Состав микрокоманд.
3.1.Микрокоманды
Для управления трактом данных, изображенным на рис. 4.1, нам нужно 29 сигналов Их можно разделить на пять функциональных групп'
• 9 сигналов для записи данных из шины С в регистры.
• 9 сигналов для разрешения передачи регистров на шину В и в АЛУ.
• 8 сигналов для управления АЛУ и схемой сдвига.
• 2 сигнала, которые указывают, что нужно осуществить чтение или запись
через регистры MAR/MDR (на рисунке они не показаны)
• 1 сигнал, который указывает, что нужно осуществить вызов из памяти через
регистры PC/MBR (на рисунке также не показан).
Значения этих 29 сигналов управления определяют операции для одного цик-
ла тракта данных. Цикл состоит из передачи значений регистров на шину В, прохождения этих сигналов через АЛУ и схему сдвига, передачи полученных результатов на шину С и записи их в нужный регистр (регистры). Кроме того, если установлен сигнал считывания данных, то в конце цикла после загрузки регистра MAR начинается работа памяти. Данные из памяти помещаются в MBR или MDR в конце следующего цикла, а использоваться эти данные могут в цикле, который идет после него. Другими словами, если считывание из памяти через любой из портов начинается в конце цикла к, то полученные данные еще не могут использоваться в цикле к+1 (ТОЛЬКО В цикле к+2 и позже). Этот процесс объясняется на рис. 4.2. Сигналы управления памятью выдаются только после загрузки регистров MAR и PC, которая происходит на нарастающем фронте синхронизирующего сигнала незадолго до конца цикла 1. Мы предположим, что память помещает результаты на шину памяти в течение одного цикла, поэтому регистры MBR и (или) MDR могут загружаться на следующем нарастающем фронте вместе с другими регистрами. Другими словами, мы загружаем регистр MAR в конце цикла тракта данных и запускаем память сразу после этого. Следовательно, мы не можем ожидать, что результаты считывания будут в регистре MDR в начале следующего цикла, особенно если длительность импульса небольшая. Этого времени будет недостаточно. Поэтому между началом считывания из памяти и использованием этого результата должен помещаться один цикл. Однако во время этого цикла может выполняться не только передача слова из памяти, но и другие операции.
Предположение о том, что работа памяти занимает один цикл, эквивалентно
предположению, что количество успешных обращений в кэш-память составляет 100%. Подобное предположение никогда не может быть истинным, но мы не будем здесь рассказывать о циклах памяти переменной длины, поскольку это не входит в задачи данной книги. Так как регистры MBR и MDR загружаются на нарастающем фронте синхронизирующего сигнала вместе с другими регистрами, они могут считывать во время циклов, в течение которых осуществляется передача нового слова из памяти. Они возвращают старые значения, поскольку прошло еще недостаточно времени для того, чтобы поменять их на новые. Здесь нет никакой двусмысленности: до тех пор, пока новые значения не загрузятся в регистры MBR и MDR на нарастающем фронте сигнала, предыдущие значения находятся там и могут использоваться. Отметим, что считывания могут проходить одно за другим, то есть в двух последовательных циклах (поскольку сам процесс считывания занимает только один цикл). Кроме того, обе памяти могут действовать в одно и то же время. Однако попытка чтения и записи одного и того же байта одновременно приводит к неопределенным результатам. Выходной сигнал шины С можно записывать сразу в несколько регистров, однако нежелательно передавать значения более одного регистра на шину В. Немного расширив схемотехнику, мы можем сократить количество битов, необходимых для выбора одного из возможных источников для запуска шины В. Существует только 9 входных регистров, которые могут запустить шину В (регистры MBR со знаком и без знака учитываются отдельно) Следовательно, мы можем закодировать информацию для шины В в 4 бита и использовать декодер для порождения 16 сигналов управления, 7 из которых не нужны. У разработчиков коммерческих моделей, возможно, было бы большое желание избавиться от одного из регистров, чтобы обойтись 3 битами. Однако мы как ученые предпочитаем иметь один лишний бит,
но при этом получить более ясную и простую разработку.
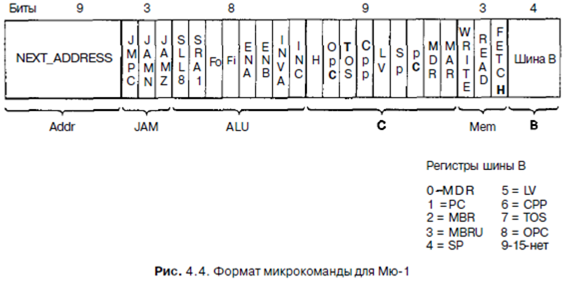
Теперь мы можем управлять трактом данных с помощью 9+4+8+2+1=24 сигналов, следовательно, нам требуется 24 бита. Однако эти 24 бита управляют трактом данных только в течение одного цикла. Задача управления - определить, что нужно делать в следующем цикле. Чтобы включить это в разработку контроллера, мы создадим формат для описания операций, которые нужно выполнить, используя 24 бита управления и два дополнительных поля поле NEXT_ADDRESS (следующий адрес) и поле JAM. Содержание каждого из этих полей мы обсудим позже. На рис. 4.4 изображен один из возможных форматов. Он разделен на следующие
6 групп, содержащие 36 сигналов'
• Addr - содержит адрес следующей потенциальной микрокоманды.
