Шаг 2. Ввод текстовых файлов в Excel-таблицу с разбиением каждой строки текста на отдельные символы.
При вводе ранее сохраненного текстового файла следует указать тип файла *.*. Это позволит во время выбора видеть в списке все файлы. Укажите свой файл. После этого на экран будет выведено окно Мастер текстов (импорт) – Шаг 1 из 3 (рис. 4).
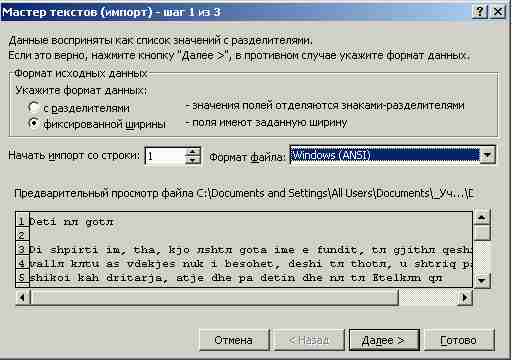
Рис. 4. Окно Мастер текстов (импорт) – шаг 1.
Здесь для размещения букв в отдельных клетках следует указать формат данных фиксированной длины и выбрать подходящий Формат файла.
Далее для перехода к следующему шагу нужно нажать кнопку Далее. На экран выводится окно второго шага (рис. 5).
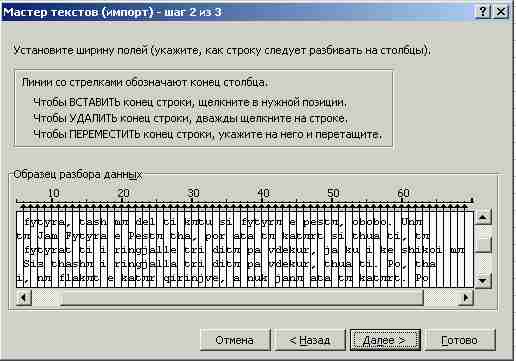
Рис. 5. Окно мастер текстов (импорт) – шаг 2.
В этом окне нужно максимально плотно – через единицу - расставить столбцы. Этим обеспечивается попадание символов по одному в клетки электронной таблицы. Текст следует прокрутить сверху донизу и убедиться, что все символы разнесены по своим столбцам.
Нажимается кнопка Далее, в результате чего на экран выводится окно третьего шага. В этом окне нужно выбрать формат столбца данных текстовый и нажать кнопку Готово.
В результате вы увидите единственный лист рабочей книги с клетками, заполненными буквами вашего текста. Лист будет иметь имя, совпадающее с началом имени файла, в котором был сохранен текст.
Дальнейшие действия определяются возможностями табличного процессора Excel. Имеется в виду прежде всего наличие в нем надстройки Пакет анализа с инструментом Гистограмма.
Инструмент гистограмма удобно использовать при подсчете числа попаданий чисел из некоторого набора и заранее описанные интервалы, называемые карманами. Решаемая нами задача требует измерения вероятностей появления отдельных букв и двухбуквенных комбинаций. Для этого нужно подсчитать количество появлений этих отдельных букв и двухбуквенных комбинаций в тексте. Использование инструмента Гистограмма будет возможно, если преобразовать буквы и двухбуквенные комбинации в числа и задать интервалы для определения числа появления этих чисел.
Следовательно, первое, что нужно сделать – преобразовать буквы в числа. Для этого нужно использовать таблицу для такого преобразования – таблицу кодировки Уникод. В обширном наборе более 320 стандартных функций Excel таких функций сейчас, к сожалению, нет. Однако разработчики Excel для таких случаев предусмотрели возможность создания нестандартных функций, называемых еще функциями пользователя.
Порядок их создания описан в приложении 2
Руководствуясь содержимым приложения 2, создайте следующие нестандартные функции:
· UC_CD для преобразования символа в код с использованием Уникода;
· CD_UC для преобразования кода в символ с использованием Уникода;
· Con16_10 для преобразования числа, записанного в шестнадцатеричной системы счисления в соответствующее число, записанное в десятичной системы счисления;
· Con10_16 для преобразования числа, записанного в шестнадцатеричной системы счисления в соответствующее число, записанное в десятичной системы счисления.
Имена функция выбраны произвольно. Все функции имеют по одному аргументу.
Вместо функций преобразования чисел из шестнадцатеричной формы в десятичную и наоборот можно также использовать стандартный калькулятор Windows.
Теперь для расчетов следует создать дополнительный чистый лист. На этом листе разместим числа-коды, соответствующие символам текста.
