Распознавание алфавитно-цифровых данных
К задачам распознавания лиц (людей) тесно примыкают и задачи компьютерной обработки фотографий (видеоматериалов) с целью выделения на них алфавитноцифровой информации. Таких задач может быть несколько. Самая распространенная — это перевод текста с бумажного носителя в электронный для последующего редактирования.
Сканер позволяет получить графический образ документа, который непосредственно может быть отредактирован только графическим редактором, например Paint. Такое редактирование могут применить злоумышленники для фальсификации документа, например изменения некоторых дат или денежных сумм. Возможна и замена фамилии лица, в документе, удостоверяющем какие-либо права. Именно такие возможности требуют обязательного наличия заверительной подписи и печати на ксерокопиях документов.
Большую правку текстового документа графическим редактором производить неудобно. Графический образ необходимо преобразовать в текстовый файл. Наиболее распространенной программой для распознавания текстов является FineReader. Это профессиональная, распространяемая на коммерческих условиях программа.
Принцип действия программы FineReader следующий: сканируется любой текст, затем картинка текста преобразуется в «обычный электронный текст», такой, как если бы вы его набрали с клавиатуры. Пользователю остается только сохранить текст на диске или скопировать его через буфер обмена в любой текстовый редактор.
Программа FineReader предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, может распознавать смешанные двуязычные тексты.
С помощью программы FineReader можно выполнять пакетную обработку многострочных документов, а также программу можно «обучать» для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов, она позволяет редактировать распознанный текст, проверять его орфографию и сохранять результаты в текстовом редакторе MS Word, MS Excel.
Программа позволяет объединять сканирование и распознавание в одну операцию.
FineReader автоматически распознает разные участки текста: текст как таковой, картинку (рисунок), таблицу и так называемые «нераспознаваемые» блоки в тексте.
Основные операции обработки бумажного документа в программе FineReader выполняются с помощью панели инструментов Scan&Read. На панели инструментов программы находятся соответствующие кнопки: Сканировать, Распознать, Проверить, Сохранить. Можно выполнять указанные операции и через меню Scan&Readв строке команд.
Процесс обработки документа состоит из следующих шагов:
♦ сканирование документа;
♦ распознавание документа;
♦ редактирование и проверка результата;
♦ сохранение документа.
Первый этап работы — сканирование. На этом этапе используют сканер. Чтобы начать сканирование, необходимо включить сканер, положить оригинал документа (обычно левой стороной вниз) и раскрыть список кнопки Сканировать. В раскрывающемся меню следует выбрать пункт Опциии установить опции Определять ориентацию страницы, Делить разворот книги(если сканируете одновременно две страницы разворота из книги). Использование данных настроек позволяет получить вместо текста в две колонки две обычные странички, с которыми потом работать значительно легче.
Далее необходимо установить настройки сканера:
♦ подбор яркости (рекомендуется автоматический);
♦ режим сканирования (черно-белый режим для документов высокого качества, серый — для большинства документов и цветной — при необходимости сохранения цветных картинок, цвета подложек и букв);
♦ установить нужное разрешение (рекомендуется 300-400 dpi, в зависимости от качества оригинала);
♦ установить паузу между страницами.
После установления необходимых опций непосредственно переходим к сканированию. Кнопка Сканировать(Scan) запускает основной процесс сканирования, в результате которого мы видим на экране получившуюся фотографию. Остается сохранить ее на диске для дальнейшего использования.
Сам процесс сканирования происходит в автоматическом режиме. Если требуется обработать много страниц, то лучше сначала все их отсканировать, а затем приступать к распознаванию. Это связано с тем, что сканирование требует присутствия пользователя из-за необходимости управления сканером (например, для смены страниц), а процесс распознавания может происходить в автоматическом ре жиме.
