных разными транзакциями, одно из изменений теряется;
| Т1 | Т2 | Состояние |
| ЧтА | А0 | |
| ЧтА | А0 | |
| ИзмА | А1 | |
| ИзмА | А2 | |
| [откат] | [А0] | |
| ЧтА | А2 [А0] |
Первая и вторая транзакции прочитали текущее состояние поля. Первая транзакция сделала свои изменения, основываясь на своих сохраненных в память данных. Вторая транзакция также делает обновление поля, используя свои "старые" данные или же производит "откат" транзакции. Последующее чтение первой транзакцией выявляет "ошибочные" для неё данные.
Решение – запрет изменения данных, измененных другой транзакцией, до завершения этой транзакции.
2) «грязное чтение» — чтение данных, добавленных или изменённых транзакцией, которая впоследствии не подтвердится (откатится). Либо – чтение второй транзакцией данных, которые могут быть лишь промежуточными (неокончательными).
Пример: обрабатываются A и B – связанные данные (они могут быть получены в результате некоторого вычислительного алгоритма)
| Т1 | Т2 | Состояние |
| ЧтА | А0 B0 | |
| ЧтВ | B0 A0 | |
| ИзмА | А1 B0 – грязные данные | |
| ЧтА | A1 B0 | |
| ЧтВ | A1 B0 | |
| ИзмВ | A1 B1 |
В результате вторая транзакция прочитала неверные (несвязанные) данные.
Также возможен такой вариант: в транзакции 1 изменяется значение поля f2, а затем в транзакции 2 выбирается значение этого же поля. После этого происходит откат транзакции 1. В результате значение поля f2, полученное второй транзакцией, будет отличаться от значения, хранимого в базе данных.
Решение – запрет чтения данных, изменяемых другой транзакцией, до завершения последней.
3) неповторяющееся чтение — ситуация, когда при повторном чтении в рамках одной транзакции, ранее прочитанные данные оказываются изменёнными
| Т1 | Т2 | Состояние |
| ЧтА | A0 | |
| ЧтА | A0 | |
| ИзмА | A1 | |
| ЧтА | A1 |
В транзакции 1 выбирается значение поля А, затем в транзакции 2 изменяется значение этого же поля. При повторной попытке выбора значения из поля А в транзакции 1 будет получен другой результат. Эта ситуация особенно неприемлема, когда данные считываются с целью их частичного изменения и обратной записи в базу данных.
В результате имеем нарушение изолированности.
Решение – запрет изменения данных, читаемых другой транзакцией, до завершения транзакции:
4) фантомное чтение — Одна транзакция в ходе своего выполнения несколько раз выбирает множество строк по одним и тем же критериям. Другая транзакция в интервалах между этими выборками добавляет или удаляет строки и успешно заканчивается. В результате получится, что одни и те же выборки в первой транзакции дают разные множества строк. Такая ситуация называется фантомным чтением. От неповторяющегося чтения оно отличается тем, что результат повторного обращения к данным изменился не из-за изменения самих этих данных, а из-за появления новых (фантомных) данных или из-за удаления строк данных.
Исходные данные – набор данных {A}
| Т1 | Т2 |
| Чт {А} | |
| Доб. в {A} | |
| Чт {А} |
Решение: запрещать добавление записей до завершения другой транзакции.
Дата добавления: 2016-12-27; просмотров: 1674;
Поиск по сайту
Узнать еще
- C учетом изменения статической работы балки
- I. Обработка результатов журнала технического нивелирования.
- I. Режимы работы электротехнических устройств.
- II. Прием и оформление заказов на услуги (работы)
- II. Принцип действия и режимы работы синхронной машины
- JK-тpиггеp типа MS: особенности работы, схемная реализация.
- А). Условия подобия режимов работы ГТД
- А. Программирование работы гирлянды, работающей в режиме бегущей волны

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
