ЭМПИРИЧЕСКИЙ ПОДХОД В ЗАДАЧАХ С АПРИОРНОЙ НЕОПРЕДЕЛЕННОСТЬЮ.
ОБУЧЕНИЕ
Рассмотренные выше аналитические способы неполного статистического описания х и 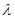 по существу соответствуют тому, что в каждой конкретной практической задаче создается некоторая аналитическая модель для описания статистических свойств х и с той степенью полноты и подробности, которая соответствует имеющимся знаниям о закономерностях их поведения, физических свойствах, взаимосвязи между собой. Подобная модель является в какой-то степени наиболее сжатым описанием имеющегося прошлого опыта, содержащего как результаты изучения указанных закономерностей, так и, возможно, эмпирические данные относительно х и .
по существу соответствуют тому, что в каждой конкретной практической задаче создается некоторая аналитическая модель для описания статистических свойств х и с той степенью полноты и подробности, которая соответствует имеющимся знаниям о закономерностях их поведения, физических свойствах, взаимосвязи между собой. Подобная модель является в какой-то степени наиболее сжатым описанием имеющегося прошлого опыта, содержащего как результаты изучения указанных закономерностей, так и, возможно, эмпирические данные относительно х и .
На практике бывает и так, что, кроме эмпирических данных, всякая иная априорная информация относительно х и отсутствует. Однако если эти данные получены в обстановке, статистически однородной или хотя бы статистически связанной с той, в которой принимается решение no данным наблюдения х, то они являются в определенной степени статистическим эквивалентом аналитических моделей для распределений вероятности х и , необходимых для нахождения оптимального правила принятия решения. Степень этой эквивалентности, естественно, зависит от объема имеющихся эмпирических данных, которые, в свою очередь, могут быть использованы по-разному: непосредственно для нахождения недостающих распределений вероятности, для оценки функциональной зависимости апостериорного риска от х и решения u, для уточнения структуры и параметров решающего правила (алгоритма обработки данных наблюдения х). Процедуру использования эмпирических данных, которые характеризуют прошлый опыт, обычно называют обучением, а соответствующие алгоритмы — обучаемыми.
Для того чтобы яснее представить себе возможный качественный состав имеющихся эмпирических данных и возможные способы их использования при синтезе систем в условиях априорной неопределенности, предположим, что имеется серия повторяющихся ситуаций, статистически однородных или хотя бы статически связанных с той, в которой мы должны принимать решение. Последняя (в соответствии с гл. 2) характеризуется значением параметра , определяющего величину потерь 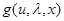 при принятии решения u, и данными наблюдения х, на основе которых принимается решение в соответствии с правилом u = u(x). Пусть теперь имеется N ситуаций, сходных или связанных с основной, в которых получены те или иные эмпирические данные. Каждая из них для
при принятии решения u, и данными наблюдения х, на основе которых принимается решение в соответствии с правилом u = u(x). Пусть теперь имеется N ситуаций, сходных или связанных с основной, в которых получены те или иные эмпирические данные. Каждая из них для 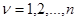 характеризуется значением параметров
характеризуется значением параметров 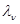 , имеющих ту же природу, состав и содержание, что и параметры . Иными словами, если для ситуации, в которой принимается интересующее нас решение,
, имеющих ту же природу, состав и содержание, что и параметры . Иными словами, если для ситуации, в которой принимается интересующее нас решение, 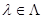 , где
, где 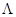 - множество возможных значений параметров , то и каждое из значений является одним из возможных элементов множества ; если имеет распределение с плотностью
- множество возможных значений параметров , то и каждое из значений является одним из возможных элементов множества ; если имеет распределение с плотностью 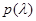 , то и каждое из значений имеет то же распределение.
, то и каждое из значений имеет то же распределение.
