Параллельные алгоритмы решения задач линейной алгебры
Пример №2.2. Пусть требуется вычислить скалярное произведение векторов а и b:
X22 = а т b = S аi bi (i = 1…n; n = 4), (2.5)
где т – символ транспонирования вектора.
ПФ последовательного алгоритма решения этой задачи на однопроцессорном компьютере (p = 1) можно представить в виде табл. 2.2, где ярусы расположены горизонтально:

Табл. 2.2. Вычисление величины X22 на однопроцессорном компьютере (Пример №2.2)
Высота ПФ (табл.2.2)H1= 7, ширина B1= 1.
ПФ алгоритма решения этой же задачи на 4-процессорной ПВМ (p = 4) можно представить в виде табл. 2.3:
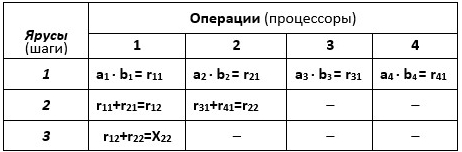
Табл. 2.3. Вычисление величины X22 на 4-процессорной ПВМ (Пример №2.2)
Высота ПФ (табл.2.3)H4= 3, ширина – B4= 4.
В соответствии с п.2.2. определим основные характеристики алгоритма, ПФ которого представлена в табл.2.3.
а) Ускорение S4 = H1 / H4 = 7 / 3 =2.33.
б) ЭффективностьE4 = S4 / 4 = 2.33 / 4 = 0.58.
в) Высота H4 = 3.
г) Загруженность процессоров : Z4 = (7 / 12) 100% = 58.3%.
д) Устойчивость алгоритма. Сравнивая схемы вычислений табл.2.2 и табл.2.3, можно видеть, что они реализуют разные алгоритмы. При точных вычислениях они дадут одинаковые результаты, но в условиях влияния ошибок округлений результаты будут разными. Другими словами, эти алгоритмы обладают разной степенью устойчивости к ошибкам округления. Следует отметить, что устойчивость параллельных алгоритмов при большом числепроцессоров хуже устойчивости последовательных алгоритмов, реализуемых на однопроцессорных компьютерах.
Теперь построим ПФ алгоритма решения той же задачи на 2-процессорной ПВМ (табл.2.4).
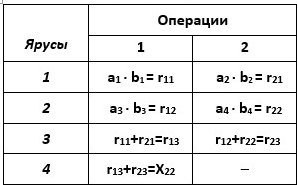
Табл. 2.4. Вычисление величины X22 на 2-процессорной ПВМ (Пример №2.2)
Определим характеристики алгоритма, ПФ которого представлена в табл.2.4:
а) ускорение S2 = H1 / H2 = 7 / 4 = 1,75;
б) эффективностьE2 = 1,75 / 2 = 0,875;
в) высота H2 = 4;
г) загруженность процессоров : Z2 = (7 / 8) 100% = 87,5%;
д) устойчивость алгоритмов табл.2.3 и табл.2.4 будут примерно одинаковыми, поскольку число промежуточных результатов (округлений) одно и то же.
Сравнивая алгоритмы вычислений табл.2.3 и табл.2.4, можно отметить, что для решения поставленной задачи следует использовать 2-процессорную ПВМ, поскольку она имеет лучшие характеристики (эффективность и загруженность) по сравнению с 4 - процессорной ПВМ. Однако улучшение указанных характеристик достигается здесь за счет увеличения числа шагов алгоритма (H2=4), т.е. за счет увеличения времени работы ПВМ.
Пример №2.3. Требуется выполнить умножение квадратной матрицы А на вектор х:
y = A × x , т.е. yi = S aij xj , ( i = 1…n , j = 1…n )(2.6)
на ПВМ, имеющей n2процессоров.
Эта задача распадается (распараллеливается) на n независимых ветвей вычисления n скалярных произведений векторов аiи x(см. Пример 2.2). Параллельный алгоритм решения данной задачи включает следующие этапы:
а) на первом шаге вычисляются все n2 произведений вида a× x.
б) с использованием схемы сдваивания (см. табл.2.1 и табл.2.3) для операций сложения за H=log2 n шагов вычисляются все n сумм, определяющих координаты вектора y. Процессоры используются неравномерно: на первом шаге используются все, а потом их загруженность уменьшается вдвое.
Пример №2.4. Вычислить произведение двух квадратных матриц порядка n на ПВМ, имеющей n3процессоров.
Параллельный алгоритм решения задачи сводится к n операциям умножения матрицы на вектор (см. Пример 2.3). ПВМ должна обеспечить одновременный доступ многих процессоров к одной и той же информации.Высота ПФ алгоритма h = log2n+1, ширина ПФ равна n3.
Пример №2.5. Многие численные методы линейной алгебры, математической физики и анализа построены на основе использования рекуррентных соотношений:
xi = S Aij×xi-j + bi , ( i = 1…s; j = 1…r; A[n, n]; x[n]; b[n] ), (2.7)
где xi – s искомых векторов размерности n; Aij – s×r квадратных матриц; bi – s векторов.
Используя n2r процессоров, правую часть соотношения (2.7) (для каждого i) можно вычислить за s× log2n шагов. Соотношение (2.7) можно преобразовать к виду:
yi = П Qk × y0 , ( i = 1…s; k = 1…i ), (2.8)
где каждый вектор yразмерности nr+1содержит соответствующие векторы xиb, а в состав каждой квадратной матрицы Qразмерности nr+1входят матрицы Aиз (2.5).
Согласно алгоритму сдваивания все произведения в соотношении (2.8) можно вычислить за число макрошагов, равное log2 (s +1). При этом будет использовано s +1 макропроцессоров, выполняющих в качестве макрооперации умножение двух квадратных матриц порядка nr+1.Далее строится параллельный алгоритм вычисления векторов xi с высотой log2 s× log2nr и шириной порядка (nr)2× s.Описанный алгоритм получил название алгоритма рекуррентного сдваивания.
Дата добавления: 2023-09-28; просмотров: 1179;
Поиск по сайту
Узнать еще
- Алгоритмы параллельных вычислений. Параллельные формы алгоритмов
- Задачи и способы очистки лесосек
- Задачи-измерители. Описание и примеры
- Майнинг биткоинов. Задача майнеров биткоина
- Модели и алгоритмы планирования вычислений
- Определение, задачи и назначение латинской палеографии и кодикологии для изучения истории
- Основы цифровой техники. Основные законы алгебры логики

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
