Методы сжатия дискретных сообщений
Условия существования оптимального неравномерного кода.При передаче сообщения необходимо согласовывать источник с каналом путем определения правила, по которому каждому элементу сообщения ставится в соответствие некоторый код, преобразуемый далее в сигнал.
В настоящее время существует два основных направления развития теории кодирования:
1) В одном из них рассматриваются задачи повышения достоверности передачи в каналах с помехами, решаемые применением помехоустойчивых кодов, которые позволяют обнаруживать или исправлять ошибки. Такое кодирование называется помехоустойчивым. При этом избыточность кодовой последовательности выше, чем избыточность источника сообщений.
2) Другое направление теории кодирования связано с вопросами устранения избыточности при передаче сообщений в каналах без помех. Цель кодирования при этом состоит в таком преобразовании сообщения, при котором избыточность кодовой последовательности должна стать меньше, чем избыточность сообщений источника. В результате появляется возможность увеличения скорости передачи информации или снижаются требования к пропускной способности канала.
Процесс кодирования с целью уменьшения избыточности источника сообщений называется согласованием источника с каналом, или сжатием сообщения источника (экономного кодирования, энтропийного кодирования).
Количественно избыточность оценивается коэффициентом избыточности:
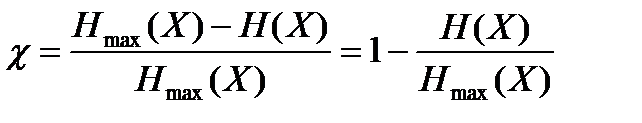 , (15.5)
, (15.5)
где H(X) – энтропия источника;
Hmax(X) = log2m – максимальная энтропия источника с алфавитом из m сообщений.
Избыточность (15.5) равна нулю только в том случае, когда элементы сообщения появляются на выходе источника с равными вероятностями p(xi) = 1/m (i = 1, 2, 3,…, m) и независимо друг от друга p(xi,xj) = p(xi) · p(xj). Если же H (X) < log2m, то оказывается возможным построение кодов, имеющих меньшую избыточность, чем источник сообщений.
Покажем это на простейшем примере.
Пусть источник имеет алфавит из четырех символов А, Б, В, Г с вероятностями p(A) = 0,5; p(Б) = 0,25; p(B) = p(Г) = 0,125.
Энтропия такого источника:
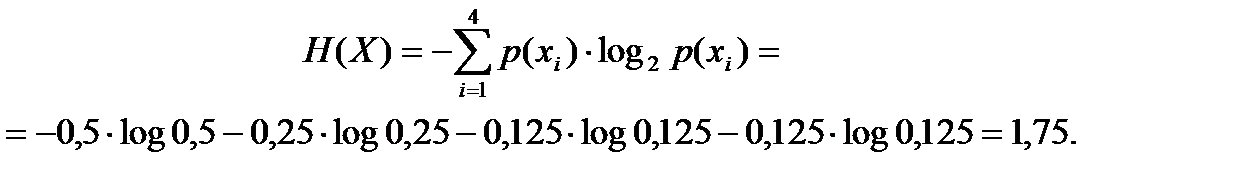
При использовании равномерного кодирования, например, А → 00, Б → 01, В → 10, Г → 11. Тогда среднее число двоичных символов в сообщении, приходящихся на один символ источника, равно двум. Поскольку это на 12,5% больше энтропии источника, то используемый код не является оптимальным.
Рассмотрим теперь неравномерный код: А → 0, Б → 10, В → 110, Г → 111. В этом случае среднее число двоичных символов, приходящихся на один символ источника в сообщении,
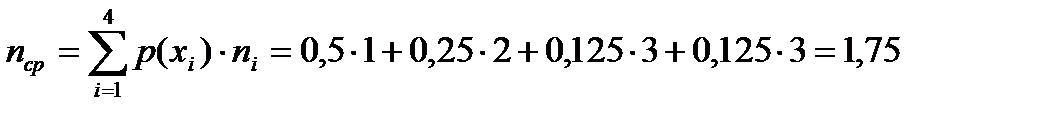 .
.
Таким образом, среднее число двоичных символов, приходящихся на один символ источника, равно энтропии источника, т.е. для указанного источника неравномерный код оказывается более экономичным, чем равномерный.
