Особенности образования названий процессоров
Раньше процессоры называли просто: имя производителя + название модельного ряда + частота. Например: Intel Pentium 100 MHz. В настоящее время оба основных производителя от этой традиции отошли, и вместо частоты употребляют различные цифро-буквенные обозначения.
1. Рейтинги от AMD. Причина, по которой компания AMD <изъяла> частоту из наименования своих процессоров, и заменила её некой абстрактной цифрой - общеизвестна: после появления процессора Intel Pentium 4, который работает на очень высоких частотах, процессоры AMD рядом с ним стали <плохо выглядеть на витрине> - покупатель не верил, что CPU с частотой, например, 1500 МГц, может обогнать CPU с частотой 2000 МГц. Поэтому частоту в наименовании заменили рейтингом. Формальная трактовка этого рейтинга в устах AMD в разные времена звучала немного по-разному, но ни разу не прозвучала в том виде, в каком её воспринимали пользователи: процессор AMD с неким рейтингом, должен быть как минимум не медленнее процессора Intel Pentium 4 с соответствующей данному рейтингу частотой.
2. Intel подошла к обозначению процессоров с другой стороны: был введен Processor Number (далее PN), который не является ни рейтингом производительности, не рейтингом чего-либо другого. Фактически, это просто «артикул», единственная задача которого - сделать так, чтобы строчка, обозначающая один процессор, отличалась от строчки, обозначающей другой. Цифры в обозначении модели, в принципе, кое-что могут сказать о производительности процессора, а полное соответствие между PN и реальными параметрами, приведено в техническом описании процессора.
1.ОбщиепринципывзаимодействияпроцессораиОЗУ
Контроллерпамяти
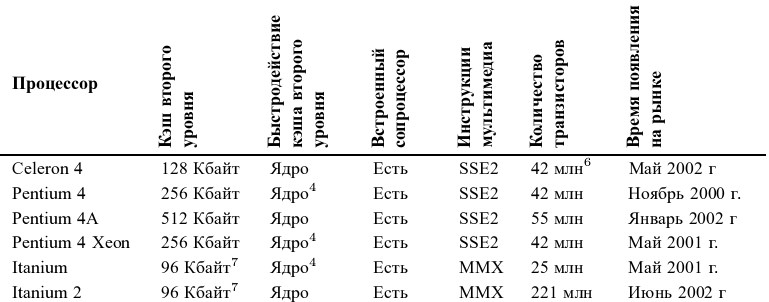
Команды и данные, попадают в процессор из оперативной памяти. В большинстве современных x86-систем (то есть компьютеров на базе x86-процессоров), процессор как устройство к памяти обращаться вообще не может, так как не имеет в своем составе соответствующих узлов.
Поэтому он обращается к «промежуточному» специализированному устройству, называемому контроллером памяти, а уже тот, в свою очередь - к микросхемам ОЗУ, размещенным на модулях памяти.
Роль контроллера ОЗУ - он служит мостом между памятью и использующими ее устройствами. Как правило, контроллер памяти входит в состав чипсета - набора микросхем (традиционно называемой «северным мостом), являющегося основой системной платы. От быстродействия контроллера во многом зависит скорость обмена данными между процессором и памятью, это один из важнейших компонентов, влияющих на общую производительность компьютера.
Процессорнаяшина
Любой процессор обязательно оснащён процессорной шиной, которую в среде x86 CPU принято называть FSB (Front Side Bus). Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском, и так далее. Процессор посредством FSB связывается с контроллером памяти, а уже тот, в свою очередь, по специальной «шиной памяти» - с модулями ОЗУ на плате.
При этом, поскольку «внешняя» шина у классического x86 CPU всего одна, она используется не только для работы с памятью, но и для общения процессора со всеми остальными устройствами.
Различиямеждутрадиционнойдляx86 CPUархитектуройиK8/AMD64
Революционность подхода компании AMD состоит в том, что её процессоры с архитектурой AMD64 оснащены множеством «внешних» шин. При этом одна или несколько шин HyperTransport служат для связи со всеми устройствами кроме памяти, а отдельная группа из одной или двух (в случае двухканального контроллера) шин - исключительно для работы процессора с памятью.
Преимущество интеграции контроллера памяти прямо в процессор, очевидно: путь от ядра до памяти становится заметно короче, что позволяет работать с ОЗУ быстрее. Правда, имеются у данного подхода и недостатки. Так, например, если ранее устройства типа жёсткого диска или видеокарты могли работать с памятью через выделенный, независимый контроллер - то в случае с архитектурой AMD64 они вынуждены работать с ОЗУ через контроллер, размещённый на процессоре.
Оперативнаяпамять.
1. Разрядность шины памяти, N-канальные контроллеры памяти.