В общем случае эмпирические данные представляют собой совокупность значений 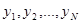 , каждая из составляющих
, каждая из составляющих 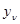 этой совокупности соответствует значению и может содержать тот или иной объем сведений. Характер, значимость и способы использования этих сведений существенно различаются в зависимости от того, производится ли в
этой совокупности соответствует значению и может содержать тот или иной объем сведений. Характер, значимость и способы использования этих сведений существенно различаются в зависимости от того, производится ли в 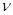 -й ситуации только наблюдение и регистрация каких-либо данных (аналогичных х для основной рабочей ситуации либо как-то отличающихся от х) или наряду с наблюдением, так же как в рабочей ситуации, осуществляется принятие решения
-й ситуации только наблюдение и регистрация каких-либо данных (аналогичных х для основной рабочей ситуации либо как-то отличающихся от х) или наряду с наблюдением, так же как в рабочей ситуации, осуществляется принятие решения 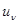 с вытекающими отсюда последствиями. Согласно принятой терминологии, в первом случае говорят о простом обучении, а во втором - о «рабочеподобном». Смысл последнего термина связан с тем, что при получении эмпирических данных воспроизводится не только ситуация, характеризуемая значением параметра , определяющим потери, но и сам процесс решения, подобный тому, который должен быть выполнен в рабочей ситуации. Это является принципиальной основой для получения информации о конкретной величине потерь от принятия решения на каждом -м шаге и использования этой информации для улучшения правила принятия решения на рабочем шаге.
с вытекающими отсюда последствиями. Согласно принятой терминологии, в первом случае говорят о простом обучении, а во втором - о «рабочеподобном». Смысл последнего термина связан с тем, что при получении эмпирических данных воспроизводится не только ситуация, характеризуемая значением параметра , определяющим потери, но и сам процесс решения, подобный тому, который должен быть выполнен в рабочей ситуации. Это является принципиальной основой для получения информации о конкретной величине потерь от принятия решения на каждом -м шаге и использования этой информации для улучшения правила принятия решения на рабочем шаге.
Рассмотрим более полно возможный состав эмпирических данных - совокупности 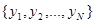 для различных случаев. Заметим, что эта совокупность часто называется обучающей последовательностью.
для различных случаев. Заметим, что эта совокупность часто называется обучающей последовательностью.
Простое обучение
1. Самый простой случай эмпирической статистики - это случай, когда в серии из N независимых наблюдений получены значения 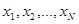 , где каждая из составляющих
, где каждая из составляющих 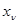 тождественна с точки зрения объема и содержания наблюдаемых данных величине х, получаемой в рабочей ситуации, а значения для известны. В этом случае любая из составляющих совокупности эмпирических данных представляет собой пару
тождественна с точки зрения объема и содержания наблюдаемых данных величине х, получаемой в рабочей ситуации, а значения для известны. В этом случае любая из составляющих совокупности эмпирических данных представляет собой пару 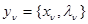 , где подчиняется тому же условному распределению вероятности (полностью или частично неизвестному), что и х. Совместное условное распределение вероятности для совокупности значений иданных наблюдения х в рабочей ситуации может быть описано плотностью вероятности
, где подчиняется тому же условному распределению вероятности (полностью или частично неизвестному), что и х. Совместное условное распределение вероятности для совокупности значений иданных наблюдения х в рабочей ситуации может быть описано плотностью вероятности
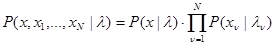 , (3.3.1)
, (3.3.1)
где 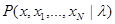 - всюду одна и та же функция;
- всюду одна и та же функция; 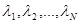 известны,
известны,
а , определяющая величину потерь в рабочей ситуации, неизвестна. В частном случае дискретного множества значений ( 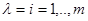 ) последовательность иногда удобно разбить на последовательности
) последовательность иногда удобно разбить на последовательности 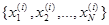 (
( 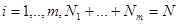 ), соответствующие имеющимся эмпирическим данным для каждого из значений
), соответствующие имеющимся эмпирическим данным для каждого из значений 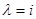 . Заметим, что случай, когда на каждом -м шаге в процессе эмпирического набора данных наряду с результатом наблюдения становится известным и истинное состояние ситуации, характеризуемое параметрами , называется иногда обучением с учителем.
