Тема 11: АДАПТИВНАЯ ФИЛЬТРАЦИЯ ДАННЫХ
Пусть они постараются подчинить себе обстоятельства, а не подчиняются им сами.
Гораций. Послания.
(................)
Если в этой теории Вы не увидите смысла, тем лучше. Можно пропустить объяснения и сразу приступить к ее практическому использованию.
Валентин Ровинский. Теория карточных игр.
(Киевский геофизик Уральской школы).
Содержание: 11.1. Введение. 11.2. Основы статистической группировки информации. Предпосылки метода. Задача статистической группировки. Использование априорных данных. Эффективность метода. 11.3. Статистическая регуляризация данных. Проверка теоретических положений метода. Оценка СРД. Результаты моделирования. 11.4. Статистическая группировка полезной информации. Сущность аппаратной реализации. Реализация систем СГПИ. Пример технического исполнения системы СГПИ. Литература.
11.1. Введение.
В традиционных методах обработки данных информация извлекается из входных сигналов линейными системами с постоянными параметрами алгоритмов преобразования данных. Системы могут иметь как конечную, так и бесконечную импульсную характеристику, но передаточная функция систем не зависит от параметров входных сигналов и их изменения во времени.
Адаптивные устройства обработки данных отличаются наличием определенной связи параметров передаточной функции с параметрами входных, выходных, ожидаемых, прогнозируемых и прочих дополнительных сигналов или с параметрами их статистических соотношений. В простейшем случае, адаптивное устройство содержит программируемый фильтр обработки данных и блок (алгоритм) адаптации, который на основании определенной программы анализа входных, выходных и прочих дополнительных данных вырабатывает сигнал управления параметрами программируемого фильтра. Импульсная характеристика адаптивных систем также может иметь как конечный, так и бесконечный характер.
Как правило, адаптивные устройства выполняются узко целевого функционального назначения под определенные типы сигналов. Внутренняя структура адаптивных систем и алгоритм адаптации практически полностью регламентируются функциональным назначением и определенным минимальным объемом исходной априорной информации о характере входных данных и их статистических и информационных параметрах. Это порождает многообразие подходов при разработке систем, существенно затрудняет их классификацию и разработку общих теоретических положений /л38/.
С учетом последнего принцип построения адаптивных систем рассмотрим на конкретном примере – системе адаптивной фильтрации данных непрерывных ядерногеофизических измерений.
11.2. Основы статистической группировки информации.
Предпосылки метода.Физической величиной, регистрируемой в процессе ядерно-физических измерений в геофизике, обычно является частота импульсных сигналов на выходе детекторов ионизирующего излучения в интегральном или дифференциальном режиме амплитудной селекции. Значения измеряемой величины, как статистически распределенной по своей природе, могут быть определены только путем усреднения числа актов регистрации ионизирующих частиц по интервалам времени. Зарегистрированное количество импульсов определяет статистическую погрешность единичного измерения, а временной интервал усреднения, обеспечивающий нормативную погрешность – их производительность. Для методов с непрерывной регистрацией информации во времени (или в пространстве) временное окно измерений определяет также временную (или пространственную, с учетом скорости перемещения детектора) разрешающую способность интерпретации результатов измерений, при этом эффективность регистрации информации обычно ограничена условиями измерений и/или техническими средствами их исполнения. Типичный пример - каротаж скважин, где возможности увеличения интенсивности потоков информации ограничены параметрами эффективности регистрации и чувствительности детекторов излучения, которые зависят от их типа и размеров. Размеры детекторов, естественно, существенно зависят от размеров скважинных приборов, которые, в свою очередь, ограничены диаметрами скважин.
Ниже рассматривается возможность повышения точности и производительности непрерывных ядерно-физических измерений, для наглядности, применительно к условиям измерений в варианте скважинного гамма-опробования, хотя в такой же мере она может быть использована в авто- и аэрогаммасъемке, при радиометрическом обогащении руд, в рентгенорадиометрии и других методах ядерной геофизики. Предполагается, что регистрация данных производится в цифровой форме с накоплением отсчета по постоянным интервалам дискретизации данных (по времени и по пространству, при условии постоянной скорости перемещения детектора).