• JAM - определяет, как выбирается следующая микрокоманда.
• ALU - функции АЛУ и схемы сдвига.
• С - выбирает, какие регистры записываются из шины С.
• Mem - функции памяти.
4 В - выбирает источник для шины В (как он кодируется, было показано
выше) Порядок групп в принципе произволен, хотя мы долго и тщательно его подбирали, чтобы избежать пересечений на рис. 4 5. Подобные пересечения на диаграммах часто соответствуют пересечениям проводов на микросхемах. Они сильно затрудняют разработку и их лучше сводить к минимуму.
3.2.Управление микрокомандами: Mic-1
До сих пор мы рассказывали о том, как происходит управление трактом данных, но мы еще не касались того, каким образом решается, какой именно сигнал управления и на каком цикле должен запускаться. Для этого существует контроллер последовательности, который отвечает за последовательность операций, необходимых для выполнения одной команды. Контроллер последовательности в каждом цикле должен выдавать следующую информацию:
1. Состояние каждого сигнала управления в системе.
2. Адрес микрокоманды, которая будет выполняться следующей.
Рисунок 4.5 представляет собой подробную диаграмму полной микроархитектуры нашей машины, которую мы назовем Mic-1. На первый взгляд она может показаться внушительной, но тем не менее ее нужно подробно изучить. Если вы разберетесь во всех прямоугольниках и линиях, изображенных на этом рисунке, вам легче будет понять структуру микроархитектурного уровня. Диаграмма состоит из двух частей: тракта данных (слева), который мы уже подробно обсудили, и блока управления (справа), который мы рассмотрим сейчас. Самой большой и самой важной частью блока управления является управляющая память. Удобно рассматривать ее как память, в которой хранится полная микропрограмма, хотя иногда она реализуется в виде набора логических вентилей. Мы будем называть ее управляющей памятью, чтобы не путать с основной памятью,
доступ к которой осуществляется через регистры MBR и MDR. Функционально управляющая память представляет собой память, которая содержит микрокоманды вместо обычных команд. В нашем примере она содержит 512 слов, каждое из которых состоит из одной 32-битной микрокоманды с форматом, изображенным на рис. 4.4. В действительности не все эти слова нужны, но по ряду причин нам требуются адреса для 512 отдельных слов. Управляющая память отличается от основной памяти тем, что команды, хранящиеся в основной памяти, выполняются в порядке адресов (за исключением ветвлений), а микрокоманды - нет. Увеличение счетчика команд в листинге 2.1 означает, что команда, которая будет выполняться после текущей, - это команда, которая идет вслед за текущей в памяти. Микропрограммы должны обладать большей гибкостью (поскольку последовательности микрокоманд обычно короткие), поэтому они не обладают этим свойством. Вместо этого каждая микрокоманда сама указывает на следующую микрокоманду.
Поскольку управляющая память функционально представляет собой ПЗУ, ей
нужен собственный адресный регистр и собственный регистр данных. Ей не требуются сигналы чтения и записи, поскольку здесь постоянно происходит процесс считывания. Мы назовем адресный регистр управляющей памяти МРС (Microprogram Counter - микропрограммный счетчик). Название не очень подходящее, поскольку микропрограммы не упорядочены явным образом и понятие счетчика тут неуместно, но мы не можем пойти против традиций. Регистр данных мы назовем MIR (Microinstruction Register - регистр микрокоманд). Он содержит текущую микрокоманду, биты которой запускают сигналы управления, влияющие на работу тракта данных.