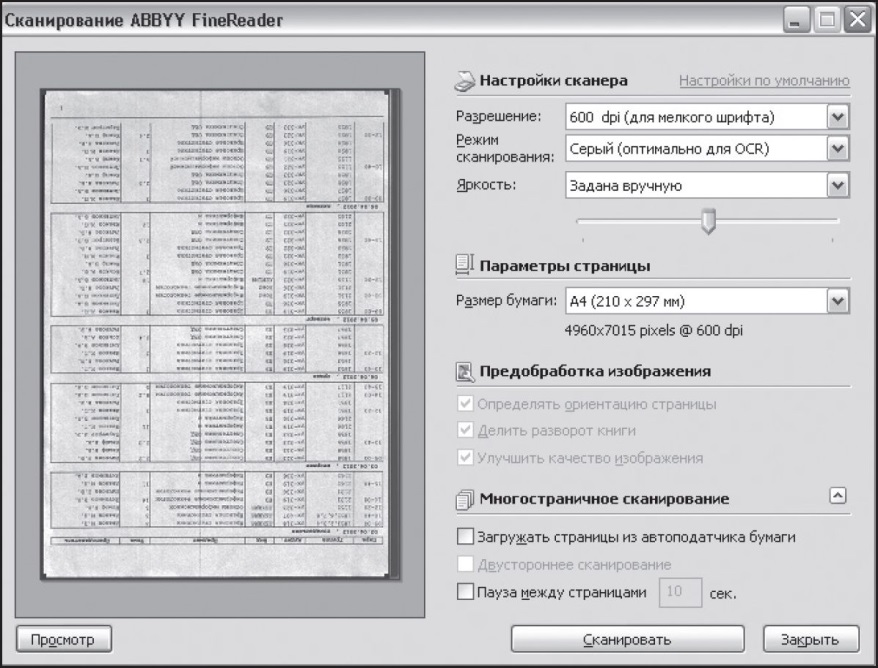 Рис. 9.6. Настройка сканирования
Рис. 9.6. Настройка сканирования
|
Когда процесс сканирования завершается, появляется окно Изображениес графическим текстом.
Второй этап работы — разбиение текста на логические блоки. Дело в том, что в бумажном документе, например, на странице книги или журнала, текст не всегда располагается в фиксированном порядке. Он может размещаться в нескольких колонках (столбцах), содержать иллюстрации (и подписи к ним), другие элементы форматирования. Дополнительные врезки и данные, представленные в таблицах, также могут запутать естественный порядок текста. Поэтому, прежде чем включать текст в документ, его разбивают на блоки, содержащие цельные фрагменты. Блоки распознают последовательно. Полученный текст включается в документ в порядке нумерации блоков.
Для выделения блоков используются инструменты на панели Изображение:
♦ | Ш — удалить выделенные на картинке лишние части блока текста;
♦ К — удалить выделенный блок;
♦ й — выделить табличный блок;
♦ | Ш Тексти Ш — выделить текстовый блок и блок-картинку.
ПРИМЕЧАНИЕ---------------------------------------------------------------------------------------------------
При выделении текстовых блоков следите за тем, чтобы границы блоков совпадали с границами текста.
Разные типы блоков обрабатываются программой по-разному. Программа FineReader поддерживает следующие типы блоков:
♦ текстовый (Текст) — на этапе распознавания преобразуется в текст;
♦ табличный (Таблица) — представляет собой набор ячеек, каждая из которых преобразуется в текст по отдельности;
♦ изображение (Картинка) — включается в документ без изменений как графическая иллюстрация, если формат сохранения преобразованного документа допускает вставные объекты.
При автоматическом процессе распознавания определение границ блока производится автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
Третий этап работы программы — непосредственно распознавание. Этот этап обычно не требует вмешательства пользователя, за исключением тех случаев, когда распознавание сопровождается «обучением».
Для большинства случаев сразу после сканирования нужно щелкнуть на кнопке инструмента Распознатьи подтвердить автоматическое определение блоков. Процесс распознавания будет «иллюстрироваться» закраской участков текста. Точность распознавания FineReader около 92-97%, так как при печати книг и газет на бумаге иногда не прилипает или осыпается краска. Это будет хорошо видно в окне Крупный планс увеличенным масштабом.
Результат распознавания отображается в окне Текст. В этом же окне можно проверить и отредактировать распознанный текст. Следуя далее указаниям Мастера Scan&Read, можно либо передать распознанный текст в выбранное приложение или сохранить его на диске, либо продолжить обработку следующих изображений. При настройке обычно требуется установить язык распознавания. Язык распознавания является главным параметром распознавания.