В общем случае полезная (целевая) информация может присутствовать в нескольких энергетических интервалах спектра излучения. Рабочими интервалами измерений обычно считаются участки спектра, где полезная информация присутствует в "чистом" виде либо в смеси с помехами (фоном), значение которых может быть учтено при обработке результатов измерений. Так, например, при гамма-опробовании пород на содержание естественных радионуклидов (ЕРН) регистрируется излучение с энергией более 250-300 кэВ, представленное в основном первичными и однократно рассеянными квантами, плотность потока которых пропорциональна массовой доле ЕРН в породах. Плотность потока излучения в низкоэнергетическом интервале спектра (20-250 кэВ, в основном многократно рассеянное излучение) также зависит от массовой доли ЕРН, но эта зависимость является параметрически связанной с эффективным атомным номером излучающе-поглощающей среды в области детектора, вариации которого по стволу скважины могут приводить к большой погрешности интерпретации результатов измерений. Между тем плотность потока полезной информации (относительно массовой доли ЕРН) в интервале 20-250 кэВ много выше, чем в интервале более 250 кэВ, особенно при регистрации излучения сцинтилляционными детекторами малых объемов, которые имеют повышенную чувствительность именно к низкоэнергетической части спектра излучения.
Задача статистической группировкиинформации в потоках сигналов в общей и наиболее простой форме может быть сформулирована следующим образом. Полезная информация присутствует в двух статистически независимых потоках сигналов (в двух неперекрывающихся интервалах спектра излучения). В первом потоке сигналов, условно- основном, полезная информация присутствует в "чистом" виде: плотность потока сигналов пропорциональна определяемой физической величине. Во втором потоке, условно-дополнительном, на полезную информацию наложено влияние дестабилизирующих факторов, значение которых неизвестно. При отсутствии дестабилизирующих факторов коэффициент корреляции средних значений плотностей потоков в этих двух потоках сигналов постоянен и близок к 1. Для снижения статистической погрешности измерений требуется осуществить извлечение полезной информации из дополнительного потока сигналов и ее суммирование с основным потоком.
Обозначим потоки, а равно и частоты основного и дополнительного потоков сигналов индексами n и m (импульсов в секунду), связь потоков по частотам индексом х = m/n. Определению подлежит частота потока n. Значение х может изменяться за счет влияния дестабилизирующих факторов на поток m и в общем случае представляет собой случайную величину, распределенную по определенному закону с плотностью вероятностей Р(х), математическим ожиданием 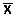 , и дисперсией Dx.
, и дисперсией Dx.
На основе теоремы Байеса, плотность вероятностей распределения частоты n по измеренному за единичный интервал t числу отсчетов сигнала N определяется выражением:
PN(n) = P(n) Pn(N) /P(N), (11.2.1)
где: Pn(N) = (nТ)N e-nt /N! , (11.2.2)
P(N) = 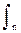 Pn(N) P(n) dn, (11.2.3)
Pn(N) P(n) dn, (11.2.3)
здесь P(n)- априорная плотность вероятностей частоты n, Pn(N)- апостериорное распределение вероятностей числовых отсчетов N (закон Пуассона). Принимая в дальнейшем в качестве искомой величины значения отсчетов z=nt по интервалам t (экспозиция цифровых отсчетов или скользящее временное окно аналоговых данных) и подставляя (2) и (3) в (1), получаем:
PN(z) = P(z) zN e-z / 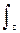 P(z) zN e-z dz. (11.2.4)
P(z) zN e-z dz. (11.2.4)
При неизвестном распределении значений z априорная плотность распределения P(z) принимается равномерной от 0 до ¥, при этом из выражения (11.2.4) следуют общеизвестные выражения:
z = Dz = N+1 @ N, (11.2.5)
dz2 = Dz /z2 = 1 /(N+1) @ 1/N, (11.2.6)
Значениями единиц в выражениях пренебрегаем, что не только корректно в условиях "хорошей" статистики, но и необходимо в режиме последовательных непрерывных измерений для исключения смещения средних значений.
Как следует из теории гамма-каротажа (ГК) и достаточно хорошо подтверждено практикой гамма-опробования, пространственная разрешающая способность гамма-каротажных измерений при интерпретации результатов ГК на содержание естественных радиоактивных элементов в породах по стволу скважин в среднем составляет 10 см, а в скважинах малого диаметра может даже повышаться до 5-7 см. Однако реализация такой разрешающей способности возможна только в условиях достаточно "хорошей" статистики. Коэффициент усиления дисперсии помех цифровых фильтров деконволюции, которые используются при интерпретации ГК, в среднем порядка 12 и изменяется от 4 до 25 в зависимости от плотности пород, диаметра скважин, диаметра скважинных приборов и пр. Отсюда следует, что для достижения разрешающей способности в 10 см при нормативной погрешности дифференциальной интерпретации не более 10-20 % статистическая погрешность измерений не должна превышать 3-7 %. А это, в свою очередь, определяет объем отсчета за единичную экспозицию не менее 200-1000 импульсов. При гамма-каротаже последнее возможно только для пород с относительно высоким содержанием ЕРН (более 0.001 % эквивалентного урана), при использовании детекторов больших размеров (с эффективностью регистрации более 10 имп/сек на 1 мкР/час) и при низкой скорости каротажа (не более 100-300 м/час). В той или иной мере эта проблема характерна для всех методов ядерной геофизики, и особенно остро стоить в спектрометрических модификациях измерений.