По состоянию на сегодняшний день, вся память, используемая в современных десктопных x86-системах имеет шину шириной 64 бита. Это означает, что за один такт по данной шине одновременно может быть передано количество информации, кратное 8 байтам (8 байт для SDR-шин, 16 байт для DDR-шин). Ширина шины памяти во всех современных контроллерах, применяемых в x86-системах, равна 64 битам - независимо от того, находится этот контроллер в чипсете, или в самом процессоре. Некоторые контроллеры оснащены двумя независимыми 64-битными каналами, но на разрядность шины памяти это никак не влияет - только на скорость считывания и записи информации.
2. Скорость чтения и записи. Скорость чтения и записи информации в память теоретически ограничивается исключительно пропускной способностью самой памяти. Так, например, двухканальный контроллер памяти стандарта DDR400 теоретически способен обеспечить скорость чтения и записи информации, равную:
8 байт (ширинашины) * 2 (количествоканалов) * 2 (протокол DDR, обеспечивающийпередачу 2 пакетовданныхза 1 такт) * 200'000'000 тактоввсекунду (фактическаячастотаработышиныпамятиравная 200 МГц) = 6400 Гбайт/сек.
Значения, получаемые в результате практических тестов, как правило, чуть ниже теоретических: сказывается неидеальность конструкции контроллера памяти, плюс задержки, вызванные работой подсистемы кэширования самого процессора.
3. Латентность. Скорость линейного чтения или записи является вовсе не единственной характеристикой, влияющей на фактическую скорость работы процессора с ОЗУ. Необходимо кроме линейной скорости считывания или записи учитывать ещё и такую характеристику, как латентность.
Латентность - время, которое требуется для того, чтобы начать считывать информацию с определённого адреса.
Латентность является не менее важной характеристикой с точки зрения быстродействия подсистемы памяти, чем скорость передачи данных. Большая скорость обмена данными хороша тогда, когда их размер относительно велик, но если нам требуется множество данных с разных адресов - то на первый план выходит именно латентность.
С момента, когда процессор посылает контроллеру памяти команду на считывание (запись), и до момента, когда эта операция осуществляется, проходит определённое количество времени. Причём оно вовсе не равно времени, которое требуется на пересылку данных. Приняв команду на чтение или запись от процессора, контроллер памяти указывает ей, с каким адресом он желает работать. Доступ к любому произвольно взятому адресу не может быть осуществлён мгновенно, для этого требуется определённое время. Возникает задержка: адрес указан, но память ещё не готова предоставить к нему доступ.
У разных типов памяти она разная. Так, например, память типа DDR2 имеет в среднем гораздо большие задержки, чем DDR (при одинаковой частоте передачи данных). В результате, если данные в программе расположены хаотично и небольшими кусками, скорость их считывания становится намного менее важной, чем скорость доступа к началу куска, так как задержки при переходе на очередной адрес влияют на быстродействие системы намного сильнее, чем скорость считывания или записи.
Компромисс между скоростью чтения (записи) и латентностью - одна из основных проблем разработчиков современных систем: к сожалению, рост скорости чтения (записи), почти всегда приводит к увеличению латентности. Так, например, память типа SDR (PC66, PC100, PC133) обладает в среднем лучшей (меньшей) латентностью, чем DDR. В свою очередь, у DDR2 латентность ещё выше (то есть хуже), чем у DDR.
Заметим, что понятия <скорость чтения / записи> и <латентность>, в общем случае, применимы к любому типу памяти - в том числе не только к классической DRAM (SDR, Rambus, DDR, DDR2), но и к КЭШу.
2.Классификациязапоминающихустройств
Деление ЗУ на классы осуществляется по различным признакам.
Поспособудоступакинформации ЗУ принято делить на ЗУ с произвольным (прямым) доступом и ЗУ с последовательным доступом к информации (рис. 1).
К ЗУспроизвольнымдоступом относятся ЗУ, в которых доступ к любой адресуемой ячейке обеспечивается схемой селекции напрямую и не зависит от предыстории обращений к устройству.
| ЗУ |
| С |
| прямым |
| дос |
| - |
| тупом |
| С |
| после |
| дователь |
| ным |
| ступом |
| до |
| Со |
| смешанным |
| доступом |
| С |
| циклическим |
| доступом |
| С |
| апериодиче |
| - |
| ским |
| доступом |
| Рис |
| . 1. |
| Классификация |
| ЗУ |
| по |
| способу |
| доступа |
В ЗУспоследовательнымдоступом схема селекции организована таким образом, что доступ к адресуемой ячейке зависит от того, какое положение занимает адресуемая ячейка относительно средств чтения/записи в момент обращения.