. Заметим, что случай, когда на каждом -м шаге в процессе эмпирического набора данных наряду с результатом наблюдения становится известным и истинное состояние ситуации, характеризуемое параметрами , называется иногда обучением с учителем.
2. Следующий характерный случай, когда каждая из составляющих эмпирической совокупности по-прежнему тождественна по объему и содержанию величине х, но значения параметров неизвестны, то есть истинная ситуация, в которой наблюдается , остается неизвестной. При этом также предполагается, что все ситуации для 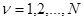 , в которых получены эмпирические данные и рабочая ситуация статистически однородны, то есть все для и имеют одно и то же распределение вероятности. Совместное распределение вероятности { }и х при заданном значении , для рабочей ситуации в этом случае может быть описано следующей плотностью:
, в которых получены эмпирические данные и рабочая ситуация статистически однородны, то есть все для и имеют одно и то же распределение вероятности. Совместное распределение вероятности { }и х при заданном значении , для рабочей ситуации в этом случае может быть описано следующей плотностью:
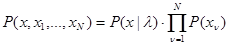 , (3.3.2)
, (3.3.2)
где 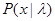 - функция правдоподобия (полностью либо частично неизвестная), а
- функция правдоподобия (полностью либо частично неизвестная), а
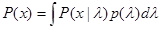 , (3.3.3)
, (3.3.3)
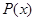 - плотность безусловного распределения вероятности х, неопределенность которой может быть еще большей, чем функции правдоподобия, из-за частичного либо полного незнания априорного распределения
- плотность безусловного распределения вероятности х, неопределенность которой может быть еще большей, чем функции правдоподобия, из-за частичного либо полного незнания априорного распределения
параметров (плотности ).
3. Более общий случай имеет место, если в процессе набора эмпирических данных наблюдаются величины не обязательно тождественные по объему и содержанию х и , но связанные с ними известной функциональной либо более общей вероятностной зависимостью. Это означает, что любая из составляющих может быть описана условным распределением вероятности с плотностью 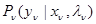 , которое может быть полностью или частично неизвестным (при наличии функциональной зависимости указанная плотность дельтообразна), а полная совокупность эмпирических данных { } и данных наблюдения х в рабочей ситуации имеет условное (при заданном ) распределение с плотностью вероятности
, которое может быть полностью или частично неизвестным (при наличии функциональной зависимости указанная плотность дельтообразна), а полная совокупность эмпирических данных { } и данных наблюдения х в рабочей ситуации имеет условное (при заданном ) распределение с плотностью вероятности
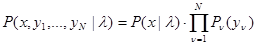 , (3.3.4)
, (3.3.4)
где
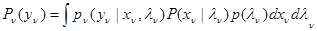 . (3.3.5)
. (3.3.5)
Величины могут представлять собой, например, отдельные компоненты полного вектора данных наблюдения х (не обязательно одинаковые при разных ), результат наблюдения с дополнительными помехами и ошибками или, наоборот, в лучших по сравнению с рабочей ситуацией условиях и т. п.
Следует отметить, что независимость отдельных составляющих совокупности эмпирических данных, которая использована при записи (3.3.1), (3.3.2), (3.3.4), не имеет принципиального значения. Важно лишь существование той или иной степени статистического подобия между рабочей ситуацией и ситуациями, в которых получены эмпирические данные, а распространение рассуждений на случай зависимости и х сводится лишь к соответствующему изменению формы записи совместных распределений вероятности.
На основании проведенного выше рассмотрения можно зафиксировать несколько существенных моментов.
а). Совокупность эмпирических данных { } имеет ценность с точки зрения принятия решения в рабочей ситуации только в том случае, если имеется априорная неопределенность относительно статистического описания х и . Действительно, если и известны, то,,
как следует из выражений для среднего и апостериорного риска гл. 2 и выражений (3.3.1), (3.3.2), (3.3.4), расширение полной совокупности данных наблюдения за счет использования эмпирических данных
( }, то есть увеличение входной информации с заменой х на совокупность { 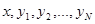 }, не изменяет ни оптимального правила решения и (оно остается зависящим только от х), ни величины
}, не изменяет ни оптимального правила решения и (оно остается зависящим только от х), ни величины
соответствующего ему риска. Это совершенно естественно, поскольку данные прошлых наблюдений { } не содержат непосредственно сведений о значении ненаблюдаемых параметров , определяющих величину потерь от принятия того или иного решения. Если неопределенность относится только к априорному распределению вероятности ( известно), не имеют ценности эмпирические данные 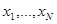 при обучении с учителем (в этом случае полезны только значения {
при обучении с учителем (в этом случае полезны только значения { 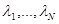 }, несущие информацию о структуре ).