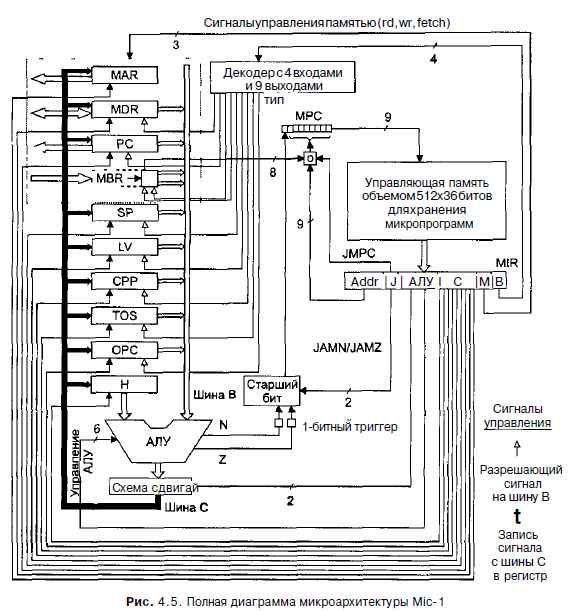
Регистр MIR, изображенный на рис 4 5, содержит те же шесть групп сигналов, которые показаны на рис 4.4. Группы Addr и J (то же, что JAM) контролируют выбор следующей микрокоманды Мы обсудим их чуть позже Группа ALU содержит 8 битов, которые выбирают функцию АЛУ и запускают схему сдвига Биты С загружают отдельные регистры из шины С Сигналы М управляют работой памяти Наконец, последние 4 бита запускают декодер, который определяет, значение какого регистра будет передано на шину В В данном случае мы выбрали декодер, который содержит 4 входа и 16 выходов, хотя имеется всего 9 разных регистров В более проработанной модели мог бы использоваться декодер, имеющий 4 входа и 9 выходов Мы используем стандартную схему, чтобы не разрабатывать свою собственную Использовать стандартную схему гораздо проще, и кроме того, вы сможете избежать ошибок Ваша собственная микросхема займет меньше места,но на ее разработку потребуется довольно длительное время, к тому же вы можете
построить ее неправильно.
Схема, изображенная на рис. 4.5, работает следующим образом. В начале каждого цикла (задний фронт синхронизирующего сигнала на рис. 4.2) в регистр MIR загружается слово из управляющей памяти, которая на рисунке отмечена буквами МРС. Загрузка регистра MIR занимает период Да;, то есть первый подцикл (см. рис. 4.2).
Когда микрокоманда попадает в MIR, в тракт данных поступают различные
сигналы. Значение определенного регистра помещается на шину В, а АЛУ узнает, какую операцию нужно выполнять. Все это происходит во время второго подцикла.
После периода Aw+Ax входные сигналы АЛУ стабилизируются.
После периода Дг/ стабилизируются сигналы АЛУ N и Z и выходной сигнал
схемы сдвига. Затем значения N и Z сохраняются в двух 1-битных триггерах. Эти биты, как и все регистры, которые загружаются из шины С и из памяти, сохраняются на нарастающем фронте синхронизирующего сигнала, ближе к концу цикла тракта данных. Выходной сигнал АЛУ не сохраняется, а просто передается в схему сдвига. Работа АЛУ и схемы сдвига происходит во время подцикла 3.
После следующего интервала, Дг, выходной сигнал схемы сдвига, пройдя через шину С, достигает регистров. Регистры загружаются в конце цикла на нарастающем фронте синхронизирующего сигнала (см. рис. 4.2). Во время подцикла 4 происходит загрузка регистров и триггеров N и Z. Он завершается сразу после нарастающего фронта, когда все значения сохранены, результаты предыдущих операций памяти доступны и регистр МРС загружен. Этот процесс продолжается снова и снова, пока вы не устанете и не выключите компьютер.
Микропрограмме приходится не только управлять трактом данных, но и определять, какая микрокоманда должна быть выполнена следующей, поскольку они не упорядочены в управляющей памяти. Вычисление адреса следующей микрокоманды начинается после загрузки регистра MIR. Сначала в регистр МРС копируется 9-битное поле NEXT_ADDRESS (следующий адрес). Пока происходит копирование, проверяется поле JAM Если оно содержит значение 000, то ничего больше делать не нужно; когда копирование поля NEXT_ADDRESS завершится, регистр МРС укажет на следующую микрокоманду. Если один или несколько бит в поле JAM равны 1, то требуются еще некоторые действия. Если бит JAMN равен 1, то триггер N соединяется через схему ИЛИ со старшим битом регистра МРС. Если бит JAMZ равен 1, то триггер Z соединяется через схему ИЛИ со старшим битом регистра МРС. Если оба бита равны 1, они оба соединяются через схему ИЛИ с тем же битом А теперь объясним, зачем нужны триггеры N и Z. Дело в том, что после нарастающего фронта сигнала (и вплоть до заднего фронта) шина В больше не запускается, поэтому выходные сигналы АЛУ уже не могут считаться правильными. Сохранение флагов состояния АЛУ в регистрах N и Z делает правильные значения стабильными и доступными для вычисления регистра МРС, независимо от того, что происходит вокруг АЛУ. На рис. 4.5 схема, которая выполняет это вычисление, называется «старший бит». Она вычисляет следующую булеву функцию:
F = (0AMZ И Z) ИЛИ QAMN И N)) ИЛИ NEXT_ADDRESS[8]
Пример микроархитектуры 243
Отметим, что в любом случае регистр МРС может принять только одно из двух возможных значений:
1. Значение NEXT_ADDRESS.
2. Значение NEXT_ADDRESS со старшим битом, соединенным с логической
единицей операцией ИЛИ.
