ИСПОЛЬЗОВАНИЕ ДОСТАТОЧНЫХ СТАТИСТИК
Фактически нахождение правила решения 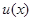 , удовлетворяющего одному или сразу нескольким рассмотренным выше принципам предпочтения, представляет собой далеко не простую задачу. Это связано с тем, что даже задача отыскания байесова правила решения при отсутствии априорной неопределенности, несмотря на существование общих рецептов, подчас оказывается слишком сложной из-за трудностей вычисления апостериорного риска в явной и вполне детализированной форме. В этом отношении большую пользу при решении конкретных задач приносит использование достаточных статистик (минимальных или хотя бы достаточно малой размерности), о которых шла речь в гл. 2. Дело в том, что для практических задач синтеза информационных систем характерно наличие большой размерности - в первую очередь, данныхх, описывающих результаты наблюдения, - что существенно затрудняет получение окончательных замкнутых результатов. Использование достаточных статистик резко понижает размерность задачи, что приносит существенное упрощение и при чисто байесовом подходе, а в задачах с априорной неопределенностью часто позволяет получить конкретные алгоритмы принятия решений, основанные только на достаточных статистиках и являющиеся если не абсолютно оптимальными, то, по крайней мере, обладающие многими чертами оптимальности. Естественно также, что при относительно малой размерности легче выявить условия существования строго или приближенно равномерно наилучшего правила решения. Даже если эти условия не выполняются или не находятся, то нахождение достаточных статистик способствует отысканию и пониманию структуры оптимального правила решения - функционального соответствия между данными наблюдения х и решением
, удовлетворяющего одному или сразу нескольким рассмотренным выше принципам предпочтения, представляет собой далеко не простую задачу. Это связано с тем, что даже задача отыскания байесова правила решения при отсутствии априорной неопределенности, несмотря на существование общих рецептов, подчас оказывается слишком сложной из-за трудностей вычисления апостериорного риска в явной и вполне детализированной форме. В этом отношении большую пользу при решении конкретных задач приносит использование достаточных статистик (минимальных или хотя бы достаточно малой размерности), о которых шла речь в гл. 2. Дело в том, что для практических задач синтеза информационных систем характерно наличие большой размерности - в первую очередь, данныхх, описывающих результаты наблюдения, - что существенно затрудняет получение окончательных замкнутых результатов. Использование достаточных статистик резко понижает размерность задачи, что приносит существенное упрощение и при чисто байесовом подходе, а в задачах с априорной неопределенностью часто позволяет получить конкретные алгоритмы принятия решений, основанные только на достаточных статистиках и являющиеся если не абсолютно оптимальными, то, по крайней мере, обладающие многими чертами оптимальности. Естественно также, что при относительно малой размерности легче выявить условия существования строго или приближенно равномерно наилучшего правила решения. Даже если эти условия не выполняются или не находятся, то нахождение достаточных статистик способствует отысканию и пониманию структуры оптимального правила решения - функционального соответствия между данными наблюдения х и решением 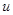 .Последнее обстоятельство позволяет целенаправленно и с пониманием существа дела ввести аппроксимацию зависимости
.Последнее обстоятельство позволяет целенаправленно и с пониманием существа дела ввести аппроксимацию зависимости 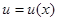 , исключить возможные неизвестные параметры, делающие эту зависимость не вполне определенной, и т. п. Таким образом, можно утверждать, что выявление достаточных статистик малой размерности является если не обязательным, то весьма целесообразным элементом решения задачи синтеза в условиях априорной неопределенности.
, исключить возможные неизвестные параметры, делающие эту зависимость не вполне определенной, и т. п. Таким образом, можно утверждать, что выявление достаточных статистик малой размерности является если не обязательным, то весьма целесообразным элементом решения задачи синтеза в условиях априорной неопределенности.