Вместе с тем следует отметить, что процесс непрерывных измерений имеет определенную физическую базу как для применения методов регуляризации результатов интерпретации данных, так и для регуляризации непосредственно самих статистических данных (массивов отсчетов N) при их обработке.
Простейшим способом подготовки цифровых данных для интерпретации является их низкочастотная фильтрация методом наименьших квадратов (МНК) или весовыми функциями (Лапласа-Гаусса, Кайзера-Бесселя и др.). Однако любые методы низкочастотной фильтрации данных снижают пространственную разрешающую способность интерпретации, так как кроме снижения статистических флюктуаций приводят к определенной деформации частотных составляющих полезной части сигнала, спектр которого по условиям деконволюции должен иметь вещественные значения вплоть до частоты Найквиста. В определенной мере ликвидировать этот негативный фактор позволяет метод адаптивной регуляризации данных (АРД).
Выражения (11.2.5-6) получены в предположении полной неизвестности априорного распределения P(z)для отсчетов в каждой текущей экспозиции t. Между тем, при обработке данных непрерывных измерений, и тем более каротажных данных, которые обычно являются многопараметровыми, для каждого текущего отсчета при обработке данных может проводиться определенная оценка распределения P(z). Как минимум, можно выделить два способа оценки распределения P(z).
Способ 1. По массивам данных параллельных измерений каких-либо других информационных параметров, значения которых достаточно четко коррелированны с обрабатываемым массивом данных либо в целом по пространству измерений, либо в определенном скользящем интервале сравнения данных. К таким массивам относятся, например, предварительные каротажные измерения в процессе бурения скважин, измерения другим прибором, с другой скоростью каротажа, в другом спектральном интервале излучения, и даже другим методом каротажа. При гамма-опробовании оценка распределения P(z) может производиться по параллельным измерениям интенсивности потока m в низкочастотном интервале спектра горных пород.
Способ 2. При единичной диаграмме ГК оценка распределения P(z) в каждой текущей точке обработки данных может выполняться по ближайшим окрестностям данной точки, захватывающим более широкий пространственный интервал по сравнению с интервалом отсчетов.
Использование априорных данных.Допустим, что кроме основного массива данных N,подлежащего обработке (подготовке к интерпретации), мы располагаем дополнительным массивом данных M, значения которого в определенной степени коррелированы с массивом N. При отсутствии дополнительных массивов способ 2 позволяет получить массив М обработкой массива N цифровым фильтром МНК (или любым другим весовым фильтром) со скользящим временным окном T = kt при к ³ 3 (Mi = mitсглаженного сигнала mi = ni * hk, где hk – оператор симметричного цифрового фильтра с k – окном). Отметим также, что 2-ой способ всегда может использоваться для регуляризации данных независимо от наличия данных для 1-го метода.
Массив М позволяют дать оценку статистических характеристик распределения P(z). Так, если для тех же интервалов времени t в массиве М имеются отсчеты М = mit (или приведенные к ним отсчеты какого-либо другого параметра), то можно записать:
PM(z) = 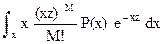 , (11.2.7)
, (11.2.7)
где Р(х) – априорная плотность распределения значений xi = mi/ni, которые в общем случае также могут быть случайными. При равномерном распределении Р(х) от 0 до ¥ для отсчета М равновероятно любое значение z, т.е. эффект от измерений в потоке m отсутствует. Однако по исходным условиям задачи в потоке m обязательно присутствие полезной информации, а, следовательно, исуществование, как минимум, определенных границ распределения Р(х) от хmin > 0 до xmax << ¥, и среднего значения по пространству измерений. При этом из выражения (11.2.7) следует, что наиболее вероятное значение za, "априорное" для отсчетов z=nt в потоке n по измерениям в потоке m (отсчетам М), должно быть равно:
za = (M+1)/ @ М/ . (11.2.8)
При статистической независимости величин х и М относительная средняя квадратическая погрешность определения значений za по отсчетам в массиве М:
dza2 = dM2 + dx2. (11.2.9)
Отсюда дисперсия распределения значений za:
Dza = (DM+M2dx2)/ 2 = D(M) / 2, (11.2.10)
D(M) = DM+M2dx2 = DM+Dxm , (11.2.11)
DM = М+1 @ М, Dxm = M2dx2,
где значение дисперсии DM определяется статистикой отсчетов в массиве М при х = const, значение Dxm представляет собой дисперсию значений М за счет флюктуаций величины х, а сумма D(M) определяет полную дисперсию отсчетов М.