Других значений не существует. Если старший бит значения NEXT_ADDRESS уже равен 1, нет смысла использовать JAMN или JAMZ.
Отметим, что если все биты JAM равны 0, то адрес следующей команды - просто 9-битный номер в поле NEXT_ADDRESS- Если JAMN или JAMZ равны 1, то существует два потенциально возможных адреса следующей микрокоманды: NEXT_ADDRESS и NEXT_ADDRESS, соединенный операцией ИЛИ с 0x100 (предполагается, что NEXT_ADDRESS<OxFF). (Отметим, что Ох указывает, что число, следующее за ним, дается в шестнадцатеричной системе счисления). Это проиллюстрировано рис. 4.6. Текущая микрокоманда с адресом 0x75 содержит поле NEXT_ADDRESS=0x92, причем бит JAMZ установлен на 1. Следовательно, следующий адрес микрокоманды зависит от значения бита Z, сохраненного при предыдущей операции АЛУ. Если бит Z равен 0, то следующая микрокоманда имеет адрес 0x92. Если бит Z равен 1, то следующая микрокоманда имеет адрес 0x192.
Третий бит в поле JAM - JMPC. Если он установлен, то 8 битов регистра MBR поразрядно связываются операцией ИЛИ с 8 младшими битами поля NEXT_ADDRESS из текущей микрокоманды. Результат отправляется в регистр МРС. На рис. 4.5 значком «ИЛИ» обозначена схема, которая выполняет операцию ИЛИ над MBR и NEXT_ADDRESS, если бит JMPC равен 1, и просто отправляет NEXT_ADDRESS в регистр МРС, если бит JMPC равен 0. Если JMPC равен 1, то младшие 8 битов поля NEXT_ADDRESS равны 0. Старший бит может быть 0 или 1, поэтому значение поля NEXT_ADDRESS обычно 0x000 или 0x100. Почему иногда используется 0x000, а иногда - 0x100, мы обсудим позже.

Возможность выполнять операцию ИЛИ над MBR и NEXT_ADDRESS и сохранять результат в регистре МРС позволяет реализовывать межуровневые переходы. Отметим, что по битам, находящимся в регистре MBR, можно определить любой адрес из 256 возможных. Регистр MBR содержит код операции, поэтому использование JMPC приведет к единственно возможному выбору следующей микрокоманды. Этот метод позволяет осуществлять быстрый переход у функции, соответствующей вызванному коду операции. Для того чтобы продолжить чтение этой главы, очень важно понимать принципы синхронизации машины, поэтому повторим их еще раз. Синхронизирующий сигнал делится на подциклы, хотя внешние изменения этого сигнала происходят только на заднем фронте, с которого начинается цикл, и на нарастающем фронте, который загружает регистры и триггеры N и Z. Посмотрите еще раз на рис. 4.2. Во время подцикла 1, который инициируется задним фронтом сигнала, адрес, находящийся в данный момент в регистре МРС, загружается в регистр MIR. Во время подцикла 2 регистр MIR выдает сигналы и в шину В загружается выбранный регистр. Во время подцикла 3 происходит работа АЛУ и схемы сдвига. Во время подцикла 4 стабилизируются значения шины С, шин памяти и АЛУ. На нарастающем фронте сигнала загружаются регистры из шины С,загружаются триггеры N и Z, а регистры MBR и MDR получают результаты работы памяти, начавшейся в конце предыдущего цикла (если эти результаты вообще имеются). Как только регистр MBR получает свое значение, загружается регистр МРС. Это происходит где-то в середине отрезка между нарастающим и задним фронтами, но уже после загрузки MBR/MDR. Он может загружаться уровнем сигнала (но не фронтом сигнала) либо загружаться через фиксированный отрезок времени после нарастающего фронта. Все это означает, что регистр МРС не получает своего значения до тех пор, пока не будут готовы регистры MBR, N и Z, от которых он зависит. На заднем фронте сигнала, когда начинается новый цикл, регистр МРС может обращаться к памяти. Отметим, что каждый цикл является самодостаточным. В каждом цикле определяется, значение какого регистра должно поступать на шину В, что должны делать АЛУ и схема сдвига, куда нужно сохранить значение шины С, и, наконец, каким должно быть следующее значение регистра МРС.
Следует сделать еще одно замечание по поводу рис. 4.5. До сих пор мы считали МРС регистром, который состоит из 9 битов и загружается на высоком уровне сигнала. В действительности этот регистр вообще не нужен. Все его входные сигналы можно непосредственно связать с управляющей памятью. Поскольку они имеются в управляющей памяти на заднем фронте синхронизирующего сигнала, когда выбирается и считывается регистр MIR, этого достаточно. Их не нужно хранить в регистре МРС. По этой причине МРС может быть реализован в виде виртуального регистра, который представляет собой просто место скопления сигналов и похож скорее на коммутационное поле, чем на настоящий регистр. Если МРС сделать виртуальным регистром, то процедура синхронизации сильно упрощается:
теперь события происходят только на нарастающем фронте и заднем фронте сигнала. Но если вам проще считать МРС реальным регистром, то такой подход тоже вполне допустим.
