Политикизаписиипродержкакогерентности
Если бы ячейки памяти были доступны только на чтение, то их скэшированная копия всегда совпадала бы с оригиналами. Возможность записи рождает следующие проблемы: во-первых, кэш-контроллер должен отслеживать модификацию ячеек кэш-памяти, выгружая в основную память модифицированные ячейки при их замещении, а, во-вторых, необходимо как-то отслеживать обращения всех периферийных устройств (включая остальные микропроцессоры в многопроцессорных системах) к основной памяти.
Кэш-контроллеробязанобеспечиватькогерентность(coherency) - согласованность кэш-памяти с основной памятью. Допустим, к некоторой ячейке памяти, уже модифицированной в кэше, но еще не выгруженной в основную память, обращается периферийное устройство (или другой процессор) - кэш-контроллер должен немедленно обновить основную память, иначе оттуда прочитаются "старые" данные. Аналогично, если периферийное устройство (другой процессор) модифицирует основную память, например посредством DMA, кэш-контроллер должен выяснить - загружены ли модифицированные ячейки в его кэш-память и, если да - обновить их.
Способы поддержки когерентности.
1. Сквозная (Write True write policy) политика - кэширование ячеек основной памяти при чтении и запись напрямую, минуя кэш, сразу в основную память. Сквозная политика легка в аппаратной реализации, но крайне неэффективна.
2. Сквозная запись с буферизацией (Write Combining write policy) - частично компенсирует задержки обращения к памяти с помощью буферизации. Записываемые данные на первом этапе попадают не в основную память, а в специальный буфер записи (store/write buffer), размером порядка 32 байт. Там они накапливаются до тех пор, пока буфер целиком не заполнится или не освободится шина, а затем все содержимое буфера записывается в память "одним скопом". Недостатком является то, что значительная часть процессорного времени по-прежнему расходуется именно на выгрузку буфера в основную память.
3. Более сложный (но и совершенный!) алгоритм реализует обратная политика записи (Write Back write policy), до минимума сокращающая количество обращений к памяти. Для отслеживания операций модификации с каждой ячейкой кэш-памяти связывается специальный флаг, называемый флагом состояния. Если кэшируемая ячейка была модифицирована, то кэш-контроллер устанавливает соответствующий ей флаг в грязное (dirty) состояние. Когда периферийное устройство обращается к памяти, кэш-контроллер проверяет флаг. Грязные ячейки выгружаются в основную память, а их флаг устанавливается в состояние "чисто" (clear). Аналогично при замещении старых кэш-строк новыми, кэш-контроллер в первую очередь стремится избавиться от чистых кэш-строк, т.к. они могут быть мгновенно удалены из кэша без записи в основную память. И только если все строки грязные - выбирается одна, наименее ценная (с точки зрения политики замещения данных) и "сбрасывается" в основную память, освобождая место для новой "чистой" строки.
ОсвобождениеКЭШ
Ещё одна особенность стратегии связана с тем, что кэш-память очень быстро оказывается полностью заполненной (занятой). Фактически это состояние наступает практически мгновенно, поэтому очередной попытке дублирования ячеек ОП в кэше должен предшествовать обратный процесс - освобождения части кэша для записи новой информации путем её переписи в ОП, на прежнее место.
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Как правило для замещения блоков применяются две основных стратегии: случайная и LRU.
1. С целью обеспечения равномерного распределения, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения. Достоинство заключается в том, что его проще реализовать в аппаратуре.
2. С целью уменьшения вероятности выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used). Когда количество блоков в КЭШ увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным.
4.Организацияадресных(сверхоперативных)запоминающихустройств
Запоминающая часть ЗУ организована как линейная последовательность ячеек, обращение к каждой из которых обеспечивается схемой селекции, построенной на основе дешифратора адреса DСА, демультиплесора DMS и мультиплексора MS. Выбор ячейки при выполнении операции записи осуществляется дешифратором DСА и демультиплексором DMS, а при чтении - DСА и MS.
Простейшая структура ЗУ с адресной организацией представлена на рис. 6.