Общее определение достаточных статистик и правила их нахождения рассмотрены в § 2.6. Из этих результатов следует, в частности, что совокупность величин 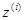 (4.2.7) является достаточной статистикой для решения задачи различения сигналов {
(4.2.7) является достаточной статистикой для решения задачи различения сигналов { 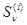 }, наблюдаемых в смеси с гауссовой помехой произвольной (в том числе неизвестной) интенсивности. Если дополнить их еще одной величиной
}, наблюдаемых в смеси с гауссовой помехой произвольной (в том числе неизвестной) интенсивности. Если дополнить их еще одной величиной 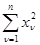 , то полученная совокупность будет достаточной статистикой для решения той же задачи уже с произвольными вероятностями появления сигналов
, то полученная совокупность будет достаточной статистикой для решения той же задачи уже с произвольными вероятностями появления сигналов 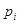 и произвольной матрицей потерь
и произвольной матрицей потерь 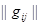 , не равными 1/m и
, не равными 1/m и 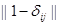 соответственно, как в § 4.2.
соответственно, как в § 4.2.
Для задач синтеза в условиях априорной неопределенности особое значение имеют инвариантные достаточные статистики, то есть такие преобразования 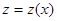 , распределения вероятности которых одинаковы при любом распределении вероятности х из класса Pl . Если инвариантная достаточная статистика существует, то можно ввести такое преобразование
, распределения вероятности которых одинаковы при любом распределении вероятности х из класса Pl . Если инвариантная достаточная статистика существует, то можно ввести такое преобразование 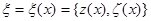 , что функция правдоподобия, записанная в новых переменных
, что функция правдоподобия, записанная в новых переменных 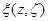 , для всех элементов
, для всех элементов 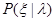 класса Pl , соответствующего имеющейся априорной неопределенности, может быть представлена в виде
класса Pl , соответствующего имеющейся априорной неопределенности, может быть представлена в виде
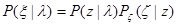 , (4.5.1)
, (4.5.1)
где 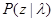 - одинакова для всех
- одинакова для всех 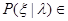 Pl . Отсюда немедленно следует, что апостериорное распределение
Pl . Отсюда немедленно следует, что апостериорное распределение 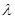 одинаково для всех элементов Pl и, следовательно, априорная неопределенность является несущественной. Таким образом, отыскание инвариантной достаточной статистики фактически эквивалентно устранению первоначально имевшейся априорном неопределенности.
одинаково для всех элементов Pl и, следовательно, априорная неопределенность является несущественной. Таким образом, отыскание инвариантной достаточной статистики фактически эквивалентно устранению первоначально имевшейся априорном неопределенности.
К сожалению, общие методы отыскания инвариантных или приближенно инвариантных достаточных статистик не разработаны, а существование строго инвариантных достаточных статистик - довольно редкое явление. Тем не менее, это понятие полезно, поскольку его использование приводит к довольно быстрому решению достаточно сложных задач, среди которых выделяются двухальтернативные задачи с так называемой свободной альтернативой. Этот термин соответствует тому случаю, когда одна из альтернативных ситуаций как-то задана (полностью или частично), а о второй вообще ничего не известно и она может быть совершенно произвольной (естественно, не совпадающей с заданной). Фактически подобные задачи отражают широкий круг практических потребностей, связанных с нахождением правил проверки какого-либо однозначно или многозначно заданного гипотетического предположения, когда альтернативой этому предложению может быть все, что угодно.