Влияние Р(х) на форму распределения РМ(z) сказывается в его "растягивании" по координате z относительно модального значения, при этом решение интеграла (11.2.7) в первом приближении может быть представлено в следующем виде:
PM(z) @ b 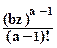 e-bz. (11.2.12)
e-bz. (11.2.12)
Для данного распределения:
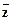 = za = a/b, (11.2.13)
= za = a/b, (11.2.13)
Dza = a/b2, (11.2.14)
С учетом выражений (11.2.8) и (11.2.10):
a = MDM/(Dza 2) = MDM/D(M), (11.2.15)
b = DM/(Dza ) = DМ/D(M). (11.2.16)
Значение 'а' в выражении (11.2.15) принимается целочисленным. Выражение (11.2.12) может быть принято для распределения (11.2.4) в качестве априорного распределения вероятностей Р(z), при этом:
PN(z) = (b+1) 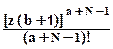 e-z(b+1). (11.2.17)
e-z(b+1). (11.2.17)
Отсюда, математическое ожидание и дисперсия z:
z = (N+a)/(b+1), (11.2.18)
Dz = (N+a)/(b+1)2. (11.2.19)
C использованием выражений (11.2.15-16):
z = bN+(1-b)M/ , (11.2.20)
где b и (1-b) – весовые коэффициенты доверия отсчетам N и M:
b = D(M)/(DN 2+D(M)). (11.2.21)
Дисперсия и относительная средняя квадратическая погрешность отсчетов z:
Dz = D(M) 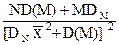 , (11.2.22)
, (11.2.22)
dz2 =1/(N+MDM/D(M)). (11.2.23)
Эффективность метода. Сравнение выражений (11.2.20-23) и (11.2.5-6) позволяет дать оценку эффекта использования дополнительной информации из статистически независимого от N потока М (произвольная дополнительная информация).
1. При Þ const имеет место dх2 Þ 0, Dxm Þ 0 и дисперсия отсчетов в массиве М определяется только статистикой потока:
D(M) Þ DM = M, z = (N+M) /( +1),
dz2 Þ 1/(N+M) < dN2 = 1/N, (11.2.24)
h = dN2 /dz2 = [N+M2/D(M)] /N Þ 1+M/N,
что соответствует определению z по двум независимым измерениям и эффект использования дополнительной информации максимален. Так, при M » N, h Þ 2 и погрешность измерений уменьшается в 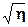 ~1.4 раза.
~1.4 раза.
2. В общем случае Dxm ¹ 0, при этом D(M) > DМ и положительный эффект снижается. В пределе: dx Þ ¥, Dxm Þ ¥, D(M) Þ ¥, h Þ 1, z Þ N, dz Þ dN и положительный эффект полностью вырождается. Во всех остальных случаях h > 1 и dz < dN. Отсюда следует, что при наличии коррелированной информации в массиве М положительный эффект, в той или иной мере, всегда имеет место.
3. Положительный эффект тем больше, чем больше значение x = m/n, меньше флюктуации х (величина dх), и меньше значения отсчетов N = nt. Положительный эффект увеличивается именно в тех случаях, когда особенно остро ощущается недостаток информации: при малых значениях плотности потока излучения и/или экспозиции измерений.
Аналогичный эффект будет иметь место и при формировании отсчетов Mi по окрестностям текущих точек обработки данных путем определения их среднего значения (низкочастотное сглаживание массива n). Предварительное низкочастотное сглаживание может применяться и для статистически независимого дополнительного массива m, что будет повышать достоверность прогнозных отсчетов и увеличивать глубину регуляризации, если это сглаживание при регуляризации по формулам (11.2.20 и 21) не сказывается на изменении формы основного сигнала. Последнее определяется соотношением частотных спектров основного сигнала и оператора сглаживания.
Возможны два способа реализации уравнения (11.2.20): непосредственно в процессе измерений методом статистической группировки полезной информации (СГПИ) в реальном масштабе времени, или методом статистической регуляризации данных (СРД), зарегистрированных в виде временного (пространственного) распределения в параллельных массивах отсчетов.
11.3. Статистическая регуляризация данных.
Как следует из выражения (11.2.21), для практического использования информации из дополнительных потоков данных необходимо установить значения и дисперсию D(M), причем, исходя из задания последней по выражению (11.2.11), должно быть известно значение dx - относительной средней квадратической флюктуации величины х.
Применительно к СРД определение значений и dx по зарегистрированным массивам данных не представляет затруднений как в целом по пространству измерений, так и в виде распределений в скользящем окне усреднения данных. Последнее эквивалентно приведению Dxm => 0 для текущей точки обработки данных по информации ее ближайших окрестностей и позволяет производить максимальное извлечение полезной информации из дополнительных потоков сигналов, если частотный спектр распределения величины х по пространству измерений много меньше частотного спектра полезного сигнала. Отметим, что информация о распределении х также может иметь практическое значение (в частности, при гамма-опробовании с дополнительным потоком сигналов в низкоэнергетическом диапазоне спектра излучения - для оценки эффективного атомного номера горных пород).
