Учебная база данных
На протяжении всего курса в качестве примера будем рассматривать одну базу данных компьютерного магазина shop.
База данных компьютерного магазина состоит из четырех таблиц:
catalogs — список торговых групп;
products— товарные позиции;
users — список зарегистрированных пользователей магазина;
orders — список осуществленных сделок.
Таблица catalogs предназначена для хранения торговых групп, таких как "Материнские платы", "Процессоры", "Видеокарты" и т. п. Таблица состоит из двух полей:
- id_catalog — уникальный номер, тип поля INT(11);
- name — имя раздела, тип поля CHAR(20).
Таблица products содержит конкретные товарные позиции, такие как "Celeron 2.0GHz", "Intel Pentium 4 3.2GHz" и т. п. Таблица состоит из семи полей:
- id_product — уникальный номер товарной позиции; тип поля INT (11) NOT NULL
- name — название товарной позиции; тип поля CHAR (20)
- price — цена; тип поля DECIMAL (7,2)
- count — количество товарных позиций на складе; тип поля INT (11)
- mark — относительная оценка товара; тип поля FLOAT (4,1)
- description — описание; тип поля TEXT
- id_catalog — номер торговой группы из таблицы id_catalog, которой принадлежит товарная позиция тип поля INT(11) NOT NULL.
Поле id_catalog устанавливает связь между таблицами catalog и products. Зная уникальный номер каталога id_catalog, всегда можно узнать, какие товарные позиции принадлежат данной товарной группе и наоборот, к какой товарной группе принадлежит товарная позиция с конкретным значением id_catalog. MySQL позволяет сделать это при помощи несложных SQL-запросов, которые будут рассмотрены в следующих главах.
Таблица usersсодержит записи с информацией о зарегистрированных покупателях и состоит из восьми полей:
- iduser — уникальный номер покупателя; INT(11) NOT NULL
- surname — фамилия покупателя; CHAR (25)
- name — имя покупателя; CHAR (20)
- patronymic — отчество покупателя CHAR (30);
- phone — телефон покупателя (если имеется); CHAR (12)
- email — e-mail покупателя (если имеется); CHAR (20)
- url — домашняя страница покупателя (если имеется); CHAR (20)
- userstatus — статус покупателя, поле типа enum ('active','passive','lock','gold'), которое может принимать одно из четырех значений;
- active — авторизованный покупатель, который может осуществлять покупки через Интернет;
- passive— неавторизованный покупатель (значение по умолчанию), который осуществил процедуру регистрации, но не подтвердил ее и пока не может осуществлять покупки в магазине через Интернет, но ему доступны каталоги для просмотра;
- lock — заблокированный покупатель, не может осуществлять покупки и просматривать каталоги магазина;
- gold— активный покупатель с хорошей кредитной историей, которому предоставляется скидка при следующих покупках в магазине.
Поля phone, email и url снабжены атрибутом, т. к. посетитель имеет право не указывать эту информацию. Если эта информация не указана, то она носит неопределенный характер: телефона, e-mail и домашней страницы у покупателя может просто не быть, с другой стороны, он мог не захотеть их указывать. Поэтому, чтобы указать неопределенность этой информации, в поле следует поместить значение null. Все остальные поля получают атрибут not null, даже если он не указывается.
Таблица orders содержит информацию о покупках, совершенных в магазине, и включает пять полей:
- id_order — уникальный номер сделки; тип поля INT(11) NOT NULL
- id_user — номер пользователя из таблицы users; тип поля INT(11) NOT NULL
- ordertime — время совершения сделки; тип поля DATE
- number — число приобретенных товаров; тип поля INT(11)
- id_product — номер товарной позиции из таблицы products. тип поля INT (11)
В таблице orders устанавливается связь сразу с двумя таблицами: users, за счет поля users, и products, за счет поля id_product. Это позволит для каждой покупки восстановить покупателя и приобретенный товар. С другой стороны, можно узнать число покупок, совершенных каждым из покупателей, а также частоту покупки той или иной товарной позиции, что позволит увеличить или уменьшить закупки товара и тем самым произвести оптимизацию работы магазин.
Индексы
Индексы играют большую роль в базах данных, т. к. это основной способ ускорения их работы. Обычно записи в таблице располагаются в хаотическом порядке (рис. 5.1). Для того чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит большое количество времени. Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет очень быстро осуществлять поиск по такому столбцу, т. к. заранее известно, где необходимо искать значение.
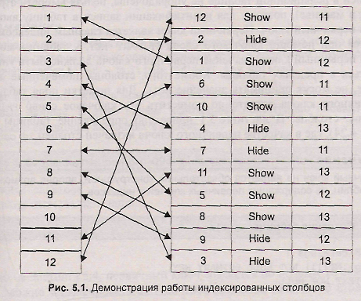
Обратной стороной медали является то, что добавление или удаление записи требует дополнительного времени на сортировку столбца, кроме того, создание копии увеличивает объем памяти, необходимый для размещения таблицы на жестком диске.
Существует несколько видов индексов.

