Показателей внутри одной выборки
Критерий хи-квадрат может быть применен и для выявления сходства или различия внутри одной, но численно достаточно большой выборки. В этом случае вычленяются показатели (а их может быть два и больше), по которым и осуществляется сравнение. Этот аспект применения критерия хи-квадрат сближает его с коэффициентом корреляции, который также находит степень связи между двумя или большим числом признаков. Различие между этими двумя методами, прежде всего, в том, что для подсчета коэффициента корреляции необходимо знать все величины сравниваемых признаков, а для использования критерия хи-квадрат важно знать только уровни (градации) сравниваемых признаков.
При сравнении показателей с помощью критерия хи-квадрат нулевая гипотеза Н0 звучит так: сравниваемые признаки не влияют друг на друга. В терминах корреляционных отношений: между признаками связи нет, корреляция не отличается от нуля.
Соответственно альтернативная гипотеза Н1 звучит следующим образом: сравниваемые признаки влияют друг на друга. В терминах корреляционных отношений: между признаками связь есть, корреляция значимо отличается от нуля.
В этих случаях применение критерия хи-квадрат основывается на использовании так называемых многопольных таблиц или, как их еще называют, таблиц сопряженности, т. е. таких таблиц, эмпирические данные в которых представлены размерностью большей, чем 2×2.
В этом случае расчет эмпирического значения критерия хи-квадрат может осуществляться по следующим двум формулам:
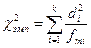 , (13.10)
, (13.10)
где di – разность между эмпирическими и «теоретическими» частотами;
fmi – есть вычисленная, или «теоретическая» частота.
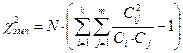 , (13.11)
, (13.11)
где k – число строк многопольной таблицы;
m – число столбцов многопольной таблицы;
N – общее число значений (элементов) в многопольной таблице, оно всегда является произведением N = k ∙ m;
Сij – элементы многопольной таблицы;
Сi – суммарные значения по строкам многопольной таблицы;
Сj – суммарные значения по столбцам многопольной таблицы.
Проиллюстрируем все вышесказанное решением примера, взятого с некоторыми модификациями из учебного пособия Психологическая диагностика / под ред. К. М. Гуревича и М. К. Акимовой. – М. : Изд-во УРАО, 1997.
Пример 13.11. Влияет ли уровень интеллекта на профессиональные достижения?
Решение. (Первый способ решения по формуле 13.10.) Для решения этой задачи 90 человек оценили по степени их профессиональных достижений и по уровню интеллекта. При разбиении на уровни (градации признака) по обоим признакам было взято три уровня. Для показателя профессиональных достижений были получены следующие частоты признака: 20 человек с высоким уровнем профессиональных достижений, 40 со средним и 30 с низким. Первая группа составляет 22,2% выборки, вторая – 44,4% и третья – 33,3% от всей выборки. При разбиении по уровню интеллекта было взято три равных по численности группы, в каждой по 30 человек: уровень интеллекта ниже среднего, средний и выше среднего. В процентах каждая группа составляет 33,3% от всей выборки. Все эмпирические данные (частоты) представлены ниже в таблице 13.14.
Сформулируем гипотезы
Н0: уровень интеллекта не влияет на успешность профессиональной деятельности.
Н1: Уровень интеллекта влияет на успешность профессиональной деятельности.
Таблица 13.14
| IQ | Оценка профессиональных достижений | Всего | ||
| Ниже среднего | Средняя | Выше среднего | ||
| Ниже среднего | 20 А (10) | 5 в (13,3) | 5 С (6,7) | |
| Средний | 5 D (10) | 15 Е (13,3) | 10 F (6,7) | |
| Выше среднего | 5 G (10) | 20 Н (13,3) | 5 J (6,7) | |
| Итого |
Для удобства каждая ячейка таблицы обозначена соответствующей латинской буквой: А, В, С и т.д. Таблица 13.14 устроена следующим образом: в ячейку, обозначенную символом А, заносятся эмпирические частоты (или число) тех испытуемых, которые одновременно обладают следующей характеристикой: ниже среднего по уровню профессиональных достижений и ниже среднего по интеллекту. Таких испытуемых (эмпирических частот) оказалось 20. В ячейку, обозначаемую символом B, заносятся эмпирические частоты (или число) тех испытуемых, которые одновременно обладают характеристикой: средние по уровню профессиональных достижений и ниже среднего по интеллекту. Таких испытуемых (эмпирических частот) оказалось 5. В ячейку, обозначенную символом С, заносятся эмпирические частоты (или число) тех испытуемых, которые одновременно обладают характеристикой: выше среднего по уровню профессиональных достижений и ниже среднего по интеллекту. Таких испытуемых (эмпирических частот) оказалось также 5. Заметим, что 20 + 5 + 5 = 30, т. е. числу испытуемых, имеющих уровень интеллекта ниже среднего. Подобные «разбиения» были проделаны для каждой ячейки таблицы 13.14. Подчеркнем, что в круглых скобках в каждой ячейке таблицы представлены вычисленные для этой ячейки «теоретические» частоты.