Лекция 10. Основы разработки микроархитектурного уровня.
1. Принцип скорости и стоимости.
2. Принцип сокращения длины пути обработки команды.
3. Упреждающая выборка команд.
4. Конвейерная архитектура.
Скорость и стоимость
С развитием технологий скорость работы компьютеров стремительно растет. Существует три основных подхода, которые позволяют увеличить скорость выполнения операций:
1. Сокращение количеств циклов, необходимых для выполнения команды.
2. Упрощение организации машины таким образом, чтобы можно было сде-
лать цикл короче.
3. Выполнение нескольких операций одновременно.
Первые два подхода очевидны, но существует огромное количество различных вариантов разработки, которые могут очень сильно повлиять на число циклов, период или (что бывает чаще всего) и то и другое вместе. В этом разделе мы приведем пример того, как кодирование и декодирование операции могут подействовать на цикл.
Число циклов, необходимых для выполнения набора операций, называется
длиной пути. Иногда длину пути можно уменьшить с помощью дополнительного аппаратного обеспечения. Например, если к регистру PC добавить инкрементор (по сути, это сумматор, у которого один из входов постоянно связан с единицей), то нам больше не придется использовать для этого АЛУ, и следовательно, количество циклов сократится. Однако такой подход не настолько эффективен, как хотелось бы. Часто в том же цикле, в котором значение PC увеличивается на 1, происходит еще и операция чтения, и следующая команда в любом случае не может начаться раньше, поскольку она зависит от данных, которые должны поступить из памяти.
Для сокращения числа циклов, необходимых для вызова команды, требуется
нечто большее, чем простое добавление схемы, которая увеличивает PC на 1. Чтобы повысить скорость вызова команды, нужно применить третью технологию - параллельное выполнение команд. Весьма эффективно отделение схем для вызова команд (8-битного порта памяти и регистров PC и MBR), если этот блок сделать функционально независимым от основного тракта данных. Таким образом, он может сам вызывать следующий код операции или операнд. Возможно, он даже будет работать асинхронно относительно другой части процессора и вызывать одну или несколько команд заранее. Один из наиболее трудоемких процессов при выполнении команд - вызов двубайтного смещения и сохранение его в регистре Н для подготовки к сложению (например, при переходе к РС±п байтов). Одно из возможных решений – увеличить порт памяти до 16 битов, но это сильно усложняет операцию, поскольку требуемые16 битов могут перекрывать границы слова, поэтому даже считывание из памяти 32 битов за один раз не обязательно приведет к вызову обоих нужных нам байтов. Одновременное выполнение нескольких операций - самый продуктивный подход. Он дает возможность очень сильно повысить скорость работы компьютера. Даже простое перекрытие вызова и выполнения команды чрезвычайно эффективно. При более сложных технологиях допустимо одновременное выполнение нескольких команд. Вообще говоря, эта идея является основой проектов современных компьютеров. Ниже мы обсудим некоторые технические приемы, позволяющие воплотить этот подход. На одной чаше весов находится скорость, на другой - стоимость. Стоимость можно измерять различными способами, но точное определение стоимости дать очень трудно. В те времена, когда процессоры конструировались из дискретных компонентов, достаточно было подсчитать общее число этих компонентов. В настоящее время процессор целиком помещается на одну микросхему, но большие и более сложные микросхемы стоят гораздо дороже, чем более простые микросхемы небольшого размера. Можно подсчитать отдельные компоненты (транзисторы, вентили, функциональные блоки), но обычно это число не так важно, как размер контактного участка, необходимого для интегральной схемы. Чем больше участок, тем больше микросхема. И стоимость микросхемы растет гораздо быстрее, чем занимаемое ею пространство. По этой причине разработчики часто измеряют стоимость
в единицах, применимых к «недвижимости», то есть с точки зрения пространства, которое требуется для микросхемы (предполагаем, что площадь поверхности измеряется в пикоакрах).
В истории компьютерной промышленности одной из наиболее тщательно проработанных микросхем является двоичный сумматор. Были реализованы тысячи проектов, и самые быстрые двоичные сумматоры очень сильно превышают по скорости самые медленные. Естественно, высокоскоростные сумматоры гораздо сложнее низкоскоростных. Специалистам по разработке систем приходится выбирать определенное соотношение скорости и занимаемого пространства. Сумматор - не единственный компонент, допускающий различные варианты разработки. Практически любой компонент системы может быть спроектирован таким образом, что он будет функционировать с более высокой или с более низкой скоростью, при этом, естественно, стоимость разных моделей будет различаться. Главной задачей разработчика является определение тех компонентов системы, усовершенствование которых может максимально повлиять на скорость работы компьютера. Интересно отметить, что если какой-нибудь компонент заменить более быстрым, это не обязательно повлечет за собой повышение общей производительности. В следующих разделах мы рассмотрим некоторые вопросы разработки и возможные соотношения цены и скорости.