Для этого заполним клетки, одноименные аналогичным клеткам с символами формулами, преобразующими символы в код. Надо только иметь в виду возможное наличие среди клеток с символами пустых клеток. Символа в пустой клетке нет. Поэтому преобразование несуществующего символа в код невозможно. С учетом возможных пустых клеток (с пустыми клетками функция UC_CD не работает) формула будет иметь следующий вид:
A1 <- =если(епусто(…..!А1);-1;UC_CD(…..!A1))
Здесь A1 <- означает запись формулы в клетку А1;
епусто – имя функции, проверяющей пустоту клетки, адрес которой указан в качестве аргумента;
…..!А1 – адрес клетки А1, расположенной на листе с именем …… Для ввода этого адресу следует пользоваться режимом указания клетки «мышью». Компьютер сам вписывает нужный адрес.
-1 - это число здесь используется для отметки пустых клеток, поскольку нет символов с кодом -1.
Далее следует скопировать введенную формулу во все клетки, соответствующие клетками с символами исходного рабочего листа.
Шаг 3. Используя инструмент «гистограмма» пакета анализа надстройки Анализ данных, находим частоты появления каждого символа в текстах и по ним находим вероятности их появления в данном языке.
Для использования инструмента Гистограмма нужно подготовить блок клеток с анализируемыми исходными данными и блок клеток с интервалами карманов. Оба блока, естественно, должны быть заполнены числами. Карманы образуют примыкающие один к другому интервалы чисел. С помощью инструмента Гистограмма компьютер подсчитывает количество чисел, попавших в тот или иной карман. Поскольку карманы не перекрываются, каждое из исходных чисел может попасть только в один карман, т.е. посчитано только один раз. Обычно интервалы карманов образуются последовательностью чисел, записанных в столбец. Пример интервала карманов изображен в виде таблицы, изображенной на рис. 6.
Рис. 6. Пример таблицы с набором карманов.
Числами в этой таблице описываются 3 кармана:
1-5, 5-7, 7-16.
Рис. 7. Интервал карманов |
Интервал карманов для нашей задачи должен быть таким, чтобы в карманы попадали отдельные кодовые значения. Уникод предполагает кодирования символов числами от 0 до 65535 с шагом 1, т.е. возможны коды 0, 1, 2, …, 65535. Если заранее известен интервал, в котором находятся коды алфавита заданного вам языка, интервал 0-65536 можно сократить.
Поскольку коды идут с шагом 1, ширину карманов также нужно брать равной 1. Таким образом, интервал карманов будем задавать в виде таблицы, изображенной на рис. 7.
Последние несколько кодов кодовой таблицы в Уникоде не используются. Поэтому карманы для них создавать необязательно. Поэтому таблицу, изображенную на рис. 7, совсем не обязательно продлевать до 65516-ти.
Создайте справа от таблицы с исходными данными таблицу с интервалами карманов. В случае применения формул после получения результатов замените формулы значениями. Это предотвратит в дальнейшем потери времени на пересчеты таблицы (имейте в виду, что пересчет формул выполняется при каждом изменении таблицы). Замена формул значениями произойдет, если вы скопируете клетки, в которых находятся формулы на свое же место, используя специальную вставку с выбором параметра значения.
Для замены формул значениями после переноса копируемой информации в буфер промежуточного хранения (Ctrl+C) нужно выделить место вставки информации из буфера и правой кнопки «мыши» вызвать контекстное меню и в этом меню выбрать пункт Специальная вставка… (Рис. 8).
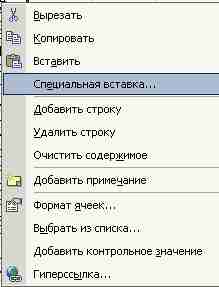
Рис. 8. Выбор пункта контекстного меню Специальная вставка.
Далее в появившемся диалоговом окне Специальная вставка нужно пометить позицию Значения и нажать кнопку ОК (рис. 9).
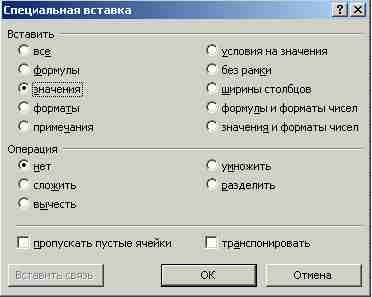
Рис. 9. Окно Специальная вставка
Теперь все готово к использованию инструмента Гистограмма.
Excel – сложная программа, сильно загружающая компьютер. Поэтому разработчики предусмотрели возможность подключения к ней по мере необходимости модулей, называемых надстройками. Нужный нам инструмент Гистограмма входит в состав надстройки Пакет анализа. Обычно эта надстройка отключена. Поэтому сначала нужно ее подключить. Для подключения или отключения надстроек используется меню Сервис –> Надстройки (рис. 10).