Проверка теоретических положений метода АРД проводилась путем статистического моделирования на ПК соответствующих массивов данных и их обработки цифровыми фильтрами.
В таблице 1 приведены 4 группы результатов обработки по формулам (11.2.20-21) двух статистически независимых и постоянных по средним значениям массивов данных n и m (модели постоянных полей) при различных установках СРД по скользящему окну Кс счета текущих значений 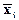 = mi/ni и Di(М) по массиву m. Текущая точка обработки данных – по центру окна. Количество отсчетов в каждом массиве – 1000, распределение значений отсчетов соответствует закону Пуассона. Определение прогнозных отсчетов Мi по массиву m для использования в уравнении (11.2.20) проводилось со сглаживанием отсчетов в скользящем окне Ks низкочастотного цифрового фильтра (вариант без сглаживания при Ks = 1). В качестве низкочастотного фильтра в алгоритме СРД используется (здесь и в дальнейшем) весовое окно Лапласа-Гаусса. Теоретическое значение Dz.т. дисперсии результатов z определялось по выражению (11.2.22) с расчетом дисперсии D(M) по выражению D(M) =
= mi/ni и Di(М) по массиву m. Текущая точка обработки данных – по центру окна. Количество отсчетов в каждом массиве – 1000, распределение значений отсчетов соответствует закону Пуассона. Определение прогнозных отсчетов Мi по массиву m для использования в уравнении (11.2.20) проводилось со сглаживанием отсчетов в скользящем окне Ks низкочастотного цифрового фильтра (вариант без сглаживания при Ks = 1). В качестве низкочастотного фильтра в алгоритме СРД используется (здесь и в дальнейшем) весовое окно Лапласа-Гаусса. Теоретическое значение Dz.т. дисперсии результатов z определялось по выражению (11.2.22) с расчетом дисперсии D(M) по выражению D(M) = 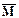 [1+ (1/(Kc
[1+ (1/(Kc 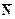 )+1/(Kc ))]. При сглаживании прогнозных отсчетов значение DM в выражении (11.2.22) принималось равным DM. = ×Hs, где Hs – коэффициент усиления сглаживающим фильтром дисперсии шумов (сумма квадратов коэффициентов цифрового фильтра). Дополнительно в таблице приводятся зарегистрированные средние значения коэффициента снижения статистических флюктуаций h = dn2/dz2.
)+1/(Kc ))]. При сглаживании прогнозных отсчетов значение DM в выражении (11.2.22) принималось равным DM. = ×Hs, где Hs – коэффициент усиления сглаживающим фильтром дисперсии шумов (сумма квадратов коэффициентов цифрового фильтра). Дополнительно в таблице приводятся зарегистрированные средние значения коэффициента снижения статистических флюктуаций h = dn2/dz2.
Таблица 1.
Статистика результатов моделирования СРД.
(Основной массив 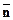 = 9.9, Dn = 9.7, дополнительный массив
= 9.9, Dn = 9.7, дополнительный массив 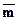 = 9.9, Dm = 9.9, 1000 отсчетов.)
= 9.9, Dm = 9.9, 1000 отсчетов.)
| Kc | Ks | z | Dz | Dz.т. | h | Kc | Ks | z | Dz | Dz.т. | h |
| 9,7 | 5,7 | 6,19 | 1,7 | 9,6 | 3,6 | 3,80 | 2,8 | ||||
| 9,7 | 5,4 | 5,78 | 1,8 | 9,6 | 3,3 | 3,55 | 3,0 | ||||
| 9,6 | 5,1 | 5,36 | 1,9 | 9,6 | 3,1 | 3,22 | 3,2 | ||||
| 9,6 | 5,0 | 5,18 | 2,0 | 9,6 | 3,0 | 3,11 | 3,3 | ||||
| 9,6 | 5,0 | 5,05 | 2,0 | 9,6 | 3,0 | 2,99 | 3,3 | ||||
| 9,7 | 4,1 | 4,71 | 2,4 | 9,8 | 4,5 | 4,26 | 2,2 | ||||
| 9,7 | 3,6 | 4,01 | 2,8 | 9,7 | 3,5 | 3,78 | 2,8 | ||||
| 9,6 | 3,1 | 3,22 | 3,2 | 9,6 | 3,1 | 3,22 | 3,2 | ||||
| 9,6 | 2,9 | 2,91 | 3,4 | 9,6 | 3,1 | 3,12 | 3,2 | ||||
| 9,6 | 2,7 | 2,66 | 3,7 | 9,6 | 3,1 | 2,99 | 3,2 |
Как видно из данных таблицы, практические результаты фильтрации достаточно хорошо совпадают с ожидаемыми по данным теоретических расчетов. Некоторое уменьшение среднего значения z по отношению к исходному среднему значению n определяется асимметричностью пуассоновского типа модели. При малых средних значениях модельных отсчетов в массиве m это приводит к определенной статистической асимметрии в работе СРД, т.к. при (+sm)2 > (-sm)2 среднестатистическое доверие к дополнительной информации с отсчетами Mi+s меньше, чем с отсчетами Mi-s. Этим же фактором, по-видимому, вызвано и большее расхождение между теоретическими и фактическими значениями Dz при малых значениях окна Кс. Можно также заметить, что по значению коэффициента h фильтрация выходит на теоретические значения (Þ 1+M/N) только при достаточно точном определении значений и Di(М), что требует увеличения окна Кс счета этих параметров для полного использования дополнительной информации.