Рассмотрим для примера задачу, когда по результатам наблюдения 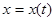 в дискретных точках
в дискретных точках 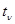 (
( 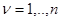 ) требуется решить, содержит ли
) требуется решить, содержит ли 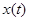 сигнал из заданного класса
сигнал из заданного класса 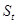 или нет. Пусть заданный класс удовлетворяет следующему описанию
или нет. Пусть заданный класс удовлетворяет следующему описанию
: 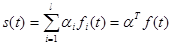 , (4.5.2)
, (4.5.2)
где 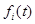 - известные функции времени;
- известные функции времени; 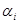 - произвольные неизвестные коэффициенты: 1
- произвольные неизвестные коэффициенты: 1 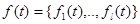 ,
, 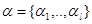 - соответствующие векторы (столбцы) неизвестных коэффициентов и известных функций, т - знак транспортирования (
- соответствующие векторы (столбцы) неизвестных коэффициентов и известных функций, т - знак транспортирования ( 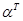 - вектор-строка). Данные наблюдения х представляют собой последовательность
- вектор-строка). Данные наблюдения х представляют собой последовательность
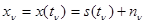 , , (4.5.3)
, , (4.5.3)
где 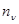 - гауссова некоррелированная помеха с дисперсией
- гауссова некоррелированная помеха с дисперсией 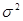 и нулевым математическим ожиданием. Альтернативой (4.5.2) может быть совершенно произвольный сигнал.
и нулевым математическим ожиданием. Альтернативой (4.5.2) может быть совершенно произвольный сигнал.
Функция правдоподобия при условии, что 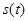 принадлежит классу (4.5.2) (будем считать, что этой ситуации соответствует (
принадлежит классу (4.5.2) (будем считать, что этой ситуации соответствует ( 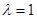 ), имеет значение
), имеет значение
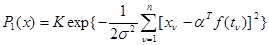 (4.5.4)
(4.5.4)
(К .- несущественный нормировочный множитель) и зависит от совокупности l неизвестных параметров . Значение функции правдоподобия для альтернативной ситуации ( 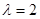 ) равно
) равно
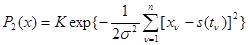 , (4.5.5)
, (4.5.5)
где - совершенно произвольный сигнал, и фактически вообще неизвестно из-за неопределенности этого сигнала. Таким образом, мы имеем двухальтернативную задачу с весьма большой априорной неопределенностью.
Из-за крайней неопределенности во второй ситуации очевидно, что никакой нетривиальной достаточной статистики, кроме последовательности { 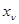 }, для этой ситуации не существует. Для первой же ситуации существует весьма экономная (одномерная) достаточная статистика, распределение вероятности которой не зависит от неизвестных параметров
}, для этой ситуации не существует. Для первой же ситуации существует весьма экономная (одномерная) достаточная статистика, распределение вероятности которой не зависит от неизвестных параметров 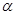 , создающих априорную неопределенность в этой ситуации. Действительно, (4.5.4) можно преобразовать к виду
, создающих априорную неопределенность в этой ситуации. Действительно, (4.5.4) можно преобразовать к виду
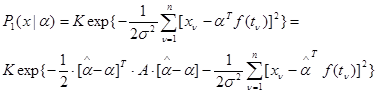 , (4.5.6)
, (4.5.6)
где
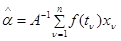 (4.5.7)
(4.5.7)
- оптимальная линейная оценка вектора ;
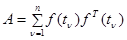 (4.5.8)
(4.5.8)
- положительно определенная матрица порядка { 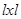 }. Нетрудно убедиться, что распределение вероятности одномерной статистики
}. Нетрудно убедиться, что распределение вероятности одномерной статистики
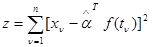 (4.5.9)
(4.5.9)
не зависит от значений неизвестных параметров , поэтому величина 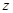 из (4.5.9) обладает свойством инвариантности, и всякое правило решения, использующее только эту величину, будет иметь вероятность ошибочно отвергнуть исходную гипотезу о принадлежности сигнала классу (4.5.2), одинаковую при любых значениях , то есть для всех представителей этого класса.
из (4.5.9) обладает свойством инвариантности, и всякое правило решения, использующее только эту величину, будет иметь вероятность ошибочно отвергнуть исходную гипотезу о принадлежности сигнала классу (4.5.2), одинаковую при любых значениях , то есть для всех представителей этого класса.