DMS
Рис.6.СтруктураЗУсадреснойорганизацией
Такого рода ЗУ с адресной организацией принято называть ЗУ типа 2D, т.е. ЗУ с двумя измерениями (координатами): первая координата при обращении - адрес А, вторая - направление обмена - чтение или запись. Основой построения ЗУ типа 2D являются за-
на усили- поминающие элементы следующего вида
| Рис. 7
| теля записи
| (выходов DMS, входов MS). В силу этого недостатка ЗУ типа 2D используются лишь в тех случаях, когда количество ячеек памяти невелико, что как раз и характерно для
|
(рис. 7):
Каждый ЗЭ адресуемой ячейки выбирается сигналом выбора от DСА. Основной недостаток ЗУ типа 2D - сложная схема селекции и, следовательно, большие затраты оборудования на её реализацию. Сложность селектора пропорциональна емкости ЗУ 2m=E (пример: m=16, 216=64K), т.е. пропорциональна количеству выходов DСА
РОН: m=3 (4, 5) обычно.
Как упростить схему селекции? Один из простейших способов - использование матричной (двумерной) организации запоминающей части ЗУ. В результате получаем структуру ЗУ типа 3D (трехмерную организацию), в которой ячейки ЗУ адресуются (выбираются) двумя параметрами: номером строки и номером столбца в матрице (рис. 8).
Пример: m=16, E=216=64K ячеек, √E=28=256.
Сложность селектора: 2⋅2m/2 (в примере m=16, 2⋅28=512),т.е. в 27(128) раз меньше, чем для ЗУ типа 2D. В общем случае сложность селектора в 2(m/2-1) раз меньше, чем в ЗУ типа 2D.
Здесь выбор ячейки (и ЗЭ) осуществляется двумя сигналами выбора, поступающими одновременно с дешифратора номера строки (DСАст) и дешифратора номера столбца (DСАмл). Их совпадение выбирает адресуемый ЗЭ (рис.9).
В общем случае ЗУ с адресной организацией будем обозначать в виде, представленном на рис. 10.
записи
Рис. 10
Рис. 9
5.Запоминающиеустройствасассоциативнойорганизацией
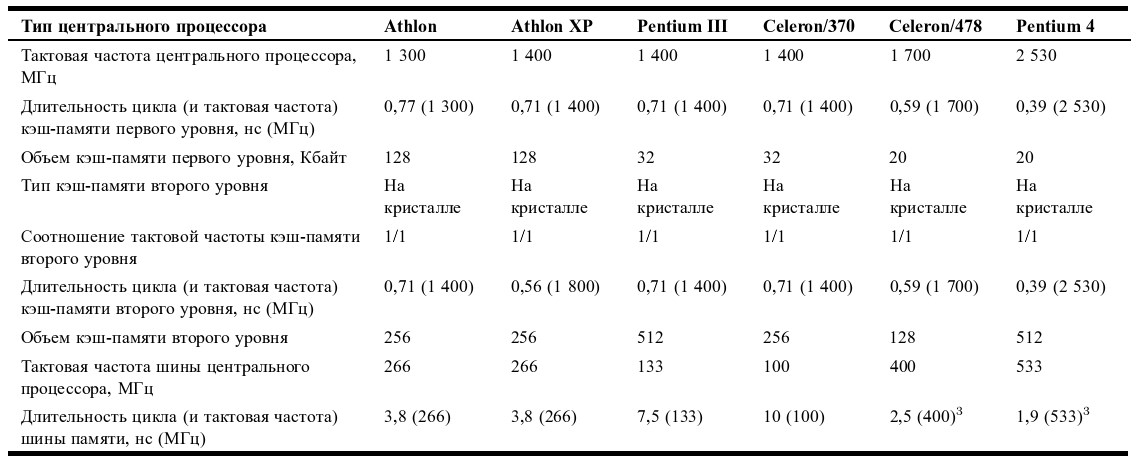
Ассоциативные ЗУ (АЗУ) относятся к ЗУ безадресного типа. В них доступ к ячейкам памяти осуществляется не по адресу, а по ассоциативному признаку. В качестве ассоциативного признака (АП) используются содержимое ячейки или её части. АЗУ состоит из трех частей:
1) запоминающей части, которая организована в виде совокупности ячеек с номерами 0, 1, …, Е-1;
2) блока ассоциативного поиска (доступа), т.е. схемы ассоциативного селектора;
3) блока замещения слов, который используется для записи информации в условиях, когда все ячейки АЗУ заняты (рис. 11).