Таблица 2.
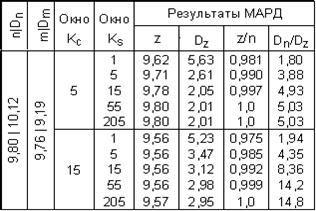
|
Эффект использования дополнительной информации, в полном соответствии с выражением (11.2.22), усиливается при предварительном сглаживании статистических вариаций отсчетов Mi и при увеличении значений отсчетов дополнительного массива (материалы по последнему случаю не приводятся, т.к. не имеют какой-либо дополнительной информации). В спокойных по динамике полях еще большая глубина регуляризации может быть достигнута при счете значений и Dm по сглаженному массиву М, что позволяет повысить вес прогнозных отсчетов Mi. Результаты моделирования данного варианта в тех же условиях, что и для таблицы 1, приведены в таблице 2. Такой же эффект, в принципе, может достигаться и непосредственным введением дополнительного коэффициента веса в выражение (11.2.20) в качестве множителя для значения D(M), что позволяет осуществлять внешнее управление глубиной регуляризации.
Оценка СРД по сохранению разрешающей способности полезной информации была проведена на фильтрации детерминированных сигналов n и m предельной формы – в виде прямоугольных импульсов. Оценивались два фактора: сохранение формы полезного сигнала и подавление статистических шумов, наложенных на полезный сигнал.
При установке СРД без усреднения данных по массиву М (Кs = 1, прогноз Мi по текущим значениям массива М) при любых значениях окна Кс выходной массив Z без всяких изменений повторяет массив N, т.е. не изменяет полезный сигнал и полностью сохраняет его частотные характеристики. Естественно при условии, что массив М пропорционален массиву N.
При Кs > 1 форма выходных кривых несколько изменяется и приведена на рис. 11.3.1. В индексах выходных кривых z приведена информация по установкам окон СРД: первая цифра - окно счета дисперсии DM и текущего значения (в количестве точек отсчетов), вторая цифра (через флеш) - окно сглаживания отсчетов М весовой функцией Лапласа-Гаусса и определения прогнозных отсчетов Мi. Для сравнения с результатами типовой низкочастотной фильтрации на рисунке приведена кривая n25 отсчетов N, сглаженных весовой функцией Лапласа-Гаусса с окном 25 точек.
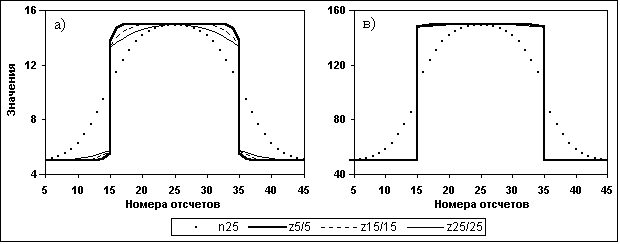
Рис. 11.3.1. СРД прямоугольного импульса. Счет Dm по несглаженному массиву М.
На рис. 11.3.1а приведен результат СРД прямоугольного импульса с амплитудным значением 10 на фоне 5 при отношении m/n = 1 (равные значения отсчетов N и М). Дисперсия DN в выражении (11.2.21) принималась равной значению отсчетов N (статистика Пуассона). Как видно на рисунке, при сохранении фронтов сигнальной функции сглаживание прогнозных значений Мi приводит к появлению искажения формы сигнала по обеим сторонам скачка, интервал которого тем больше, чем больше значение Ks. Амплитудное значение искажений, как это и следует из выражения (11.2.21), в первую очередь зависит от соотношения текущих значений DN и D(M) и в меньшей степени от глубины сглаживания прогнозных отсчетов.