Индексы могут иметь как свои собственные имена, так и имена индексируемых столбцов. Один индекс может охватывать один или несколько столбцов, причем тип столбца может быть любым, за исключением enum и set.
Первичный ключ
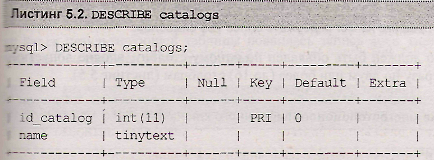
Так как записи в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру (как в массиве), поэтому для идентификации записи в таблицу вводится так называемый первичный ключ. Первичный ключ является главным индексом таблицы и объявляется при помощи ключевого слова primary key, у таблицы может быть только один первичный ключ. Значение первичного ключа должно быть уникально и не повторяться в пределах таблицы. Кроме того, столбцы, помеченные атрибутом-primary key, не могут принимать значение null. Для пометки поля таблицы в качестве первичного ключа достаточно поместить это ключевое слово primary key в определение столбца. В листинге 5.1 приведено определение таблицы catalogs (см. листинг 4.24), где в качестве первичного ключа назначен столбец id_catalog.

Просмотр структуры таблицы catalogs при помощи оператора describe показывает, что в четвертой колонке результирующей таблицы напротив поля id_catalog появился флаг pri, который отмечает поле первичного ключа (листинг 5.2)
Существует альтернативный способ объявления первичного ключа, представленный в листинге 5.3.

Как видно из листинга 5.3, объявление первичного ключа производится после объявления основных столбцов.
В качестве первичного ключа может выступать не только целочисленный столбец, но и текстовые данные. В этом случае необходимо обязательно добавить в круглых скобках число символов, входящих в индекс

Как видно из листинга 5.4, первичный ключ создается по первым 10 символам столбца name. Можно индексировать от 1 до 1000 символов текстового столбца. Следует помнить, что индексирование по одному символу приведет к тому, что уникальные символы быстро исчерпаются, и будет невозможно добавить новую запись в таблицу. Индексирование по большому числу символов приведет к резкому увеличению объема жесткого диска, необходимого для хранения таблицы.
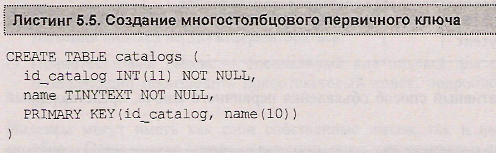
Индекс необязательно должен быть объявлен по одному столбцу, вполне допустимо объявление индекса сразу по двум или более (до 16) столбцам (листинг 5.5).
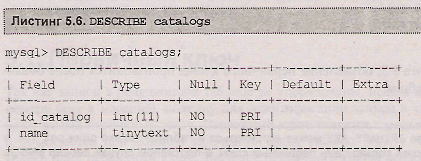
Просмотр структуры таблицы catalogs при помощи оператора describe показывает, что в четвертой колонке результирующей таблицы оба поля: и id_catalog, и name имеют флаг pri, который отмечает первичный ключ (листинг 5.6)
В качестве первичного ключа часто выступает столбец типа int или bigint. В таблицах учебной базы данных shop, созданных в главе 4, все поля, начинающиеся с префикса id_, предназначены для первичного ключа. Такой выбор связан с тем, что целочисленные типы данных обрабатываются быстрее всех и занимают небольшой объем данных. Другой причиной выбора целочисленного столбца является тот факт, что только данный тип столбца может быть снабжен атрибутом auto_increment, который обеспечивает автоматическое создание уникального индекса. Передача столбцу, снабженному этим атрибутом, значения null или 0 приводит к автоматическому присвоению ему максимального значения столбца плюс 1. Данный механизм является достаточно удобным и позволяет не заботиться о генерации уникального значения средствами прикладной программы, работающей с СУБД MySQL. В листинге 5.7 приводится пример использования ключевого слова autoincrement.

Просматривая структуру вновь созданной таблицы catalogs при помощи оператора describe (листинг 5.8), можно заметить, что для столбца id_catalog в шестой колонке Extra результирующей таблицы появилась запись auto_increment, сообщающая, что столбец снабжен этим атрибутом.

Как видно из листинга 5.8, для столбца id_catalog в качестве значения по умолчанию выставлено null, однако само поле не может принимать значение null. Передача null приведет к генерации уникального числа, которое и будет занесено в id_catalog. Если в таблице нет ни одного значения, то первое уникальное значение будет равным 1. Точно так же, как и в таблице может быть только один первичный ключ, столбцов, снабженных атрибутом auto_increment, также не должно быть больше одного.
К атрибуту auto__increment мы еще вернемся в главе 6 при рассмотрении оператора insert — вставки данных в таблицу.
Дата добавления: 2020-11-18; просмотров: 895;
Поиск по сайту
Узнать еще
- STEP – стандарт для описания данных об изделии
- Автоматизация технологических процессов на эмульсионных базах и контроль качества эмульсий
- АВТОМАТИЗИРОВАННАЯ ОБРАБОТКА ДАННЫХ В СЛУЖБЕ ПРИЕМА И РАЗМЕЩЕНИЯ
- Автоматизированная система технической паспортизации (АСПАД) и создание автоматизированного банка дорожных данных (АБДЦ).
- Автоматизированная система технической паспортизации дорог и создание банка дорожных данных
- АВТОМАТИЗИРОВАННЫЕ БАНКИ ДАННЫХ, ИНФОРМАЦИОННЫЕ БАЗЫ, ИХ ОСОБЕННОСТИ
- Автоматизированные банки дорожных данных.
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 1 глава

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