Рис. 11.СтруктураАЗУ
Ячейки запоминающей части состоят из двух полей: поля ассоциативного признака АП и информационного поля ИП.
Поиск информации (т.е. доступ к ячейкам ИП) осуществляется по ассоциативному признаку, который подается на вход ассоциативного селектора, и ведется путем сравнения входного признака АП со всеми АП, которые хранятся в полях всех ячеек запоминающей части:
АП=АПi, i=0, 1, …Е-1.
Выбранной считается та (или те) ячейка (и), для которой (ых) совпали ассоциативные признаки. Если совпадений нет ни для одной ячейки, то это означает отсутствие в АЗУ той информации, обращение к которой производится по данному АП.
Таким образом, схема селекции в АЗУ организована на основе схем сравнения, а не дешифраторов, как в ЗУ с адресной организацией.
Блок управления замещением начинает работать в случае не сравнения и отсутствия свободных ячеек для записи. В этом случае блок назначает кандидата на удаление – указывает номер ячейки, содержимое которой следует удалить из памяти и на освободившееся место записать новую информацию, включая новый ассоциативный признак АП.
Если АЗУ используется в качестве кэш–буфера (между ЦП и ОП), то в этом случае в качестве ассоциативных признаков используются адреса ячеек (блоков) ОП, информация из которых дублируется в кэше. ’Скрытость’ кэша обеспечивается работой блока управления замещением, который реализует автоматический обмена с ОП. Наличие скрытой кэш–памяти с точки зрения программиста делает память как бы одноуровневой (виртуально одноуровневой): уровень СОП скрыт от пользователя.
Основной недостаток АЗУ – большие (колоссальные) затраты оборудования на реализацию ассоциативного селектора. В случае, если запоминающая часть устройства организована по принципу 2D, то сложность селектора определяется количеством схем сравнения: 2k=EАЗУ (количество которых совпадает с количеством ячеек устройства).
Сложность одной схемы сравнения m элементов сравнения (однобитных). Общая сложность селектора:
N2D=m2k
Пример: m=26, k=16, N2D=26*216
Как уменьшить сложность селектора? Использовать ЗУ типа 3D:
N3D=m*2k/2
В нашем примере: N3D=26*28, т.е. в 256 раз меньше (в общем случае в 2k/2 раз меньше).
6.Организациякэш–памятинаосновеассоциативногозапоминающегоустройства(кэшсассоциативнойорганизацией)
В этом случае всё пространство ОП разделяется на блоки (строки кэша) размером Естр=2n, n<<m, которые принимаются за единицу обмена кэша с ОП. Пример: m=26, n=5 (строка длиной 32 байта).
Всё пространство кэш–памяти также разделяется на строки ёмкостью 2n. В результате адреса ячеек ОП и кэша разделяются на поля:
1 m m=n+l, E=2l – количе-
ОП:ство строк в ОП
1 k
КЭШ:k=n+h, E=2h – количе-
Ство строк в кэше
Пример: m=36, n=5, l=21, k=16, h=11.
Структура кэш с ассоциативной организацией типа 3D представлена на рис.12.
Если ассоциативный признак Р=Р’, то обращение осуществляется к выбранной по ‘да’ строке кэша. Выбор ячейки в строке осуществляется при помощи дешифратора DСВ (в примере В=1), т.е. по адресному принципу.
Если Р≠Р’, то производится замещение: адресуемый блок Р извлекается из ОП и переписывается в свободную или специально освобождённую строку кэша. Освобождение строки кэша осуществляется путём её переписи обратно в ОП по старому адресу Р.