Одним из ключевых факторов в определении скорости работы генератора
синхронизирующего сигнала является количество действий, которые должны быть сделаны за один цикл. Очевидно, чем больше действий должно быть сделано, тем длиннее цикл. Однако все не так просто, ведь аппаратное обеспечение способно выполнять некоторые операции параллельно, поэтому в действительности длина цикла зависит от количества последовательных операций в одном цикле. Должен также учитываться объем выполняемого декодирования. Посмотрите на рис. 4.5. Вспомните, что в АЛУ может передаваться значение одного из девяти регистров, и чтобы определить, какой именно регистр нужно выбрать, требуется всего 4 бита в микрокоманде. К сожалению, такая экономия дорого обходится. Схема декодера вносит дополнительную задержку в работу компьютера. Это зна-
чит, что какой бы регистр мы не выбрали, он получит команду немного позже и передаст свое содержимое на шину В немного позже. Следовательно, АЛУ получает входные сигналы и выдает результат также с небольшой задержкой. Соответственно, этот результат поступает на шину С для записи в один из регистров тоже немного позже. Поскольку эта задержка часто является фактором, который определяет длину цикла, это значит, что генератор синхронизирующего сигнала не может функционировать с такой скоростью и весь компьютер должен работать немного медленнее. Таким образом, существует определенная зависимость между скоростью и ценой. Если сократить каждое слово управляющей памяти на 5 битов, это приведет к снижению скорости работы генератора. Инженер при разработке компьютера должен принимать во внимание его предназначение, чтобы сделать правильный выбор. В компьютере с высокой производительностью использовать декодер не рекомендуется, а вот для дешевой машины он вполне подойдет.
Сокращение длины пути
Микроархитектура Mic-1 имеет относительно простую структуру и работает довольно быстро, хотя эти две характеристики очень трудно совместить. В общем случае простые машины не являются высокоскоростными, а высокоскоростные машины довольно сложны. Процессор Mic-1 использует минимум аппаратного обеспечения; 10 регистров, простое АЛУ (см. рис. 3.18), продублированное 32 раза, декодер, схему сдвига, управляющую память и некоторые связующие элементы. Для построения всей системы требуется менее 5000 транзисторов, управляющая память (ПЗУ) и основная память (ОЗУ). Мы уже показали, как можно воплотить IJVM с помощью микропрограммы, используя небольшое количество аппаратного обеспечения. Теперь рассмотрим альтернативные варианты. Сначала мы изучим, какими способами можно снизить количество микрокоманд в одной команде (то есть каким образом можно сократить длину пути), а затем перейдем к другим подходам. Слияние цикла интерпретатора с микропрограммой. В микроархитектуре Mic-1 основной цикл состоит из микрокоманды, которая должна выполняться в начале каждой команды IJVM. В некоторых случаях возможно ее перекрытие предыдущей командой. В каком-то смысле эта идея уже получила свое воплощение. Вспомните, что во время цикла Mainl код следующей операции уже находится в регистре MBR. Этот код операции был вызван или во зремя предыдущего основного цикла (если у предыдущей команды не было операндов), или во время выполнения предыдущей команды. Эту идею можно развивать и дальше. В некоторых случаях основной цикл можно свести к нулю. Это происходит следующим образом. Рассмотрим каждую последовательность микрокоманд, которая завершается переходом к Mainl. Каждый раз основной цикл может добавляться в конце этой последовательности (а не в начале следующей), при этом межуровневый переход дублируется много раз (но всегда с одним и тем же набором целевых объектов). В некоторых случаях микрокоманда Mic-1 может сливаться с предыдущими микрокомандами, поскольку эти команды
не всегда полностью используются. В табл. 4.5 приведена последовательность микрокоманд для команды POP. Основной цикл идет перед каждой командой и после каждой команды, в таблице этот цикл показан только после команды POP. Отметим, что выполнение этой команды занимает 4 цикла: три цикла специальных микрокоманд для команды POP и
один основной цикл.

В табл. 4.6 последовательность сокращена до трех команд за счет того, что в
ц<ткле рор2 АЛУ не используется. Отметим, что в конце этой последовательности сразу осуществляется переход к коду следующей команды, поэтому требуется всего 3 цикла. Этот небольшой трюк позволяет сократить время выполнения следующей микрокоманды на один цикл, поэтому, например, последующая команда IADD сокращается с четырех циклов до трех. Это эквивалентно повышению частоты синхронизирующего сигнала с 250 МГц (каждая микрокоманда по 4 не) до 333 МГц (каждая микрокоманда по 3 не).