Покажем, как для каждой ячейки таблицы 13.14 найти соответствующую «теоретическую» частоту. Это делается следующим образом. Для каждого столбца таблицы подсчитываются так называемые «частости» в процентах:
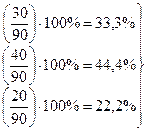 – частости.
– частости.
Полученные величины «частостей» дают возможность подсчитать «теоретические» частоты для каждой ячейки таблицы 13.14. Они служат основой для подсчета «гипотетических» (а по сути теоретических) частот, т. е. таких частот, которые при заданном соотношении экспериментальных данных должны были бы быть расположены в соответствующих ячейках таблицы 13.14. (Вспомним решение примера 13.5.)
Согласно этому положению «теоретическая» частота для ячейки А подсчитывается следующим образом. 30 человек имеют уровень интеллекта ниже среднего, поэтому 33,3% от этого числа должны были бы попасть в группу с профессиональными достижениями ниже среднего уровня. Находим эту «гипотетическую» величину так: 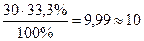 .
.
Аналогично «теоретическая» частота для ячейки D считается следующим образом: 30 человек имеют средний уровень интеллекта, поэтому 33,3% от этого числа должны были бы попасть в группу с профессиональными достижениями среднего уровня. Находим эту «гипотетическую» величину так: .
Аналогично «теоретическая» частота для ячейки G считается следующим образом: 30 человек имеют высокий уровень интеллекта, поэтому 33,3% от этого числа должны были бы попасть в группу с профессиональными достижениями выше среднего уровня. Находим эту «гипотетическую» величину так: .
Рассмотрим, как производится подсчет для ячейки В. 30 человек имеют низкий уровень интеллекта, поэтому 44,4% от этого числа должны были бы попасть в группу с профессиональными достижениями среднего уровня. Находим эту «гипотетическую» величину так:  .
.
Аналогично производится подсчет для ячейки Е. 30 человек имеют средний уровень интеллекта, поэтому 44,4% от этого числа должны были бы попасть в группу с профессиональными достижениями среднего уровня. Находим эту «гипотетическую» величину так: .
Аналогично производится подсчет для ячейки Н. 30 человек имеют уровень интеллекта выше среднего, поэтому 44,4% от этого числа должны были бы попасть в группу с профессиональными достижениями среднего уровня. Находим эту «гипотетическую» величину так: .
Рассмотрим, наконец, как производится подсчет для ячейки С. 30 человек имеют низкий уровень интеллекта, поэтому 22,2% от этого числа должны были бы попасть в группу с профессиональными достижениями выше среднего уровня. Находим эту «гипотетическую» величину так: 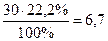 .
.
Расчет «теоретических гипотетических» частот для оставшихся ячеек проведите самостоятельно.
Проверим правильность расчета «теоретических» частот для всех столбцов таблицы 8.14: 10 + 10 + 10 = 30; 13,3 + 13,3 + 13,3 = 39,9 = 40; 6,7 + 6,7 + 6,7 = 20,1 ≈ 20.
Теперь все готово для использования формулы (13.1).
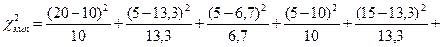
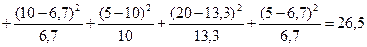 .
.
Для проверки правильности расчета «теоретических» частот в случае сравнения двух эмпирических наблюдений (см. раздел 8.2) или для сравнения показателей внутри одной выборки может использоваться следующая формула (13.12):
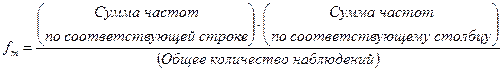 (13.12)
(13.12)
Проверим по этой формуле правильность наших расчетов:
fm для ячейки А – 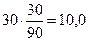 ;
;
fm для ячейки В – ; 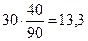
fm для ячейки С – 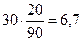 ;
;
fm для ячейки D – ;
fm для ячейки Е – ; ;
fm для ячейки F – ;
fm для ячейки G – ; ;
fm для ячейки Н – ; ;
fm для ячейки J – .
Число степеней свободы подсчитаем по знакомой формуле ν = (k – 1)∙(с – 1) = (3 – 1)∙(3 – 1) = 4, где k – число строк, а с – число столбцов, и в соответствии с таблицей 16 приложения 1 находим:
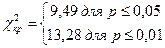
Строим «ось значимости».

