Тема: «Методы сравнительной статистики»
Наиболее часто встречающейся и достаточно сложной математико-статистической задачей является сравнение данных, полученных в процессе наблюденийили экспериментов, в выборочных совокупностях. Исследователь старается описать результаты наблюдения количественными методами и «на выходе» получает числовой массив тех или иных доступных ему измерений – вариационный ряд. Однако, как правило, содержащаяся в результатах измерений содержательная информация, имеет гораздо большую ценность при сравнении ее с аналогичной информацией, но полученной некоторым иным образом. Например, это может быть ситуация сравнения опытных данных (когда мы как-то повлияли на изучаемый объект или явление) с контрольной группой, в которой никакого воздействия на объект наблюдения не было. Возможно и сравнение двух вариантов опытов. Возможно сравнение двух серий наблюдений, разделенных в пространстве и времени и т.п.
Допустим, что удается заметить какие-либо численные различия в характеристиках сравниваемых рядов. Первым делом возникает вопрос: какова вероятность, что эти различия неслучайны и будут систематически повторяться в дальнейшем при воспроизведении условий эксперимента или наблюдения, т.е. выявленные различия являются статистически значимыми.
Выбор подходящего метода сравнения выборочных совокупностей определяется несколькими факторами: характером сравниваемых признаков (качественные или количественные), числом сопоставляемых групп, зависимостью или независимостью выборок, а также видом распределения признака.
Выборки являются независимыми, если набор объектов исследования в каждую из групп осуществлялся независимо от того, какие объекты исследования включены в другую группу. Так, в частности, происходит при рандомизации, когда распределение объектов происходит случайным образом. Примером сравнения независимых выборок может служить сопоставление данных анализа крови в группе пациентов с аналогичными показателями в группе здоровых.
Группы являются зависимыми (связанными)в динамических исследованиях, когда изучаются одни и те же объекты в разные моменты времени. Например, показатели анализа крови у одних и тех же пациентов до и после лечения.
От вида распределения и типа исследуемого признака зависит выбор подходящего математико-статистического критерия. Критерии делятся на два типа – параметрические и непараметрические.
Параметрические критерии – критерии, основанные на оценке параметров распределения, к которым относятся среднее арифметическое, среднеквадратическое отклонение, дисперсия. Они применимы только в том случае, если численные данные подчиняются нормальному распределению. Если распределение отличается от нормального, то следует пользоваться так называемыми непараметрическими критериями.
Непараметрические критерии не основаны на оценке параметров распределения и вообще не требуют, чтобы данные подчинялись какому-то определенному типу распределения. Непараметрические критерии дают более грубые оценки, чем параметрические, но являются более универсальными. А параметрические методы более точны, но лишь в случае, если правильно определено распределение совокупности.
Перед тем как перейти к рассмотрению статистических критериев, введем понятия нулевойи альтернативной гипотез, которые нам потребуются в дальнейшем.
На каждом шаге процесса анализа данных выдвигаются две гипотезы. Первая обозначается 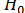 и называется нулевой гипотезой. Вторая гипотеза обозначается
и называется нулевой гипотезой. Вторая гипотеза обозначается 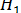 и носит название альтернативной, т.е. противоположной по смыслу. Под «нулевой гипотезой» подразумевается допущение об отсутствии того или иного интересующего исследователя события, явления или эффекта, а под «альтернативной» – о его наличии. Обе гипотезы, как бы они не были сформулированы, обязательно должны иметь взаимоисключающеесодержание.
и носит название альтернативной, т.е. противоположной по смыслу. Под «нулевой гипотезой» подразумевается допущение об отсутствии того или иного интересующего исследователя события, явления или эффекта, а под «альтернативной» – о его наличии. Обе гипотезы, как бы они не были сформулированы, обязательно должны иметь взаимоисключающеесодержание.
Нулевая гипотеза не может быть отвергнута, если ее вероятность окажется выше некого наперед заданного уровня α, достаточно близкого к 0, т.е. 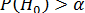 . Эта величина α носит название уровень значимости нулевой гипотезы.
. Эта величина α носит название уровень значимости нулевой гипотезы.
Альтернативная гипотеза может быть принята лишь в том случае, если ее вероятность достигнет некого наперед заданного уровня β или превзойдет его, т.е. 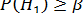 . Эта величина β – уровень доверительной вероятности. Он соответствует «уровням безошибочных прогнозов», т.е. вероятностям 0.95, 0.99 и 0.999 (область практически достоверных событий). Соответственно, α очерчивает область практически невозможных событий с порогами вероятностей 0.05, 0,01 и 0.001.
. Эта величина β – уровень доверительной вероятности. Он соответствует «уровням безошибочных прогнозов», т.е. вероятностям 0.95, 0.99 и 0.999 (область практически достоверных событий). Соответственно, α очерчивает область практически невозможных событий с порогами вероятностей 0.05, 0,01 и 0.001.
Поскольку 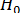 и – альтернативные гипотезы, то их суммарная вероятность равна единице. Следовательно, рост вероятности одной из гипотез автоматически приводит к снижению вероятности другой. Например, если
и – альтернативные гипотезы, то их суммарная вероятность равна единице. Следовательно, рост вероятности одной из гипотез автоматически приводит к снижению вероятности другой. Например, если 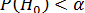 , это означает то, что будет выполняться условие
, это означает то, что будет выполняться условие 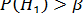 . И в этом случае нулевая гипотеза может быть отвергнута как событие практически невозможное, а альтернативная должна быть принята как событие практически достоверное. Если же , то
. И в этом случае нулевая гипотеза может быть отвергнута как событие практически невозможное, а альтернативная должна быть принята как событие практически достоверное. Если же , то 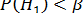 . И в этой ситуации нулевая гипотеза не может быть отвергнута, а альтернативная не может быть принята.
. И в этой ситуации нулевая гипотеза не может быть отвергнута, а альтернативная не может быть принята.
Например, в процессе исследования ставится задача доказать наличие статистически значимых различий между результатами наблюдений в опытной и контрольной группах. Это значит, что данные, полученные при применении того или иного статистического критерия, должны позволить отвергнуть нулевую гипотезу об отсутствии указанных различий.
Дата добавления: 2016-06-05; просмотров: 2821;
Поиск по сайту
Узнать еще
- Банківська система: принципи побудови, цілі, механізм функціонування
- Банковская система: структура, цели и основные функции
- Денежная система: сущность и типы. Денежная реформа.
- К ЗАНЯТИЮ № 2. ТЕМА: ОБЩАЯ ХАРАКТЕРИСТИКА АНТИГЕНОВ.
- Краткие сведения из сравнительной анатомии и эмбриологии
- ЛЕКЦІЯ 2.ТЕМА: ФІЗІОЛОГІЯ МІКРООРГАНІЗМІВ
- Лекція 3. Тема: Мікробіологічні основи екології навколишнього середовища.
- Лекція 3.Тема: Мікробіологічні основи екології навколишнього середовища.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