Максимальную величину искажения для точек скачка в первом приближении можно оценить из следующих соображений. Значения D(M) между точками скачка равны D(M) = А2/4, где А - амплитуда скачка, при этом значения коэффициента b для нижней и верхней точек скачка определяются выражениями b » А2/(4DN+A2), где DN = N точки скачка (для статистики Пуассона). Отсюда, при прогнозном значении М » N+А/2 для нижней точки скачка и M » N-A/2 для верхней точки относительная величина изменений N определится выражением d » 1/(2N/A+A), т.е. будет тем меньше, чем больше значения А и N и больше отношение N/A, что можно наглядно видеть на рис. 11.3.1в. Из этого выражения также следует, что максимальные искажения скачков, вносимые системой СРД, будут всегда в несколько раз меньше, чем статистические флюктуации непосредственных отсчетов d = 1/ 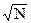 на краях скачков.
на краях скачков.
При увеличении глубины регуляризации введением счета дисперсии D(M) по сглаженному массиву М картина искажений несколько изменяется и приведена на рис. 11.3.2. Реакция СРД на сглаживание дисперсии D(M) проявляется в своеобразной компенсации абсолютных отклонений отсчетов непосредственно по сторонам скачка отклонениями противоположного знака в более дальней зоне от скачка. Максимальные значения искажений остаются примерно на таком же уровне, как и для работы по несглаженной дисперсии D(M), с несколько меньшей зависимостью от увеличения значений N и А.
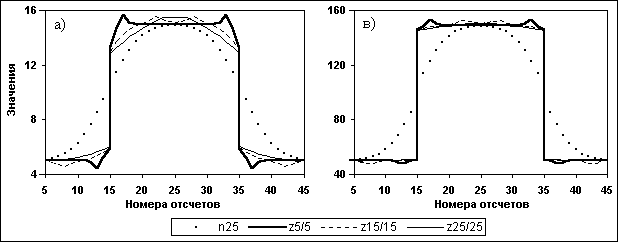
Рис. 11.3.2. СРД прямоугольного импульса. Счет Dm по сглаженному массиву М.
В приведенных примерах значение окна счета Кс принималось равным значению окна сглаживания Кs дополнительного массива М. При Кс > Ks картина процесса практически не изменяется. При обратном соотношении размеров окон вступает в действие второй фактор - отклонение от фактических значений счета текущих значений xi = m/n в малом окне Кс по массиву отсчетов, сглаженных с большим окном Ks. На расстояниях от скачка функции, больших Кс/2, СРД переходит в режим предпочтения сглаженных значений массива М, т.к. D(M) Þ 0, что при Кс < Ks может приводить к появлению существенной погрешности – выбросов на расстояниях ± Кс/2 от скачков. Естественно, что при практических измерениях таких условий наблюдаться не будет и эффект резко уменьшится, но для полного его исключения вариант Kc ³ Ks можно считать предпочтительным.
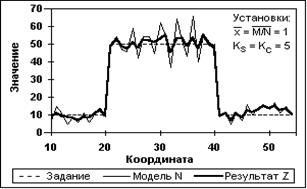  Рис. 11.3.3. СРД сигнала N по массиву M. Рис. 11.3.4. Коэффициент b.
(Счет Dm по несглаженному массиву М). (Среднее статистическое по 50 циклам)
Рис. 11.3.3. СРД сигнала N по массиву M. Рис. 11.3.4. Коэффициент b.
(Счет Dm по несглаженному массиву М). (Среднее статистическое по 50 циклам)
|
На рис. 11.3.3 приведен пример регистрации рандомизированного модельного сигнала в виде прямоугольного импульса амплитудой 40 на фоне 10, на котором виден принцип работы СРД. Как и следовало ожидать, СРД производит сглаживание статистических флюктуаций фона и сигнала за пределами зоны ±Кс от скачка, отдавая предпочтение сглаженным прогнозным значениям Мi, и не изменяет значения фона и сигнала в пределах этой зоны в связи с резким возрастанием текущих значений D(M) в выражении (11.2.21). Изменение коэффициента b в зоне скачка, управляющего формированием выходных отсчетов, приведено на рис. 11.3.4 (среднестатистическое по 50-ти циклам рандомизации для модельного импульса на рис. 11.3.3) и наглядно показывает принцип адаптации СРД к динамике изменения значений обрабатываемых сигналов.