}, несущие информацию о структуре ).
Сформулированные выводы в равной степени относятся как к простому обучению, так и к «рабочеподобному»
б).Для описания частично или полностью неизвестных распределений вероятности совокупности х и эмпирических данных 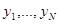 могут быть использованы все обсуждавшиеся в § 3.1, 3.2 методы и, в частности, с успехом применены рассмотренные в § 3.2 методы параметрического описания в случае ограниченных априорных значений. При этом эмпирические данные являются источником информации о неизвестных значениях параметров
могут быть использованы все обсуждавшиеся в § 3.1, 3.2 методы и, в частности, с успехом применены рассмотренные в § 3.2 методы параметрического описания в случае ограниченных априорных значений. При этом эмпирические данные являются источником информации о неизвестных значениях параметров 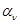 и
и 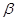 функции правдоподобия и априорного распределения вероятности .
функции правдоподобия и априорного распределения вероятности .
в). Наличие эмпирических данных , полученных простым .наблюдением без принятия решения в каждой -й ситуации (простое обучение), нисколько не изменяет исходную постановку задачи статистического решения и ее общую формулировку как в байесовом случае, так и при наличии априорной неопределенности. Действительно, так как потери зависят только от значения параметров , в рабочей ситуации (и не зависят от , 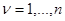 ), назовем совокупностью данных наблюдения х и то, что мы раньше обозначали этой буквой и вместе с ним все остальные имеющиеся данные, полученные в процессе эмпирического изучения статистики, то есть произведем переобозначение
), назовем совокупностью данных наблюдения х и то, что мы раньше обозначали этой буквой и вместе с ним все остальные имеющиеся данные, полученные в процессе эмпирического изучения статистики, то есть произведем переобозначение 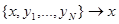 . Поскольку конкретное содержание совокупности х не было ограничено, то естественно, что от такого переобозначения ничего не изменится. Поэтому специальное выделение совокупности данных { }, отражающих прошлый опыт, имеет весьма ограниченное значение, а терминология, связанная с понятием обучения, может быть удобна только из-за наглядности рассуждений.
. Поскольку конкретное содержание совокупности х не было ограничено, то естественно, что от такого переобозначения ничего не изменится. Поэтому специальное выделение совокупности данных { }, отражающих прошлый опыт, имеет весьма ограниченное значение, а терминология, связанная с понятием обучения, может быть удобна только из-за наглядности рассуждений.
Забегая вперед, необходимо отметить, что этот вывод справедлив и для «рабочеподобного» обучения, если потери во всех ситуациях ( ), за исключением рабочей, равны нулю или несущественны.
Дата добавления: 2018-05-10; просмотров: 1680;
Поиск по сайту
Узнать еще
- IDEA NXT - новый подход в технологиях блочного симметричного шифрования
- III. Психологический подход
- Адаптация. Общее понятие и подходы к изучению. Виды адаптации.
- АДАПТИВНЫЙ БАЙЕСОВ ПОДХОД ПРИ ПАРАМЕТРИЧЕСКОЙ АПРИОРНОЙ НЕОПРЕДЕЛЕННОСТИ
- Альтернативные подходы к фискальной политике
- АМО предоставляют диспетчерским органам подхода (ДОП) или органу (сектору)
- Анализ подходов прогнозной экстраполяции
- Бать М.И., Джанелидзе Г.Ю., Кельзон А.С. Теоретическая механика в примерах и задачах. Ч.1 и 2. М., 1961 и последующие издания

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