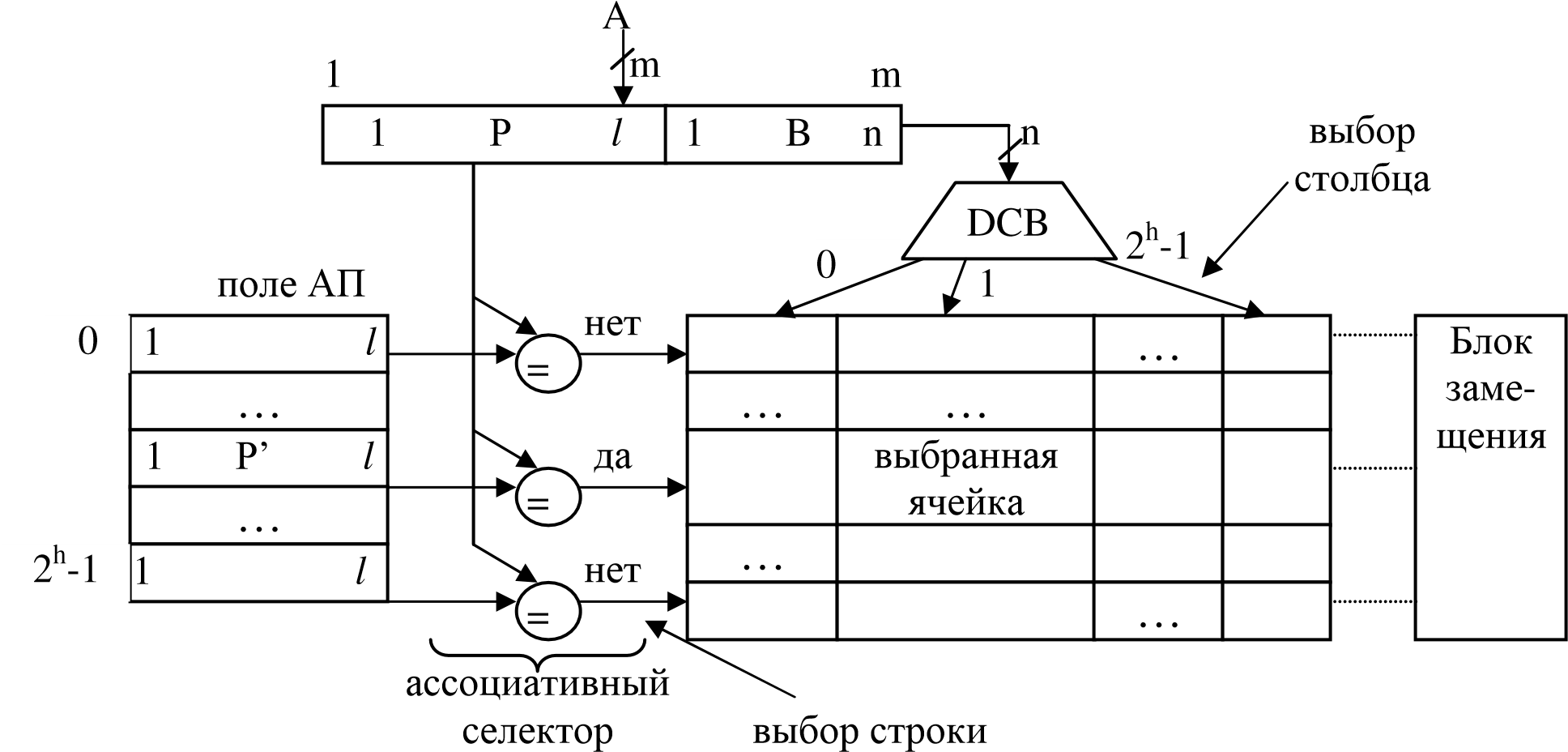
Рис. 12.Структуракэшсассоциативнойорганизацией
Основной недостаток – большие затраты оборудования на селектор. Пример: m=26, n=5, l=21, k=16, h=11, Nсел=l*2h=21*211=42K (K=210) элементов сравнения.
В силу указанного недостатка кэш с чисто ассоциативной организацией обычно не применяется. С целью экономии оборудования используется более простая организация – кэш с наборно–ассоциативной организацией (архитектурой) (рис.13). В этом случае адрес А ячейки ОП делится на 3 поля: в третьем (старшем) поле G указывается номер группы строк (в нашем примере t=10). В группу объединяются две (четыре, ...) строки.
Экономия оборудования достигается за счёт того, что ассоциативный поиск остаётся только в группе из r строк (в примере r = 2). Выбор же группы строк осуществляется по адресному принципу при помощи дешифратора DСР. Таким образом, количество схем сравнения уменьшается до r, т.е. до количества строк в группе, а разрядность схем сравнения уменьшается до t . В результате затраты оборудования на ассоциативный поиск сокращаются до величины: Nасс = rt (пример: r=2, t=10, N=20).