Команда POP очень хорошо подходит для такой переработки, поскольку она содержит цикл, в котором АЛУ не используется, а основной цикл требует АЛ У. Таким образом, чтобы сократить длину команды на одну микрокоманду, нужно в этой команде найти цикл, где АЛУ не используется. Такие циклы встречаются нечасто, но все-таки встречаются, поэтому установка цикла Mai nl в конце каждой последовательности микрокоманд вполне целесообразна. Для этого требуется всего лишь небольшая управляющая память. Итак, мы получили первый способ сокращения длины пути: помещение основного цикла в конце каждой последовательности микрокоманд.
Трехшинная архитектура
Что еще можно сделать, чтобы сократить длину пути? Можно подвести к АЛУ две полные входные шины, А и В, и следовательно, всего получится три шины. Все (или, по крайней мере, большинство регистров) должны иметь доступ к обеим входным шинам. Преимущество такой системы состоит в том, что есть возможность складывать любой регистр с любым другим регистром за один цикл. Чтобы увидеть, насколько продуктивен такой подход, рассмотрим реализацию команды ILOAD (табл. 4 7).
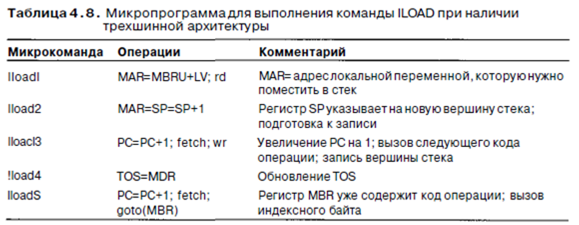
Мы видим, что в микрокоманде iloadl значение LV копируется в регистр Н.
Это нужно только для того, чтобы сложить Н с MBRU в микрокоманде iload2. В разработке с двумя шинами нет возможности складывать два произвольных регистра, поэтому один из них сначала нужно копировать в регистр Н. В трехшинной архитектуре мы можем сэкономить один цикл, как показано в табл. 4.8. Мы добавили основной цикл к команде IL0AD, но при этом длина пути не увеличилась и не уменьшилась. Однако дополнительная шина сокращает общее время выполнения команды с шести циклов до пяти циклов. Теперь мы знаем второй способ сокращения длины пути: переход от двухшинной к трехшинноп архитектуре.

Блок выборки команд
Оба эти способа стоит использовать, но чтобы достичь существенного продвижения, требуется нечто более радикальное. Давайте вернемся чуть-чуть назад и рассмотрим обычные составные части любой команды: поле вызова и поле декодирования. Отметим, что в каждой команде могут происходить следующие операции:
1. Значение PC пропускается через АЛУ и увеличивается на 1.
2. PC используется для вызова следующего байта в потоке команд.
3. Операнды считываются из памяти.
4. Операнды записываются в память.
5. АЛУ выполняет вычисление, и результаты сохраняются в памяти.
Если команда содержит дополнительные поля (для операндов), каждое поле
должно вызываться эксплицитно по одному байту. Поле можно использовать только после того, как эти байты будут объединены. При вызове и компоновке поля АЛУ должно для каждого байта увеличивать PC на единицу, а затем объединять получившийся индекс или смещение. Когда помимо выполнения основной работы команды приходится вызывать и объединять поля этой команды, АЛУ используется практически в каждом цикле. Чтобы объединить основной цикл с какой-нибудь микрокомандой, нужно освободить АЛУ от некоторых таких задач. Для этого можно ввести второе АЛУ, хотя работа полного АЛУ в большинстве случаев не потребуется. Отметим, что АЛУ часто применяется для копирования значения из одного регистра в другой.
Эти циклы можно убрать, если ввести дополнительные тракты данных, которые не проходят через АЛУ. Полезно будет, например, создать тракт от TOS к MDR или от MDR к TOS, поскольку верхнее слово стека часто копируется из одного регистра в другой.
В микроархитектуре Mic-1 с АЛУ можно снять большую часть нагрузки, если создать независимый блок для вызова и обработки команд. Этот блок, который называется блоком выборки команд, может независимо от АЛУ увеличивать значение PC на 1 и вызывать байты из потока байтов до того, как они понадобятся. Этот блок содержит инкрементор, который по строению гораздо проще, чем полный сумматор. Разовьем эту идею. Блок выборки команд может также объединять 8-битные и 16-битные операнды, чтобы они могли использоваться сразу, как только они стали нужны.
Это можно осуществить, по крайней мере, двумя способами:
1. Блок выборки команд может интерпретировать каждый код операции, определять, сколько дополнительных полей нужно вызвать, и собирать их в регистр, который будет использоваться основным операционным блоком.
2. Блок выборки команд может постоянно предоставлять следующие 8- или
16-битные куски информации независимо от того, имеет это смысл или нет.