ЗУ с последовательным доступом в свою очередь делятся на ЗУ с периодическим (циклическим) доступом и ЗУ с апериодическим (нециклическим) доступом к информации. В последовательных ЗУ с апериодическим доступом выбор ячейки с адресом А = n + N осуществляется путем последовательного перебора ячеек с адресами n + 1, n + 2, …, n + (N-1), где n - номер ячейки, к которой производилось последнее обращение. При этом время доступа τд = (N-1) τяч, где τяч - время обращения к одной ячейке. Пример: накопители на магнитной ленте (НМЛ).
В последовательных ЗУ сциклическимдоступом к информации доступ к адресуемой ячейке предоставляется периодически с периодом T = 1/w, где w - угловая скорость вращения носителя информации относительно неподвижных средств чтения/записи. Время доступа к ним является случайной величиной, которая лежит в пределах от 0 до T, среднее время доступа tд.ср=Т/2.
Пример такого рода ЗУ - накопитель на магнитном барабане (устаревший тип ЗУ).
Накопители на магнитных дисках (НМД) относятся и к ЗУсосмешанным типом доступа. В них обеспечивается произвольный доступ по одной координате (адресу), последовательный периодический доступ по другой координате и последовательный апериодический доступ по третьей координате, так как в НМД информация адресуется по трем координатам.
В зависимости от принципа(средства)хранения информации ЗУ делятся на:
1) полупроводниковые ЗУ - на основе электронных ЗЭ;
2) ЗУ на основе магнитных носителей информации - магнитных «запоминающих элементов»;
3) ЗУ на основе оптических носителей информации - оптических ЗЭ.
В зависимости от положенияинформации относительно средств ЧТ/ЗП различают ЗУ статического и динамического типа. К ЗУ статического типа относятся электронные ЗУ, в которых и информация и средства ЧТ/ЗП неподвижны, статичны. В ЗУ динамического типа в движении находится либо информация, либо средства ЧТ/ЗП.
ЗУ динамического типа в свою очередь делятся на ЗУ с подвижным и неподвижным носителем информации. К ЗУ с подвижным носителем информации относятся НМЛ, НМД, НОД.
К ЗУ с неподвижным носителем информации относятся ЗУ на цилиндрических магнитных доменах (ЦМД). В них движется информация относительно неподвижного носителя и неподвижных средств ЧТ/ЗП (информация хранится в динамике).
По способуорганизациисхемы селекции ЗУ делятся на адресные и безадресные. Безадресные в свою очередь делятся на ассоциативные, стековые и магазинные.
В зависимости от специфики использования информации ЗУ делятся на 3 типа:
1) ЗУ с частой сменой информации СОЗУ, ОЗУ, ВЗУ (НМД);
2) ЗУ с редкой сменой перепрограммируемые ПЗУ (ППЗУ);
3) ЗУ без смены информации постоянные ЗУ (ПЗУ, ПВЗУ - CD ROM).
В зависимости от того, требуется питание для хранения информации или нет, различают ЗУ энергозависимые и энергонезависимые.
3.Организацияпамятипервогоуровня
Основное назначение памяти первого уровня (СОП) - повысить быстродействие памяти ЭВМ и, следовательно, быстродействие ЦП. Действительно, время выполнения команды определяется суммой:
Тком = τком + n τопер + τвып + τрез
и, как видно из этого выражения, существенно зависит от времени обращения к памяти ЭВМ. Время выполнения команды можно существенно уменьшить, если сократить время обращения к памяти. Как?
1) Увеличивая быстродействие основной памяти (это дорого и непросто); 2) Между ОП и ЦП поставить СОП в качестве буфера (рис. 2).
| управление |
| ОП |
| команды |
| данные |
| СОП |
В РОН программист размещает часто используемые данные, обращение к которым осуществляется быстрее (в 3 - 5 раз), чем к ячейкам ОП. В результате команды, которые оперируют данными из РОН, выполняются быстрее. Пример: команды типа регистррегистр RR, регистр-память RS выполняются быстрее, чем команды типа память-память SS. Конструктивно (буфер)
Рис.2
РОН обычно располагают на одном кристалле (плате) вместе с ЦП (рис. 4).