 Язык распознаваемого текста выбирается из списка на панели Распознавание из окна Опции — Распознавание.
Язык распознаваемого текста выбирается из списка на панели Распознавание из окна Опции — Распознавание.
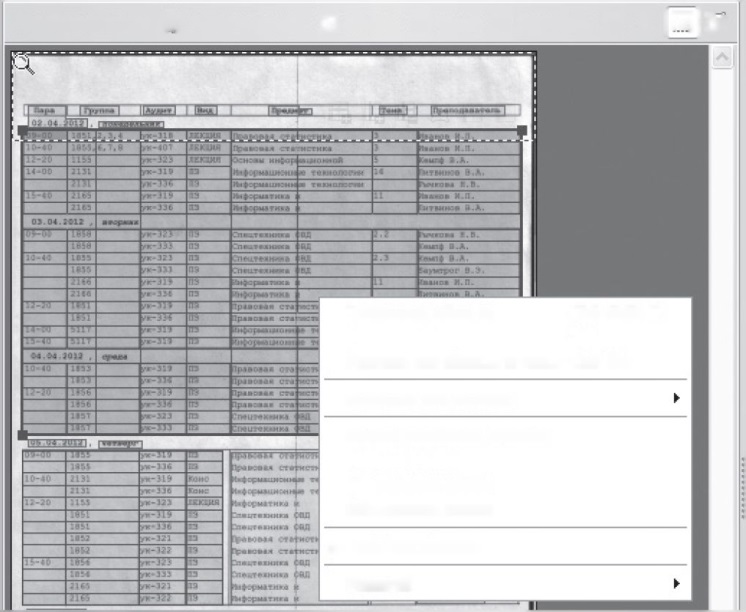
При работе с таблицами для улучшения качества распознавания данных, находящихся в таблицах, желательно проводить анализ структуры таблицы. Для этого необходимо, используя инструмент на панели Изображение Выделить табличный блок, выделить таблицу и, нажав правую кнопку мыши, выбрать опцию Анализ структуры таблицы (рис. 9.7).
Изображение (3^ Редактировать £Л Анализ Щ Текст Щ Картинка Ш ^ |Г~|] pft
Распознать область СМ+БЫ^+В
Удалить область йеі
Удалить все области и текст СїгІ+ОеІ
Изменить тип области
Анализ структуры таблицы
Разбить ячейки Объединить ячейки Объединить строки
✓ Свойства области
Масштаб
Рис. 9.7. Вид окна Анализ структуры таблицы
Программа FineReader является не единственной в своем классе. В сети Интернет можно найти бесплатно распространяемую программу Cuneiform. На рис. 9.8 приведен пример разбиения на блоки текста, распознанного программой Cuneiform.
В большинстве случаев поставляемое со сканерами программное обеспечение также содержит программы распознавания текстов, работающие по принципу FineReader, например, OmniPage SE 4 со сканерами CanoScan Lide.
Близкой к задаче распознавания отсканированного текста является задача по идентификации государственных регистрационных номеров движущихся транспортных средств, фиксации пересечения автомобилем сплошной линии дорожной разметки. Устройством ввода в данном случае будет являться видеокамера. Программы, обрабатывающие видеоданные дорожной обстановки ориентированы на анализ специфических изображений, что позволяет повысить их быстродействие.
Аппаратно-программные комплексы (АПК) семейства «Поток», разработкой которых занимается концерн «Росси»1, могут быть использованы не только для контроля дорожной обстановки, но и при организации пропускной системы на территорию организаций, охраняемые объекты. Для эксплуатации в различных условиях выпускаются несколько модификаций комплексов.
