Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Рассмотрим алфавит из восьми букв. Ясно, что при обычном (не учитывающем статистических характеристик) кодировании для представления каждой буквы требуется три символа.
Наибольший эффект сжатия получается в случае, когда вероятности букв представляют собой целочисленные отрицательные степени двойки. Среднее число символов на букву в этом случае точно равно энтропии. Убедимся в этом, вычислив энтропию: 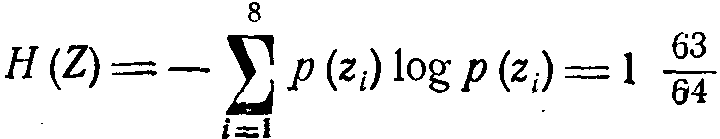 и среднее число символов на букву
и среднее число символов на букву 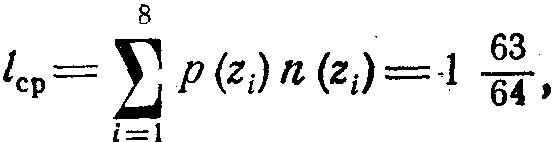 где n(Zi) —число символов в кодовой комбинации[14], соответствующей букве Zi. Характеристики такого ансамбля и коды букв представлены в таблице 3.4.
где n(Zi) —число символов в кодовой комбинации[14], соответствующей букве Zi. Характеристики такого ансамбля и коды букв представлены в таблице 3.4.
Таблица 3.4.
| Буквы | Вероятности | Ступени разбиения | Кодовые комбинации | ||||||
| Z1 | 1/2 | ||||||||
| Z2 | 1/4 | ||||||||
| Z3 | 1/8 | ||||||||
| Z4 | 1/16 | ||||||||
| Z5 | 1/32 | ||||||||
| Z6 | 1/64 | ||||||||
| Z7 | 1/128 | ||||||||
| Z8 | 1/128 |
В более общем случае для алфавита из восьми букв среднее число символов на букву будет меньше трех, но больше энтропии алфавита H(Z). Для ансамбля букв, приведенного в таблице 3.5, энтропия равна 2,76, а среднее число символов на букву 2,84.
Таблица 3.5
| Буквы | Вероят-ности | Ступени разбиения | Кодовые комбинации | ||||||
| Z1 | 0,22 | ||||||||
| Z2 | 0,20 | ||||||||
| Z3 | 0,16 | ||||||||
| Z4 | 0,16 | ||||||||
| Z5 | 0,10 | ||||||||
| Z6 | 0,10 | ||||||||
| Z7 | 0,04 | ||||||||
| Z8 | 0,02 |
Следовательно, некоторая избыточность в последовательностях символов осталась. Из теоремы Шеннона следует, что эту избыточность также можно уменьшить, если перейти к кодированию достаточно большими блоками.
Рассмотрим сообщения, образованные с помощью алфавита, состоящего всего из двух букв Z1 и Z2, с вероятностями появления соответственно p(Zi)=0,9 и р(Z2) =0,1.
Поскольку вероятности не равны, то последовательность из таких букв будет обладать избыточностью. Однако при побуквенном кодировании никакого эффекта не получается.
Действительно, на передачу каждой буквы требуется символ либо 1, либо 0, в то время как энтропия равна 0,47.
При кодировании блоков, содержащих по две буквы, получим коды, показанные в табл. 3.6.
Таблица 3.6
| Буквы | Вероятности | Ступени разбиения | кодовые комбинации | ||||||
| Z1 Z1 | 0,81 | ||||||||
| Z2 Z1 | 0,09 | ||||||||
| Z3 Z1 | 0,09 | ||||||||
| Z4 Z1 | 0,01 |
Так как буквы статистически не связаны, вероятности блоков определяются как произведение вероятностей составляющих букв.
Среднее число символов на блок получается равным 1,29; а на букву − 0,645.
Кодирование блоков, содержащих по три буквы, дает еще больший эффект. Соответствующий ансамбль и коды приведены в табл. 3.7.
Таблица 3.7.
| Буквы | Вероят ности | Ступени разбиения | кодовые комбинации | ||||||
| Z1 Z1 Z1 | 0,729 | ||||||||
| Z2 Z1 Z1 | 0,081 | ||||||||
| Z1 Z2 Z1 | 0,081 | ||||||||
| Z2 Z2 Z1 | 0,081 | ||||||||
| Z1 Z1 Z2 | 0,009 | ||||||||
| Z2 Z1 Z2 | 0,009 | ||||||||
| Z1 Z2 Z2 | 0,009 |
Среднее число символов на блок равно 1,59; а на букву − 0,53; что всего на 12% больше энтропии. Теоретический минимум Н(Z) = 0,47 может быть достигнут при кодировании блоков, включающих бесконечное число букв: 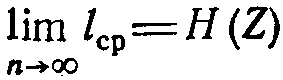 .
.
Следует подчеркнуть, что увеличение эффективности кодирования при укрупнении блоков, не связано с учетом все более далеких статистических связей, так как нами рассматривались алфавиты с некоррелированными буквами. Повышение эффективности определяется лишь тем, что набор вероятностей, получающийся при укрупнении блоков, можно делить на более близкие по суммарным вероятностям подгруппы.
Рассмотренная нами методика Шеннона—Фэно не всегда приводит к однозначному построению кода. Ведь при разбиении на подгруппы можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппу.
Множество вероятностей, приведенных в таблице 3.5, можно было бы разбить иначе, например, так, как это показано в табл. 3.8.
Таблица 3.8.
| Буквы | Вероятности | Ступени разбиения | кодовые комбинации | ||||||
| Z1 | 0,22 | ||||||||
| Z2 | 0,20 | ||||||||
| Z3 | 0,16 | ||||||||
| Z4 | 0,16 | ||||||||
| Z5 | 0,10 | ||||||||
| Z6 | 0,10 | ||||||||
| Z7 | 0,04 | ||||||||
| Z8 | 0,02 |
При этом среднее число символов на букву оказывается равным 2,80. Таким образом, построенный код может оказаться не самым лучшим. При построении эффективных кодов с основанием m>2 неопределенность становится еще большей.
От указанного недостатка свободна методика Хаффмена. Она гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву.
Дата добавления: 2021-04-21; просмотров: 579;
Поиск по сайту
Узнать еще
- ОСНОВНЫЕ ТИПЫ И СВОЙСТВА НАПОЛЬНЫХ И БОРТОВЫХ СИСТЕМ ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ
- CALS-технологии в автоматизированном производстве
- CASE-технология создания информационных систем
- Hа pазpезе показывают то, что расположено в секущей плоскости и что pасположено за ней.
- I. Специфические особенности процесса воспитания в сравнении с процессом обучения.
- II. Общее понятие о процессе познания и процессе обучения.
- II. Показатели обеспеченности запасов и затрат источниками их формирования.
- II. Формализация процесса формирования математических моделей

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