Остальные 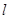 статистик
статистик 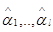 , через которые совместно с выражается функция правдоподобия (4.5.6), несут информацию только о значениях неизвестных параметров , уточняя тем самым вид сигнала в пределах класса (4.5.2). Исходя из этого, а также из полной неопределенности для альтернативной ситуации, кажется достаточно правдоподобным, что оптимальное правило решения о соответствии сигнала , наблюдаемого в смеси с гауссовой помехой, заданному классу (4.5.2) должно использовать только статистику из (4.5.9). Разными способами, например, на основе понятия равномерно наиболее мощного критерия для гипотезы со свободной альтернативой, применением минимакса и развиваемыми ниже методами, можно доказать, что эта действительно так, и оптимальное правило принятия решения следующее: принимается, что сигнал принадлежит классу (4.5.2), если
, через которые совместно с выражается функция правдоподобия (4.5.6), несут информацию только о значениях неизвестных параметров , уточняя тем самым вид сигнала в пределах класса (4.5.2). Исходя из этого, а также из полной неопределенности для альтернативной ситуации, кажется достаточно правдоподобным, что оптимальное правило решения о соответствии сигнала , наблюдаемого в смеси с гауссовой помехой, заданному классу (4.5.2) должно использовать только статистику из (4.5.9). Разными способами, например, на основе понятия равномерно наиболее мощного критерия для гипотезы со свободной альтернативой, применением минимакса и развиваемыми ниже методами, можно доказать, что эта действительно так, и оптимальное правило принятия решения следующее: принимается, что сигнал принадлежит классу (4.5.2), если
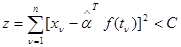 , (4.5.10)
, (4.5.10)
где С - некоторый порог сравнения, который определяется из дополнительных соображений, например, так, чтобы вероятность ошибочно отвергнуть исходную гипотезу имела заданное значение (в силу инвариантности статистики одинаковое для всевозможных значений ).
Аналогичными свойствами строгой или приближенной инвариантности и достаточности обладают статистики, формируемые при использовании известных непараметрических критериев согласия Колмогорова, Смирнова, Мизеса, хи-квадрат и т. д., применяемых в задачах со свободной альтернативой для проверки гипотезы о соответствии данных наблюдения заданному распределению вероятности либо о его неизменности для двух совокупностей наблюденных данных. Исследованию свойств этих статистик посвящена обширная литература, поэтому ограничимся только упоминанием о них.
Приведем еще пример, иллюстрирующий свойство достаточных статистик, связанное с возможностью установления структуры правила решения - функциональной зависимости между и х, о которой шла речь выше. В гл. 2 при обсуждении понятий полного класса решающих правил и достаточной статистики уже приводились некоторые примеры для случая, когда множество решений дискретно. Теперь рассмотрим случай непрерывного множества решений  , когда требуется оценить значение вектора
, когда требуется оценить значение вектора 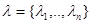 по результатам наблюдения вектора
по результатам наблюдения вектора 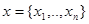 , который представляет собой аддитивную смесь с вектором помехи
, который представляет собой аддитивную смесь с вектором помехи 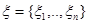 . Решение является вектором
. Решение является вектором 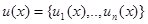 , представляющим собой оценку вектора . Пусть
, представляющим собой оценку вектора . Пусть 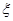 и имеют гауссовы распределения вероятности с корреляционными матрицами (известными либо неизвестными)
и имеют гауссовы распределения вероятности с корреляционными матрицами (известными либо неизвестными) 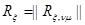 и
и 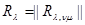 соответственно. Тогда плотность совместного распределения вероятности
соответственно. Тогда плотность совместного распределения вероятности
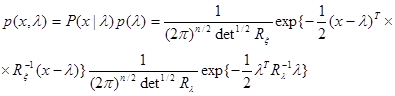 , (4.5.11)
, (4.5.11)
где 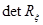 - определитель матрицы
- определитель матрицы 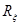 ;
; 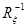 - матрица, обратная (аналогично
- матрица, обратная (аналогично 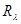 ).
