Лемма 1. О существовании оптимального кода с одинаковой длиной кодовых слов двух наименее вероятных кодируемых букв
Формулировка. Для любого источника с k>=2 буквами существует оптимальный (в смысле минимума средней длины кодового слова) двоичный код, в котором два наименее вероятных слова xk и xk-1 имеют одну и ту же длину и отличаются лишь последним символом.
Пример: если существует кодовое слово xk = 0 1 1 0 0 0 1 0,
то существует и кодовое слово xk-1 = 0 1 1 0 0 0 1 1
Доказательство.
1. Докажем сначала, что для оптимального кода 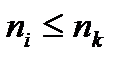 , где
, где  i < k , т.е. последнее кодовое слово, имеющее, кстати, наименьшую вероятность появления, имеет наибольшую длину.
i < k , т.е. последнее кодовое слово, имеющее, кстати, наименьшую вероятность появления, имеет наибольшую длину.
Для доказательства этого вспомним, что 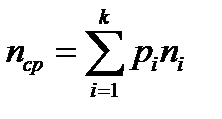 .
.
Найдем на сколько изменится nср, если nk=nmax и попытаемся поменять его с любым другим j-м словом длиной nj, т.е. aj кодировать xk и ak кодировать xj.
После такой перестановки получим:
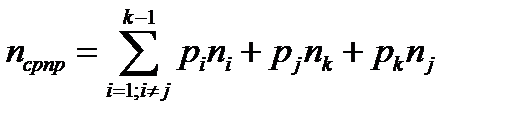 ,
,
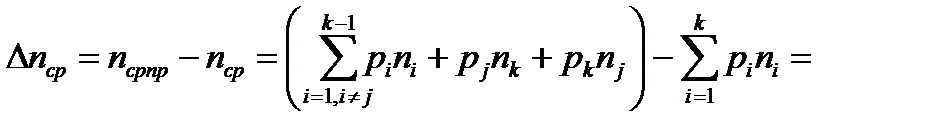
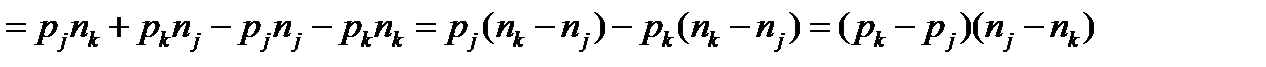 . (3.4)
. (3.4)
Если код оптимален, то любая перестановка кодовых слов должна приводить с росту средней длины кодового слова – к тому, что 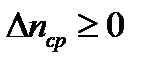 и к превращению кода из оптимального в неоптимальный.
и к превращению кода из оптимального в неоптимальный.
Докажем, что при принятых нами условиях действительно .
Поскольку, согласно постулированному[10] условию, буквы первичного алфавита упорядочены в порядке убывания вероятностей, разность 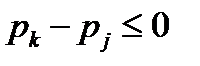 . С другой стороны,
. С другой стороны, 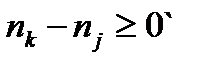 , тогда, когда
, тогда, когда 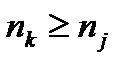 , что и требовалось доказать.
, что и требовалось доказать.
2. Заметим далее, что в любом оптимальном префиксном коде, для которого nk=nmax, должно быть другое кодовое слово, отличающееся от nk только буквой в последнем разряде. Например, если xk = 10110, то должно еще быть слово xi = 10111. Это следует из того, что в противном случае этот последний разряд можно было бы отсечь без нарушения свойства префикса и nср уменьшилось бы, что для оптимального кода невозможно. Следовательно, кодовое слово, отличающееся только последним разрядом, должно существовать.
3. Наконец, если xi отличается от xk только в одной позиции, то ni=nk и, как следует из (1), xi и xk-1 можно поменять меcтами без увеличения nср.
Таким образом, нами доказано, что кодовые слова xk и xk-1 оптимального префиксного кода имеют одинаковую и максимальную длину nk=nk-1 и отличаются лишь одной буквой вторичного алфавита.
С помощью этой леммы решение задачи построения оптимального кода сводится к решению задачи построения кодовых слов x1, x2, … , xk-2 и отысканию первых nk-1 символов кодового слова xk.
Следуя принятой терминологии, назовем совокупность {a} букв первичного алфавита, упорядоченных в порядке убывания вероятностей появления и вероятностей {p} их появления ансамблем U.
Определим теперь редуцированный[11] ансамбль U' как ансамбль, полученный из исходного нередуцированного ансамбля путем замены двух последних (с наименьшей вероятностью) букв исходного ансамбля одной новой буквой редуцированного ансамбля.
Таким образом, редуцированный ансамбль отличается от исходного нередуцированного меньшим на одну букву количеством букв первичного алфавита. Все буквы редуцированного ансамбля, кроме одной совпадают с буквами исходного ансамбля. Одна же буква редуцированного ансамбля заменяет две последние (с наименьшей вероятностью появления) буквы исходного ансамбля. Вероятность появления этой новой буквы редуцированного ансамбля при такой замене естественно равна сумме вероятностей появления двух букв исходного ансамбля, которые она заменяет.
Буквы алфавита редуцированного ансамбля так же, как буквы алфавита нередуцированного ансамбля, упорядочиваются в порядке убывания вероятностей их появления в сообщении. В результате такого упорядочения положение даже одних и тех же букв в исходном и редуцированном ансамбле может быть различным.
Любой префиксный код редуцированного ансамбля U', можно превратить в код исходного ансамбля простым добавлением концевого символа 0 к кодовому слову x'k-1 символа 1 к кодовому слову x'k. Это устанавливает взаимно однозначное соответствие между множеством префиксных кодов редуцированного ансамбля U' и множеством префиксных кодов исходного ансамбля U.
Дата добавления: 2021-04-21; просмотров: 670;
Поиск по сайту
Узнать еще
- DC-AC преобразователи. Двухактный инвертор.
- F52 Половая дисфункция, не обусловленная органическим расстройством или заболеванием
- I. Определение условий выполнения рукописи.
- I. Развитие Донбасса в условиях кризиса феодально-крепостнической системы
- I2C (Inter-Integrated Circuit) или двухпроводный интерфейс
- III этап. Составление программного кода
- III. Организационное обеспечение специальной оценки условий труда.
- III. Условия развития личности.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