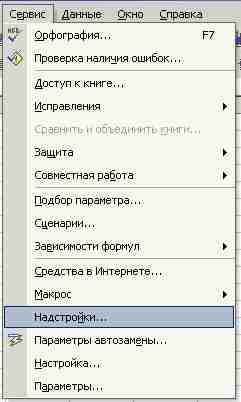
Рис. 10. Выбор пункта меню Надстройки.
В результате на экран высвечивается диалоговое окно Надстройки, в котором с помощью флажков помечаются нужные надстройки (рис. 11).
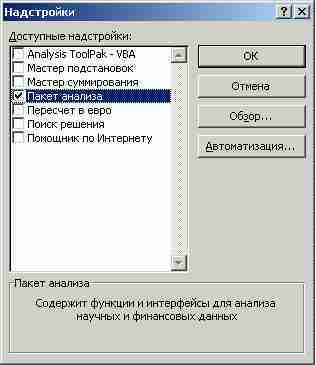
Рис. 11. Окно Надстройки
А нашем случае нужно пометить флажком опцию Пакет анализа и нажать ОК.
Эти действия приведут к появлению в меню нового пункта Сервис –> Анализ данных (рис. 12).
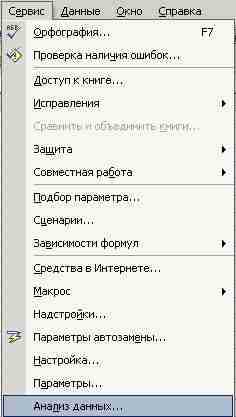
Рис. 12. Появление пункта меню Анализ данных.
Его и следует выбрать.
На экран будет выведено диалоговое окно Анализ данных с обширным списком инструментов анализа (рис. 13).
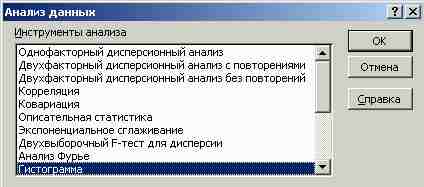
Рис. 13. Окно Анализ данных
Список просматривается при помощи линейки прокрутки. В этом списке нужно пометить элемент Гистограмма и нажать ОК.
В ответ высвечивается окно Гистограмма (рис. 14).
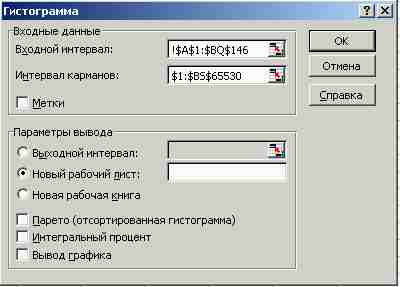
Рис. 14. Окно Гистограмма.
В нем нужно заполнить поля Входной интервал и Интервал карманов. Заполнение идет автоматически по мере указания интервалов клеток «мышью» (ваши данные, естественно, будут отличаться от изображенных на рис. 14).
После нажатия на кнопку ОК через некоторой время на экран будет выведена новая страница (Лист2) со столбцами Карман и Частота. Содержимое столбца Карман указывает на коды символов, а содержимое столбца Частота – на частоту (количество) их появления в тексте. Большинство клеток столбца Частота будет заполнено нулями, что означает, что символов с соответствующими кодами в тексте нет. Первая строка таблицы соответствует несуществующему коду -1. В столбце Частота здесь отображается количество пустых клеток в области исходных данных (с помощью кода -1 мы решили отмечать пустые клетки).
Эта таблица неудобна тем, что на ней не видны сами символы. Это недостаток легко устранить если в в клетки третьего столбца, начиная с С3 ввести формулы вида: С3 <- =CD_UC(A3)
После копирования этой формулы вдоль всего столбца и получения результат их вычисления (это может занять некоторое время) нужно во избежание потерь времени на бесполезный пересчет этих формул заменить их значениями так, как описано выше.
В результате в каждой строке будет высвечен символ, соответствующий коду этой строки.
Для отсева строк с пустыми частотами отфильтруйте только строки с непустыми частотами с помощью автофильтра.
Для того, чтобы автофильтр не мешал дальнейшей обработке данных, скопируйте отфильтрованные данные в буферную память, создайте новый рабочий лист (Лист3) и вставьте данные из буферной памяти в этот лист.
Далее следует проанализировать получившуюся таблицу и, если это явно видно, просуммировать частоты появления больших и соответствующих им маленьких букв. Кроме того, нужно отобрать коды соответствующие только буквам, т.е. нужно отбросить цифры, знаки препинания и т.п. символы. Для отбора букв используйте информацию об Уникоде, помещенную в папке Учебные материалы и на сайте консорциума Уникод (www.unicode.org). В итоге должна быть образована отдельная таблица в виде вертикального столбца с частотами появления букв алфавита, используемых в заданном вариантом языке.
Дата добавления: 2021-04-21; просмотров: 620;
Поиск по сайту
Узнать еще

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