).
Преобразуя выражение (4.5.11), получаем
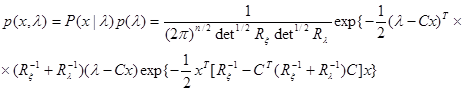 (4.5.12)
(4.5.12)
и апостериорную плотность вероятности
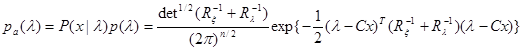 , (4.5.13)
, (4.5.13)
где 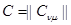 – матрица, определяемая из уравнения
– матрица, определяемая из уравнения
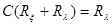 . (4.5.14)
. (4.5.14)
Из (4.5.13) следует, что вектор
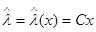 , (4.5.15)
, (4.5.15)
представляющий собой линейное преобразование вектора х с матрицей 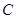 из (4.5.14), является достаточной статистикой (поскольку его размерность совпадает с размерностью вектора , он является также минимальной достаточной статистикой). Поэтому всякое оптимальное решение - оценка вектора для какой-либо функции потерь
из (4.5.14), является достаточной статистикой (поскольку его размерность совпадает с размерностью вектора , он является также минимальной достаточной статистикой). Поэтому всякое оптимальное решение - оценка вектора для какой-либо функции потерь 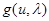 - обязательно является функцией только этой достаточной статистики. Фактически, как уже отмечалось в гл. 2, при слабых ограничениях на функцию потерь оптимальная оценка совпадает с
- обязательно является функцией только этой достаточной статистики. Фактически, как уже отмечалось в гл. 2, при слабых ограничениях на функцию потерь оптимальная оценка совпадает с 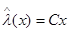 из (4.5.15). Таким образом, если корреляционные матрицы и неизвестны, то есть мы имеем чисто байесову задачу, то нахождение достаточной статистики (4.5.15) уже означает полное решение задачи синтеза оптимальной процедуры оценивания (фильтрации, если индекс имеет смысл дискретного времени, а и значения подлежащего выделению и наблюдаемого процессов в дискретные моменты времени). Если же и полностью или частично неизвестны, то выражение (4.5.15) для достаточной статистики все равно чрезвычайно полезно в том смысле, что устанавливает структуру оптимальной оценки как линейного преобразования вектора х. Это значительно сокращает выбор в условиях априорной неопределенности, поскольку общий вид оптимального алгоритма оценивания ясен и задача заключается только в правильном выборе коэффициентов линейного преобразования (4.5.15).
из (4.5.15). Таким образом, если корреляционные матрицы и неизвестны, то есть мы имеем чисто байесову задачу, то нахождение достаточной статистики (4.5.15) уже означает полное решение задачи синтеза оптимальной процедуры оценивания (фильтрации, если индекс имеет смысл дискретного времени, а и значения подлежащего выделению и наблюдаемого процессов в дискретные моменты времени). Если же и полностью или частично неизвестны, то выражение (4.5.15) для достаточной статистики все равно чрезвычайно полезно в том смысле, что устанавливает структуру оптимальной оценки как линейного преобразования вектора х. Это значительно сокращает выбор в условиях априорной неопределенности, поскольку общий вид оптимального алгоритма оценивания ясен и задача заключается только в правильном выборе коэффициентов линейного преобразования (4.5.15).
Некоторые из приведенных выше примеров свидетельствуют о том, что для нахождения байесова правила решения не обязательно требуется полное знание распределений вероятности х и , а нечто меньшее, что дает возможность найти минимум апостериорного риска. Чтобы определить, какие же конкретные сведения об этих распределениях действительно необходимы для нахождения оптимального правила решения, полезно использовать понятия достаточной статистики. Поясним это на примере. Пусть ставится задача двухальтернативного решения - обнаружения факта наличия сигнала по результатам наблюдения в дискретные моменты времени его смеси с некоторой некоррелированной в различные моменты времени помехой. Данные наблюдения представляют собой последовательность 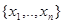 , которая может быть порождена либо только одной помехой, либо смесью сигнала и помехи. Будем считать, что распределение вероятности помехи и способ ее комбинирования с сигналом произвольны.