Второй вариант организации буфера - буфер, недоступный, скрытый от программиста –Cache Memory (КЭШ). Кэш-буфер и используется как для хранения команд, так и для хранения данных. Емкость кэш-буфера - десятки, сотни КВ. ”Скрытость” кэш-буфера обеспечивает специальный механизм, который реализует автоматический (аппаратноуправляемый) обмен между ОП и буфером. Единицей обмена обычно является более крупная, чем слово, величина - т.е. строка кэша длиной в несколько слов. Более крупная единица обмена сокращает частоту обменов с ОП. В случае пословного обмена каждое слово в ОП, к которому обращается ЦП, размещается (дублируется) в соответствующей ячейке СОП. В случае более крупной единицы обмена в кэш дублируется целиком тот блок информации, к отдельному слову которого обращается ЦП. При этом существует большая вероятность, что последующие обращения со стороны ЦП будут к соседним словам этого блока и, следовательно, будут обслуживаться кэш-памятью без дополнительных обращений к ОП. команды
| ЦП |
| ОП |
| Буфер |
| ( |
| РОН |
| ) |
| данные |
| ком |
| . |
| данн |
| . |
| ЦП |
| данн |
| ОП |
| РОН |
| КЭШ |
| данн |
| . |
| ком |
| . |
Рис. 3
Рис. 4
Следует отметить, что буфер данных типа РОН организуется на основе ЗУсадреснойорганизацией.
Скрытый буфер (кэш) команд и данных организуется на основе ЗУсбезадреснойорганизацией, в частности, на основе ЗУ с ассоциативной организацией.
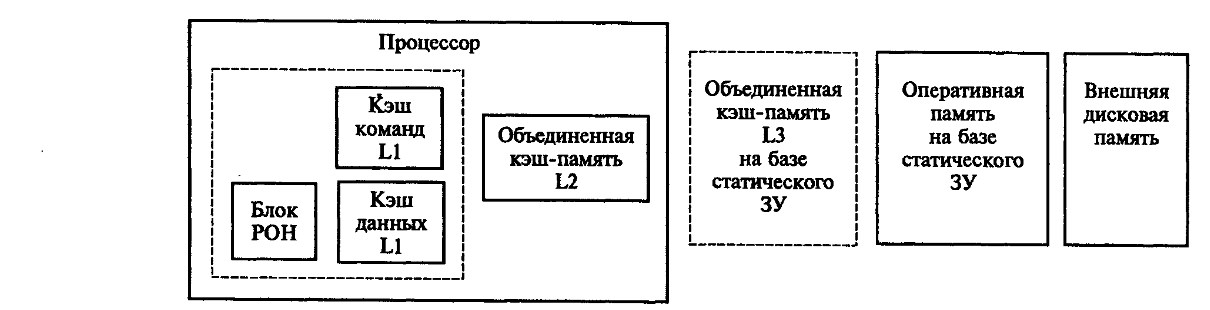
Обычно все содержимое кэш L1 находится в кэш L2, а все содержимое кэш L2 является частью кэш L3. Принципы построения кэш-памяти всех уровней сходны. В целом ОП вместе с кэшами всех уровней представляет собой единую систему памяти, непосредственно доступную процессору для чтения и записи данных, а также считывания команд программы.
Емкостьпамяти200байт16...32 256...512Кбайт1...4Мбайт64...256Мбайт8...64Гбайт
Кбайт
Времядоступа5нс<10нс<10нс<10нс30...60нc 5...30мс
Рис. 5.СтруктурапамятисовременныхВМ:
РОН—регистрыобщегоназначения; Li, L2, L3 —уровникэш-памяти;
ОЗУ—оперативноезапоминающееустройство;
DRAM -сверхбольшиеинтегральныесхемысдинамическойпамятью
Внешняя кэш-память второго уровня процессоров Pentium Pro, Pentium ll/lll, Xeon и Athlon компании AMD содержит дополнительно соответственно 15,5 (256 Кбайт), 31 (512 Кбайт), 62 (1 Мбайт) и 124 млн (2 Мбайт) транзисторов в отдельных микросхемах. Внешняя кэш-память третьего уровня объемом 2 или 4 Мбайт, включенная в процессор Itanium, содержит уже около 300 млн транзисторов. Различные версии процессора Athlon могут содержать кэш-память второго уровня, расположенную на отдельной микросхеме и работающую на частоте, равной половине, двум пятым или одной трети частоты ядра, либо встроенную кэш-память меньшего объема, частота которой равняется частоте ядра.
Дата добавления: 2016-06-15; просмотров: 1923;
Поиск по сайту
Узнать еще
- I. ОСОБЕННОСТИ ДЕЛОВОГО И ЛИЧНОСТНОГО ОБЩЕНИЯ В СОВМЕСТНОЙ ДЕЯТЕЛЬНОСТИ
- I.2. Основные категории водопотребления промышленных предприятий и их особенности
- I.7.1 ПРЕОБРАЗОВАНИЯ ГАЛИЛЕЯ
- I.7.3 ПРЕОБРАЗОВАНИЯ ЛОРЕНЦА
- I2. Особенности аэродинамики несущего винта (НВ)
- II. Завоевание Китая маньчжурами. Экономическое положение страны в XVII – начале XIX вв.: аграрная политика Цинской династии, особенности развития городского ремесла
- II. Особенности политического устройства Ирана
- II. Особенности развития турецкой буржуазии. Становление младотурецкого движения

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