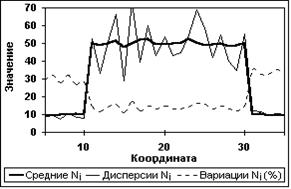 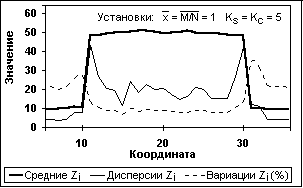 Рис. 11.3.5. Статистика сигнала N Рис. 11.3.6. Статистика сигнала Z
(Измерения по 50-ти циклам). (50 циклов. Счет Dm по несглаженному М)
Рис. 11.3.5. Статистика сигнала N Рис. 11.3.6. Статистика сигнала Z
(Измерения по 50-ти циклам). (50 циклов. Счет Dm по несглаженному М)
|
Статистическая оценка работы СРД по прямоугольным импульсам проводилась по 50-ти циклам рандомизации исходных массивов N и M. В качестве примера на рисунках 11.3.5 и 6 приведены результаты обработки статистики массивов N и Z. Кроме статистики циклов рандомизации проводилась суммарная обработка всех циклов по общей статистике фона и вершины импульсов. Результаты обработки для тех же установок фильтров приведены в таблице 3.
Таблица 3.
Статистика значений фона и вершины импульсов (50 циклов).
| Массивы и условия обработки | Фон | Сигнал | ||
| Сред.отсчет | Дисперсия | Сред.отсчет | Дисперсия | |
| Основной входной массив N Дополнительный входной массив М Массив Z, счет Dm по несглаженному М Массив Z, счет Dm по сглаженному М Массив N, сглаженный весовым окном | 9.96 9,89 9,87 9,84 11,5 | 9.97 9,49 5,47 4,76 17,9 | 50,1 50,2 49,7 49,9 48,5 | 52,0 47,4 22,3 18,6 29,2 |
Результаты моделирования подтверждают преимущество СРД перед простыми методами сглаживания. В числовой форме это наглядно проявляется в снижении дисперсии отсчетов выходного массива Z при практическом сохранении средних значений массива N и для фоновых отсчетов, и для амплитудных значений сигнала. При простом сглаживании "развал" фронтов сигнала (подавление высокочастотных составляющих спектра сигнала), как и должно быть при использовании низкочастотных фильтров, вызывает снижение по отношению к исходному массиву средних значений в максимумах и повышение фоновых значений сигнала, которое тем больше, чем больше окно весовой функции. Этот эффект особенно отчетливо проявляется в интервале окна фильтра по обе стороны от резких изменений сигнала.
При отсутствии дополнительных массивов М, коррелированных с регуляризируемым массивом N, формирование прогнозных значений Мi может производиться по ближайшим окрестностям текущих значений Ni в скользящем окне Ks. При строго корректном подходе текущая точка Ni не должна включаться в число счета прогнозных значений Mi, но, как показало моделирование, это практически не влияет на результаты регуляризации. При прогнозировании Mi по всем точкам окна Ks массив М формируется любым методом сглаживания из массива N, и все особенности работы СРД по сглаженным массивам М, рассмотренные выше, остаются без изменений при условии счета значений Dm в окне Кс по массиву М. Для исключения выбросов по обе стороны от скачков полезного сигнала счет Dm как дисперсии прогнозных значений Mi необходимо выполнять непосредственно по массиву N.
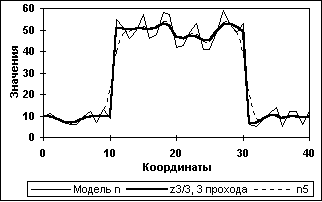 Рис. 11.3.7. СРД одиночного массива N
(3 прохода. Счет Dm по массиву n)
Рис. 11.3.7. СРД одиночного массива N
(3 прохода. Счет Dm по массиву n)
|
Фундаментальной особенностью СРД является возможность последовательной многократной фильтрации данных, при которой может осуществляться преимущественное повышение степени регуляризации данных с минимальными искажениями формы полезного сигнала. Для выполнения последнего размер окна Кс счета xi и Dm устанавливается минимальным (3-5 точек), а глубина регуляризации данных (степень подавления шумов) устанавливается количеством последовательных операций фильтрации (до 3-5 проходов). Пример регуляризации модельного массива N в три прохода приведен на рис. 11.3.7. Для сравнения пунктиром на рисунке приведено сглаживание массива 5-ти точечным фильтром Лапласа-Гаусса, который имеет коэффициент подавления шумов, эквивалентный 3-х проходному СР
Дата добавления: 2020-02-05; просмотров: 758;
Поиск по сайту
Узнать еще
- Altium Designer (Protel) - сквозная система проектирования печатных плат
- B). Система относительных координат.
- DSM — система классификации Американской психиатрической ассоциации
- I. Математические понятия
- II. НАЛОГОВАЯ СИСТЕМА В СОВРЕМЕННОЙ РОССИИ
- II. Научность, систематичность и последовательность обучения.
- II. Формализация процесса формирования математических моделей
- Mатематическое определение ОС.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
