Поиск делением пополам (двоичный поиск, бинарный поиск)
Поиск можно сделать значительно более эффективным, если данные будут упорядочены. Поэтому приведем алгоритм поиска делением пополам, основанный на знании того, что массив A упорядочен, т. е. удовлетворяет условию
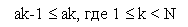
Основная идея - выбрать случайно некоторый элемент, предположим am, и сравнить его с аргументом поиска x. Если он равен x, то поиск заканчивается, если он меньше x, то делается вывод, что все элементы с индексами, меньшими или равными m, можно исключить из дальнейшего поиска; если же он больше x, то исключаются индексы больше и равные m. Выбор m совершенно не влияет на корректность алгоритма, но влияет на его эффективность. Очевидно, что чем большее количество элементов исключается на каждом шаге алгоритма, тем этот алгоритм эффективнее. Оптимальным решением будет выбор среднего элемента, так как при этом в любом случае будет исключаться половина массива.
При каждом сравнении , мы уменьшаем зону поиска в два раза. Отсюда и название метода - половинного деления или дихотомии.
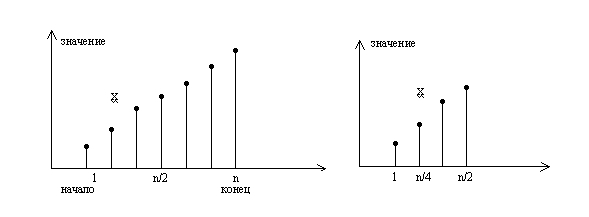
Рис.2.1. Поиск делением пополам
В этом алгоритме используются две индексные переменные L и R, которые отмечают соответственно левый и правый конец секции массива a, где еще может быть обнаружен требуемый элемент.
Алгоритм 1.
L:=0; R:=N-1; Found:=false;
while(L<=R) and not Found do begin
m:=(L+R) div 2;
if a[m]=x then begin
Found:=true
end else begin
if a[m]<x then L:=m+1 else R:=m-1
end
end;
Максимальное число сравнений для этого алгоритма равно log n, округленному до ближайшего целого. Таким образом, приведенный алгоритм существенно выигрывает по сравнению с линейным поиском, где ожидаемое число сравнений N/2.
Эффективность несколько улучшается, если поменять местами заголовки условных операторов. Проверку на равенство можно выполнять во вторую очередь, так как она встречается лишь единожды и приводит к окончанию работы. Но более существенный выигрыш даст отказ от окончания поиска при фиксации совпадения. На первый взгляд это кажется странным, однако, при внимательном рассмотрении обнаруживается, что выигрыш в эффективности на каждом шаге превосходит потери от сравнения с несколькими дополнительными элементами (число шагов в худшем случае равно logN).
Алгоритм 2.
L:=0; R:=N;
while L<R do begin
m:=(L+R) div 2;
if а[m]<x then L:=m+1 else R:=m
end.
Выполнение условия L=R еще не свидетельствует о нахождении требуемого элемента. Здесь требуется дополнительная проверка. Также, необходимо учитывать, что элемент a[R] в сравнениях никогда не участвует. Следовательно, и здесь необходима дополнительная проверка на равенство a[R]=x. Следует отметить, что эти проверки выполняются однократно.
Приведенный алгоритм, как и в случае линейного поиска, находит совпадающий элемент с наименьшим индексом.
Дата добавления: 2018-05-10; просмотров: 1486;
Поиск по сайту
Узнать еще
- IПоисковые каталоги
- MS Word: проверка орфографии, поиск и замена, режимы просмотра документа (обычный, разметки страницы, структура).
- Автоматизация поисковых операций
- Автоматизированные поисковые комплексы
- Автомобильные генераторы – методика поиска основных
- Алгоритм поиска дефектов
- Алгоритмы параллельного поиска и сортировки
- Атака Исчерпывающего Поиска (Exhaustive Search Attack).

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