Кроме того, сокращается длина ячеек поля АП до t разрядов, что также экономит оборудование. Правда, появляется дополнительный дешифратор DСР с количеством входов 2h’, где h’=h-log2r (в примере h’=h-1=10). Количество строк в группе определяется уровнем мультипрограммирования: r = M.
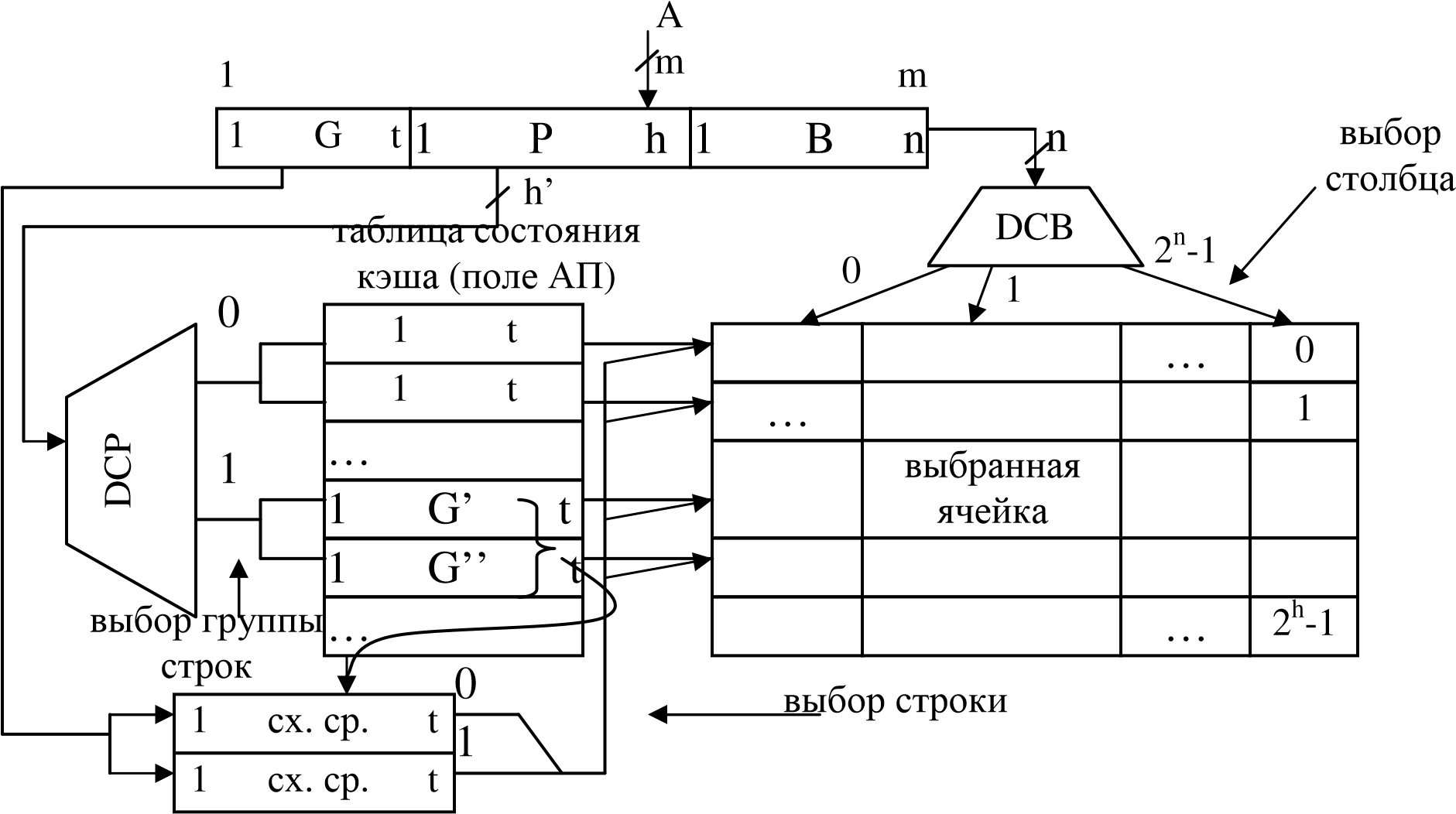
Рис.13
7.Организациястековых(магазинных)запоминающихустройств
ЗУ со стековой организацией широко используется при построении системы прерываний ЭВМ, а также при программировании алгоритмов, связанных с обработкой данных типа вектор, массив (переменных с индексами). Стековые ЗУ обеспечивают запись, чтение информации в соответствии с правилом: последним пришёл, первым вышел (LIFO). В них при обращении доступна только одна ячейка – т.н. вершина стека. При записи в стек слово сначала записывается в вершину стека, а затем проталкивается внутрь ЗУ и т.д. при записи очередных слов. При выполнении операции чтения слово сначала выталкивается в вершину стека, а затем подаётся на выходную шину ЗУ.