Тогда основной операционный блок может запрашивать любые данные,
которые ему требуются.
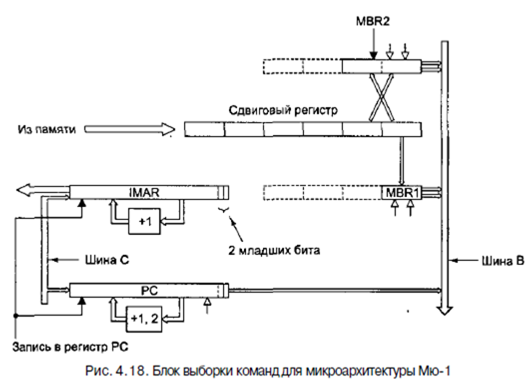
На рис. 4.18 показан второй способ реализации. Вместо одного 8-разрядного
регистра MBR (буферного регистра памяти) здесь есть два регистра MBR: 8-разрядныи MBR1 и 16-разрядный MBR2. Блок выборки команд следит за самым последним байтом или байтами, которые поступили в основной операционный блок. Кроме того, он передает следующий байт в регистр MBR, как и в архитектуре Mic-1, только в данном случае он автоматически определяет, когда значение регистра считано, вызывает следующий байт и сразу загружает его в регистр MBR1. Как и в микроархитектуре Mic-1, он имеет два интерфейса с шиной В: MBR1 и MBR1U. Первый получает знаковое расширение до 32 битов, второй дополнен нулями. Регистр MBR2 функционирует точно так же, но содержит следующие 2 байта. Он имеет два интерфейса с шиной В: MBR2 и MBR2U, первый из которых расширен по знаку, а второй дополнен до 32 битов нулями.
Блок выборки команд отвечает за вызов байтов. Для этого он использует стандартный 4-байтный порт памяти, ввыдает их по одному или по два за раз в том порядке, в котором они вызываются из памяти. Задача сдвигового регистра - сохранить последовательность поступающих байтов для загрузки в регистры MBR1 и MBR2. MBR1 всегда содержит самый старший байт сдвигового регистра, a MBR2 - 2 старших байта (старший байт - левый байт), которые формируют 16-битное целое число (см. рис. 4.14, б). Два байта в регистре MBR2 могут быть из различных
слов памяти, поскольку команды IJVM никак не связаны с границами слов.
Всякий раз, когда считывается регистр MBR1, значение сдвигового регистра
сдвигается вправо на 1 байт. Всякий раз, когда считывается регистр MBR2, значение сдвигового регистра сдвигается вправо на 2 байта. Затем в регистры MBR1 и MBR2 загружается самый старший байт и пара самых старших байтов соответственно. Если в данный момент в сдвиговом регистре осталось достаточно места для целого слова, блок выборки команд начинает цикл обращения к памяти, чтобы считать следующее слово. Мы предполагаем, что когда считывается любой из регистров MBR, он перезагружается к началу следующего цикла, поэтому новое значение можно считывать уже в последующих циклах. Блок выборки команд может быть смоделирован в виде автомата с конечным числом состояний (или конечного автомата), как показано на рис. 4.19. Во всех конечных автоматах есть состояния (на рисунке это кружочки) и переходы (это дуги от одного состояния к другому). Каждое состояние - это одна из возможных ситуаций, в которой может находиться конечный автомат. Данный конечный автомат имеет семь состояний, которые соответствуют семи состояниям сдвигового регистра, показанного на рис. 4.18. Семь состояний соответствуют количеству байтов, которые находятся в данный момент в регистре (от 0 до 6 включительно).
Каждая дуга репрезентирует событие, которое может произойти. В нашем ко-
нечном автомате возможны три различных события. Первое событие - чтение
одного байта из регистра MBR1. Оно активизирует сдвиговый регистр, самый правый байт в нем убирается, и осуществляется переход в другое состояние (меньшее на 1). Второе событие - чтение двух байтов из регистра MBR2. При этом осуществляется переход в состояние, меньшее на 2 (например, из состояния 2 в состояние 0 или из состояния 5 в состояние 3). Оба эти перехода вызывают перезагрузку регистров MBR1 и MBR2. Когда конечный автомат переходит в состояния 0,1 или 2, начинается процесс обращения к памяти, чтобы вызвать новое слово (предполагается, что память уже не занята
Дата добавления: 2016-10-26; просмотров: 3794;
Поиск по сайту
Узнать еще
- IV. Права и обязанности личного состава службы
- V. Подготовка личного состава службы
- VI. Тормоза подвижного состава
- VII. Клей разных составов
- VIII. Сигналы, применяемые для обозначения поездов, локомотивов и другого железнодорожного подвижного состава
- А. КРОВЬ 43. Состав крови
- Автоматизация составления технического задания и технической концепции на проектирование (подбор) муфты
- Автоматизированная система управления тяговым подвижным составом (ДИСТПС)

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