Важно отметить, что при кодировании неравномерным кодом должна обеспечиваться возможность однозначного декодирования символов сообщения.
Например, для рассмотренного источника, нецелесообразно применять код: А → 0, Б → 1, В → 10, Г → 11, поскольку прием последовательности 10 может означать передачу символа В, или двух символов Б и А. Неоднозначно также декодирование символов 11. Для однозначного декодирования неравномерные коды должны удовлетворять условию префиксности: никакое более короткое слово не должно являться началом более длинного слова. Неравномерные коды, удовлетворяющие этому условию, называют префиксными.
Неравномерные коды позволяют в среднем уменьшить число двоичных символов на единичное информационное сообщение. Однако им присущ существенный недостаток: при возникновении ошибки она распространяется на все последующие элементы сообщения. Возникает ошибка синхронизации, приводящая к резкому ухудшению достоверности приема.
Этот недостаток отсутствует в равномерных кодах. При кодировании равномерными кодами используется одно и то же число двоичных символов – блок; поэтому такие коды называют блоковыми.
Показатели эффективности сжатия. Наряду с коэффициентом избыточности (15.5), часто используется коэффициент сжатия источника:
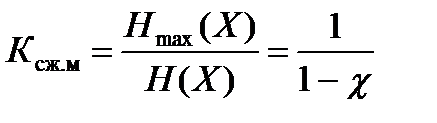 .
.
Коэффициент сжатия источника показывает, во сколько раз можно уменьшить количество двоичных символов для представления единичного символа источника с энтропией H(X) по сравнению со случаем, когда все сообщения источника передаются равновероятно.
Например, для источника, рассмотренного выше, коэффициент сжатия
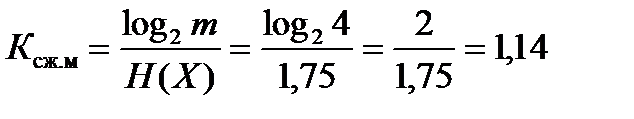 ,
,
т.е. скорость передачи информации по каналу связи при использовании экономичного кодирования может быть в 1,14 раза больше, чем при равномерном кодировании.
Кодирование источника дискретных сообщений методом Шеннона-Фано.Кодирование методом Шеннона-Фано рассмотрим на примере. Пусть алфавит источника содержит шесть элементов {А, Б, В, Г, Д, Е}, появляющихся с вероятностями p(A) = 0,15; p(Б) = 0,25; p(B) = 0,1; p(Г) = 0,13; p(Д) = 0,25; p(Е) = 0,12.
Энтропия такого источника:
H(X) = -0,15·log2 0,15 - 0,25·log2 0,25 - 0,1·log2 0,1 - 0,13·log2 0,13 - - 0,25·log2 0,25 - 0,12·log2 0,12 = 2,492.
Алгоритм построения сжимающего кода Шеннона-Фано заключается в следующем.
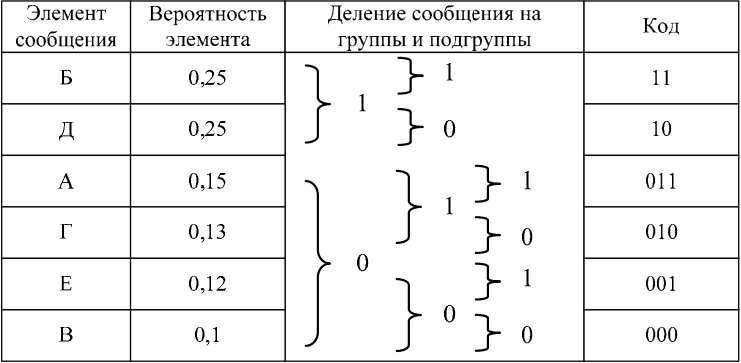
1. Все m символов дискретного источника располагаются в порядке убывания вероятностей их появления (таблица 15.1).
2. Образованный столбец символов делится на две группы таким образом, чтобы суммарные вероятности каждой группы мало отличались друг от друга.
3. Верхняя группа кодируется символом «1», а нижняя – «0».
