Обычный и уникальный индексы
В отличие от первичного ключа, таблица может содержать несколько обычных и уникальных индексов, для того чтобы их различать, индексы могут иметь собственные имена. Часто имена индексов совпадают с именами столбцов, которые они индексируют, но для индекса можно назначить и совершенно другое имя. Объявление индекса производится при помощи ключевого слова index или key. Для уникальных индексов, которые не позволяют добавлять в таблицу записи с уже существующими значениями, вводится дополнительное ключевое слово unique, т. е. пишется unique
UNIQUE И UNIQUE KEY.
В листинге 5.9. приводится оператор CREATE TABLE, создающий таблицу orders (см. листинг 4.27) из учебной базы данных shop.
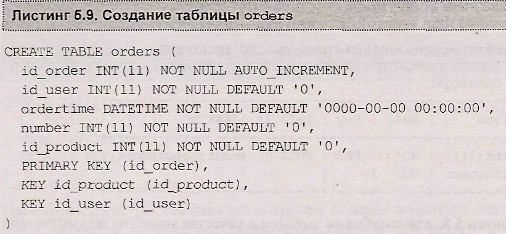
Как видно из листинга 5.9, в таблице orders вводятся два индекса по столбцам id_product и id_user.
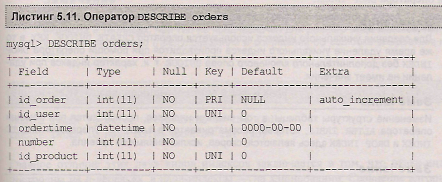
Просмотр структуры таблицы orders при помощи оператора describe приводит к результату, представленному в листинге 5.10.

Как видно из листинга 5.10, столбцы, проиндексированные обычным индексом, помечаются в поле Key флагом nul
Объявление уникальных индексов в таблице orders приводит к тому, что проиндексированные столбцы помечаются флагом nul. (листинг 5.11).
Точно так же, как и первичный ключ, обычные индексы можно объявить на нескольких столбцах (до 16), как это продемонстрировано в листинге 5.12.

Интересно отметить, что оператор DESCRIBE в этом случае будет считать проиндексированным только поле id_product (листинг 5.13).


Часто решение об индексировании столбцов принимается после того, как таблица создана и заполнена данными. В этом случае прибегают к изменению структуры таблицы, создавая индекс при помощи оператора create index или удаляя его при помощи оператора drop index.
В листинге 5.14 демонстрируется создание индекса с именем id_catalog_index для столбца id_catalog таблицы products (см. листинг 4.25) учебной базы данных shop.

Если необходимо создать индекс по нескольким столбцам, они перечисляются в круглых скобках через запятую.
Оператор drop index, который удаляет вновь созданный индекс, представлен в листинге 5.15

Точно так же, как и в случае первичного ключа, допускается индексирование текстовых столбцов, если указано число индексируемых символов (листинг 5.16).

Допускается создание индекса на текстовых столбцах с использованием от 1 до 1000 первых символов.
Начиная с версии 4.1, в операторе create index можно при помощи ключевого слова using указать тип индекса. В настоящее время допустимо создание индексов типа btree и hash. Тип btree можно создавать в таблицах MylSAM, InnoDB и MEMORY, тип hash доступен только в таблицах типа MEMORY.

Главное отличие этих двух видов индексов заключается в том, что BTREE-индексы построены на b-деревьях, а HASH-индексы — на хэшировании. Сравнение алгоритмов работы этих индексов выходит за рамки данной книги.
Дата добавления: 2020-11-18; просмотров: 850;
Поиск по сайту
Узнать еще
- А – обычный, нагреваемый пламенем; б – электрический; в – паяльная лампа
- Анизотропия кристаллов. Индексы Миллера
- Детали ГД – дизелей, имеющие наибольшие индексы риска
- Для оценки интенсивности кариеса постоянных зубов используют индексы
- Измерение в социологическом исследовании. Шкалы и индексы.
- Индексы в социологии.
- Индексы переменного и фиксированного состава. Индекс структурных сдвигов
- Индексы российских бирж

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