Технически такая память может быть реализована на основе сдвиговых регистров в количестве n – штук: количество сдвиговых регистров определяется разрядностью ячеек – n. Разрядность регистров сдвига определяется ёмкостью стека. Такая организация стека называется магазиннойпамятью(рис. 14). Одна из основных проблем магазинных ЗУ – переполнение стека, которое ведёт к потере информации, поэтому не допустимо. Следить за возможным переполнением должен сам программист.
Рис. 14.СтруктурамагазинныхЗУ
Недостаток ЗУ магазинного типа – большие затраты оборудования и, следовательно, высокая удельная стоимость: сдвиговые регистры сложнее обычных.
СтековыеЗУ по этой причине (с целью экономии оборудования) обычно организуются другим способом: вместо сдвига информации в них используется подвижный указатель вершины стека (УС). Структура стекового ЗУ представлена на рис.15. Операция записи осуществляется по сигналу ЗП: 1) ЗП: [УС]:=ВХ; 2) УС:=УС+1, т.е. сначала производится запись слова в вершину стека (в ячейку, на которую указывает УС), а затем УС инкрементируется. Операция чтения реализуется по сигналу чтения ЧТ: 1) УС:=УС-1; 2) ВЫХ:= [УС].
Рис. 15.
Технически УС реализуется на основе реверсивного счетчика. Следует отметить, что запоминающая часть стековых ЗУ обычно располагается в адресном пространстве ОП:
часть ячеек ОП отводится под стек.
8.Организацияпамятивторогоуровня(основнойоперативнойпамяти)
Основная память ЭВМ обычно организуется (строится) на основе микросхем памяти динамического типа (БИС ОЗУ типа DRAM), время обращения к которым в 3…5 раз больше, чем к ОЗУ статического типа (SRAM). Следует отметить, что часть ОП строится на базе БИС ПЗУ. Обычно для этих целей используются перепрограммируемые (репрограммируемые) микросхемы (БИС ППЗУ) с ультрафиолетовым или электрическим стиранием старой информации.
Основной особенностью динамических ОЗУ является разрушение информации при чтении и, следовательно, необходимость ее регенерации, что увеличивает время обращения при чтении и, следовательно, уменьшает быстродействие памяти. Кроме того, ячейка динамической памяти на может долго хранить информацию: в случае, когда достаточно долго не было обращений к ячейкам, также требуется регенерация, которая повторяется периодически. Для реализации процессов регенерации динамической памяти требуются дополнительные затраты оборудования на реализацию контроллеров регенерации.
Однако основной особенностью ОП является её многоблочная организация. Связано это с тем, что ёмкость отдельных БИС ЗУ ограничена, поэтому для построения ОП необходимого объёма приходится использовать несколько ЗУ, организованных в единое целое.
Определение. ООП ЭВМ – это совокупность ЗУ, охваченных общей схемой управления.
Почему ОП строится по многоблочной схеме? По двум причинам: технической и экономической.
Технические причины: ёмкость ОП при многоблочной организации можно наращивать практически неограниченно без дополнительного проектирования БИС и без уменьшения быстродействия, т.к. время обращения к многоблочной памяти будет практически таким же, как и время обращения к отдельным её блокам.
Экономическая причина: из однотипных блоков ЗУ, выпускаемых серийно, можно строить память необходимой ёмкости, стоимости и быстродействия. В противном случае необходимо было бы выпускать целую гамму ЗУ различных типов и размеров. При этом стоимость ОП будет выше, чем для случая однотипных блоков.
Простейшая структура многоблочной памяти представлена на рис. 16.
Здесь
Eоп=2m, Eбл=2k. Количество блоков 2l, m=k+l.