4. Каждая группа делится на две подгруппы с близкими суммарными вероятностями; верхняя подгруппа кодируется символом «1», а нижняя – «0».
5. Процесс деления и кодирования продолжается до тех пор, пока в каждой подгруппе не окажется по одному символу сообщения источника.
6. Записывается код для каждого символа источника; считывание кода осуществляется слева направо.
Таблица 15.1
Построение кода Шеннона-Фано
При использовании простейшего равномерного кода для кодирования шести элементов алфавита источника потребуется по три двоичных символа на каждую букву сообщения. Если же используется код Шеннона-Фано, то среднее число символов на одну букву
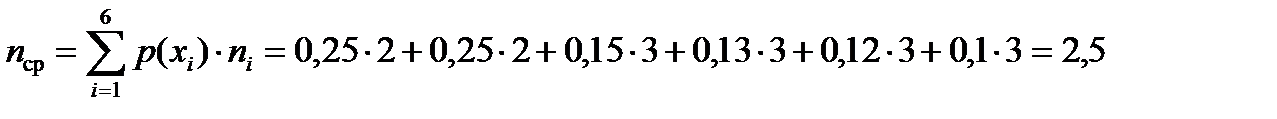 ,
,
что меньше, чем при простейшем равномерном коде и незначительно отличается от энтропии источника.
Кодирование источника дискретных сообщений методом Хаффмена.Рассмотрим еще один подход к кодированию, предложенный Хаффменом, на примере источника сообщений, заданного в таблице 15.2.
Алгоритм построения сжимающего кода Хаффмена включает в себя следующие действия.
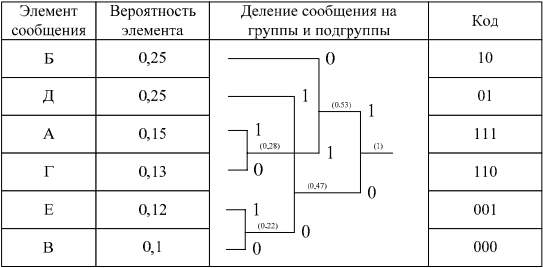
1. Все m символов дискретного источника располагаются в таблице в порядке убывания вероятностей.
2. Два символа, имеющих наименьшие вероятности, объединяются в один блок, а их вероятности суммируются.
3. Ветви скобки, идущей к большей вероятности, присваивается символ «1», а идущей к меньшей – символ «0».
4. Операции 2 и 3 повторяются до тех пор, пока не сформируется один блок с вероятностью единица.
5. Записывается код для каждого символа источника; при этом считывание кода осуществляется справа налево.
Таблица 15.2
Построение кода Хаффмена
Среднее число символов на одну букву для полученного кода
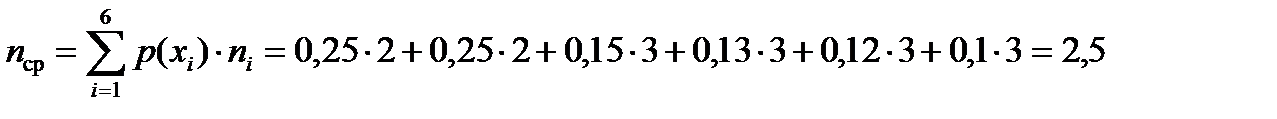 .
.
Таким образом, для данного примера кодирование методами Хаффмена и Шеннона-Фано одинаково эффективно. Однако опыт кодирования показывает, что код Хаффмена часто оказывается экономичнее кода Шеннона-Фано.
Длина кодовой комбинации таких кодов зависит от вероятности выбора соответствующей буквы алфавита: наиболее вероятным буквам сопоставляются короткие кодовые комбинации, а менее вероятным – более длинные.
Дата добавления: 2017-10-04; просмотров: 4131;
Поиск по сайту
Узнать еще
- I. История открытия и методы исследования вирусов
- II. Категории и методы политологии.
- III. Методы искусственной физико-химической детоксикации.
- Абсолютный возраст горных пород и методы его определения
- Автоматические методы изготовления фотошаблонов.
- Агротехнические методы (приемы) обработки почвы.
- Адиабатная работа сжатия воздуха в ступени.
- Административные методы управления природопользованием

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