|
Полученная эмпирическая величина критерия хи-квадрат попала в зону значимости. Иными словами, следует принять гипотезу Н1 о том, что уровень интеллекта влияет на успешность профессиональной деятельности.
Решение. (Второй способ решения по формуле 13.11.)
Подставим данные таблицы 13.14 в формулу (13.11), получим:
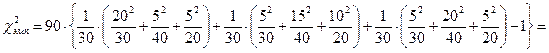
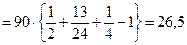 .
. 
Как и следовало ожидать, эмпирическое значение хи-квадрат получено то же самое, что и при первом способе решения. Все дальнейшие операции уже проделаны выше при первом способе решения данной задачи, поэтому не будем их повторять. Безусловно, что второй способ существенно проще первого, однако, при расчетах по формуле (13.11) можно легко допустить ошибки. Подчеркнем, что как первый, так и второй способы расчета эмпирического значения хи-квадрат позволяют работать с таблицами практически любой размерности: 3×4, 4×4, 5×3, 5×6 и т. п.
13.3. λ – критерий Колмогорова-Смирнова
Критерий λ предназначен для сопоставления двух распределений:
а) эмпирического с теоретическим, например, равномерным или нормальным;
б) одного эмпирического распределения с другими эмпирическим распределением.
Критерий позволяет найти точку, в которой сумма накопленных расхождений между двумя распределениями является наибольшей, и оценить достоверность этого расхождения.
Если в методе χ2 мы сопоставляли частоты двух распределений отдельно по каждому разряду, то здесь мы сопоставляем сначала частоты по первому разряду, потом по сумме первого и второго разрядов, потом по сумме первого, второго и третьего разрядов и т. д. Таким образом, мы сопоставляем всякий раз накопленные к данному разряду частоты.
Если различия между двумя распределениями существенны, то в какой-то момент разность накопленных частот достигнет критического значения, и мы сможем признать различия статистически достоверными. В формулу критерия λ включается эта разность. Чем больше эмпирическое значение λ, тем более существенны различия.
Гипотезы
Н0: Различия между двумя распределениями недостоверны (судя по точке максимального накопленного расхождения между ними).
Н1: Различия между двумя распределениями достоверны (судя по точке максимального накопленного расхождения между ними).
Ограничения критерия λ
1. Критерий требует, чтобы выборка была достаточно большой. При сопоставлении двух эмпирических распределений необходимо, чтобы n1,2 ≥ 50. Сопоставление эмпирического распределения с теоретическим иногда допускается при n ≥ 5.
2. Разряды должны быть упорядочены по нарастанию или убыванию какого-либо признака. Они обязательно должны отражать какое-то однонаправленное его изменение. Например, мы можем за разряды принять дни недели, 1-й, 2-й, 3-й месяцы после прохождения курса терапии, повышение температуры тела, усиление чувства недостаточности и т. д. В то же время, если мы возьмем разряды, которые случайно оказались выстроенными в данную последовательность, то и накопление частот будет отражать лишь этот элемент случайного соседства разрядов. Например, если шесть стимульных картин в методике Хекхаузена разным испытуемым предъявляются в разном порядке, мы не вправе говорить о накоплении реакции при переходе от картины № 1 стандартного набора к картине № 2 и т. д. Мы не можем говорить об однонаправленном изменении признака при сопоставлении категории «очередность рождения», «национальность», «специфика полученного образования» и т.п. Эти данные представляют собой номинативные шкалы: в них нет никакого однозначного однонаправленного изменения признака.
Итак, мы не можем накапливать частоты по разрядам, которые отличаются лишь качественно и не представляют собой шкалы порядка.
Во всех тех случаях, когда разряды представляют собой не упорядоченные по возрастанию или убыванию какого-либо признака категории, нам следует применять метод χ2 .
Дата добавления: 2021-11-16; просмотров: 504;
Поиск по сайту
Узнать еще
- III. Характеристики основных классов загрязняющих веществ в водной среде.
- VII.I. Закономерности изменения свойств нефтей и газов внутри залежей.
- А. Первичная обработка исходной статистики
- Абиотические факторы водной среды.
- АВАРИЙНОЕ УПРАВЛЕНИЕ ПС ОДНОЙ СЕКЦИИ.
- Августовский путч и распад СССР. Окончание «холодной войны». Распад советского блока.
- Алгоритм привязки RADIUS-сервера к беспроводной сети коммерческого предприятия, настройка сервера и коммутатора при проектировании системы обработки информации
- Альтернативные теории международной торговли

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