http://www.rossi-potok.ru
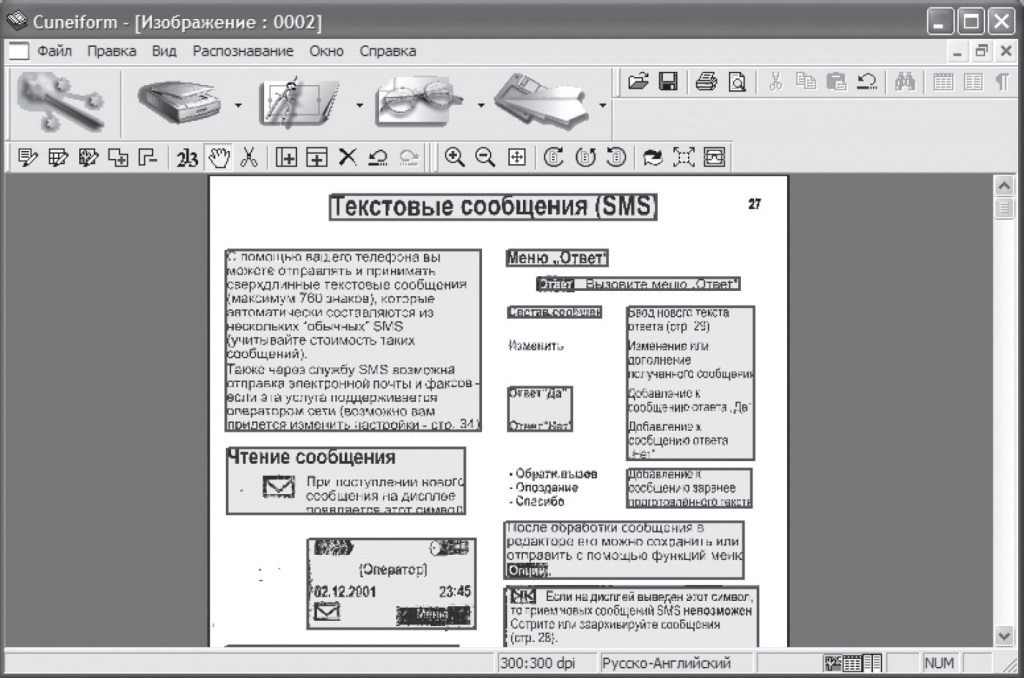 Рис. 9.8. Сегментация текста перед распознаванием
Рис. 9.8. Сегментация текста перед распознаванием
|
Из основных функциональных возможностей, которыми обладают АПК «Поток», можно выделить следующие:
♦ считывание однострочных государственных регистрационных знаков транспортных средств, проследовавших через зоны контроля;
♦ поиск считанных государственных регистрационных знаков транспортных средств в базах данных;
♦ подключение как заранее созданных баз данных, так и созданных на компьютере во время работы системы;
♦ формирование сигнала оператору в случае совпадения государственного регистрационного знака с записью в какой-либо из баз данных или отсутствия его в ней в виде
• стоп-кадра с изображением зафиксированного транспортного средства на экране монитора;
• звуковой сигнализации с оповещением вида базы данных, направления движения зафиксированного транспортного средства и голосового сообщения цифробуквенной последовательности в его номере;
• управления подключенным исполнительным устройством: светофором или шлагбаумом.
Возможна любая комбинация реакций системы.
Для предотвращения хищения автотранспорта или продукции с охраняемой территорий в АПК «Поток» предусмотрены следующие функции:
♦ вывод на экран информации одновременно о въезде и выезде транспортного средства с охраняемой территории (два изображения, время и дата въезда и выезда, время нахождения на территории);
♦ контроль проезда только по разрешенному маршруту и только в разрешенный период времени;
♦ совмещение с весовым контролем;
♦ совмещение с системами видеонаблюдения.
АПК «Поток» способны регистрировать не только нарушения скоростного режима, но и позиционные, например, такие, как выезд на встречную полосу, нарушение правил обгона. Выявляются также нарушения правил остановки и стоянки.
Дата добавления: 2016-10-26; просмотров: 2770;
Поиск по сайту
Узнать еще
- Автоматизация обработки табличных данных (обработка списков)
- Автоматизированные банки данных
- Автоматическая генерация базы данных
- Администрирование данных
- Анализ и интерпретация данных контент-анализа
- Анализ и интерпретация данных экспериментально-психологического исследования
- Анализ исходных данных и формирование материала для эскизного проекта колористического решения интерьера
- Анализ разработки нефтегазовой залежи на основе промысловых данных с помощью метода материального баланса

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