Формат адреса: 1 m
Выбор блока обеспечивается дешифратором DСВ.
Рис. 16.Структурамногоблочнойпамяти
Z – сигнал занятости памяти (блока ЗУ).
0−свободен (готов обслуживать запрос на обращение)
Z=
1−занят (не готов обслуживать)
Функционирование многоблочной памяти осуществляется следующим образом.
| ВК
| ЧТ
| ЗП
| Функция блока
|
|
| Х
| Х
|
Не выбран (выход D – в третьем состоянии, Zi=0)
Считывание данных: ШД=[A], Zi=1
Запись данных: [A]=ШД, Zi=1
|
Интерфейс многоблочной памяти: ШД, ША, ШУ, Z.
Z – осведомительный сигнал занятости - используется для организации асинхронной работы ЦП и ОП.
Таким образом, многоблочная память рассматривается как единое целое емкостью E = N*Ебл и быстродействием, которое определяется временем обращения: τобр =τDCB +τобрбл
Это время постоянно и не зависит от количества блоков N, т. е. не зависит от емкости ОП. Емкость можно наращивать без уменьшения быстродействия.
Следует отметить, что в каждый момент времени эта схема обеспечивает обслуживание только одного обращения, т. к. одновременно в ней может быть выбран только один из блоков. Поскольку в каждом блоке есть свой автономный блок управления (с дешифратором адреса), то потенциально многоблочная память могла бы обслуживать N обращений одновременно – за один цикл обращения – при условии, естественно, что каждый блок будет обслуживать свое обращение. В этом случае быстродействие многоблочной памяти может возрасти в N раз.
Как организовать такую память? Путем расслоения обращений. Суть - обслуживание обращений к ОП организуется таким образом, чтобы очередное по времени обращение к ней обслуживалось другим (свободным) блоком: первое обращение – i-м блоком, второе – j-м блоком, третье – k-м блоком и т. д. Необходимым условием такой организации является наличие в каждом блоке ЗУ двух буферных регистров – адреса РА и данных РД. Интерфейс памяти с расслоением обращений, конечно, будет сложнее, чем в простейшей структуре (с одной шиной адреса и одной шиной данных), т. е. он должен обеспечивать одновременный обмен с несколькими устройствами: многоблочная память с расслоением обращений выглядит как многопортовая память (двух, трех и т. д. портовая память).
Какие предпосылки для расслоения обращений? При обращении к ОП каждый из источников (ЦП, канал) обычно, т. е. чаще всего, обращается к ОП по соседним адресам: а, а+1, …, а+δа. Если ячейки а, а+1, …, а+δа располагаются в одном блоке, то расслоение обращений становится невозможным. Как быть? Поменять местами поля В и D в формате адреса А:
1 D k 1
т. е. младшие разряды адреса необходимо использовать в качестве номера блока многоблочной памяти. Такой способ расслоения обращений принято называть расслоениемадресов (по блокам).
Таким образом, многоблочная память с расслоением обращений обеспечивает одновременное обслуживание нескольких обращений (в пределе – N обращений), другими словами она обеспечивает большую ширину выборки: в пределе nN (вместо n) разрядов.
Понятие «ширина выборки» относится к линейной организации памяти. Однако в общем случае можно говорить об организации памяти, позволяющей хранить сложные (не линейные) структуры данных: массивы (одномерные – векторы, двумерные – матрицы и т. д.), а также структуры типа дерево. В этом случае вместо понятия «ширина выборки» следует говорить о единице обмена с ОП, для которой задается объем Е и формат F выборки (E,F). Например, можно говорить об одновременной выборке вектора a1 a2 … ak (E=k, F – вектор) или об одновременной выборке элемента дерева – объем Е – количество ветвей дерева, формат F – дерево.
9.Организацияпамятитретьегоуровня(внешнейпамяти)
Внешняя память ЭВМ – это сложная дисковая (обычно) система, работающая под управлением операционной системы.
Внешняя память строится на основе ВЗУ различных типов: НМД, НМЛ, НОД и др. Особенности ВЗУ: это ЗУ очень большой емкости, невысокого быстродействия и низкой удельной стоимости хранения информации. Пример: октябр
Дата добавления: 2016-06-15; просмотров: 1738;