, которая может быть порождена либо только одной помехой, либо смесью сигнала и помехи. Будем считать, что распределение вероятности помехи и способ ее комбинирования с сигналом произвольны.
В соответствии с этим любая из величин имеет плотность распределения вероятности 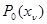 при отсутствии сигнала и
при отсутствии сигнала и 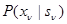 при его наличии, где
при его наличии, где 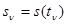 , а
, а 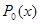 и
и 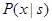 - некоторые произвольные плотности вероятности.
- некоторые произвольные плотности вероятности.
Составляя отношение правдоподобия, которое является минимальной достаточной статистикой для рассматриваемой двухальтернативной задачи, с учетом независимости значений получаем
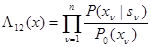 . (4.5.16)
. (4.5.16)
Естественно, что в общем случае для реализации оптимального алгоритма обнаружения, который состоит в сравнение с порогом отношения правдоподобия, требуется знание функций и , то есть статистики помехи и способа комбинирования сигнала с помехой. Предположим теперь, что нас интересует часто встречающийся на практике асимптотический случай слабого сигнала. Тогда с учетом равенства 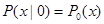
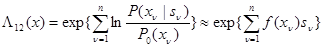 , (4.5.17)
, (4.5.17)
где
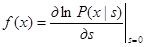 . (4.5.18)
. (4.5.18)
Отношение правдоподобия 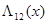 является взаимооднозначной функцией величины
является взаимооднозначной функцией величины
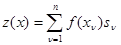 , (4.5.19)
, (4.5.19)
которая также является минимальной достаточной статистикой в рассматриваемом асимптотическом случае; оптимальный алгоритм обнаружения заключается в простом сравнении с порогом величины 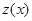 . Для реализации этого алгоритма нужно знать лишь первую производную логарифма условной плотности вероятности при
. Для реализации этого алгоритма нужно знать лишь первую производную логарифма условной плотности вероятности при 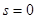 , то есть функцию
, то есть функцию 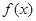 из (4.5.18), которая определяет вид нелинейного преобразования наблюдаемых значений . Другие более детальные сведения о виде распределений и для нахождения оптимального алгоритма просто не требуются, поэтому неопределенность, выходящая за пределы знания вида функции , не является существенной.
из (4.5.18), которая определяет вид нелинейного преобразования наблюдаемых значений . Другие более детальные сведения о виде распределений и для нахождения оптимального алгоритма просто не требуются, поэтому неопределенность, выходящая за пределы знания вида функции , не является существенной.
Аналогично можно рассмотреть большое количество частных, но практически важных задач, однако даже приведенные выше простые примеры достаточно ясно иллюстрируют значение общего подхода, основанного на выделении достаточных статистик и исследовании их структуры.
Дата добавления: 2018-05-10; просмотров: 1104;
Поиск по сайту
Узнать еще
- II. Судовождение с использованием лоцманского метода и графического счисления пути судна.
- А) Строительство гнезд (или использование других убежищ для икры).
- Автоматизированная информационная система организации перевозок грузов по безбумажной технологии с использованием электронной накладной (АИС ЭДВ)
- Автоматизированный асинхронный электропривод с использованием синхронных электромашинных преобразователей частоты.
- Автоматизированный электропривод с использованием ПЧ с ШИР.
- Автоматическая локомотивная сигнализации и ее виды. Общий принцип работы АЛС с использованием рельсовых цепей
- Автомодельного ламинарного течения жидкости в трубе с использованием системы дифференциальных уравнений, описывающих течение жидкости в трубе
- Алгоритм расчета структуры изображения с использованием функции размытия линии.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
