Символьное кодирование информации.
3.1.Коды символов
У каждого компьютера есть набор символов, который он использует. Как минимум этот набор включает 26 заглавных и 26 строчных букв, цифры от 0 до 9, а также некоторые специальные символы: пробел, точка, запятая, минус, символ возврата каретки и т. д.
Для того чтобы передавать эти символы в компьютер, каждому из них приписывается номер: например, а=1, Ь=2,..., z=26, +=27, -=28. Отображение символов в целые числа называется кодом символов. Важно отметить, что связанные между собой компьютеры должны иметь один и тот же код, иначе они не смогут обмениваться информацией. По этой причине были разработаны стандарты. Ниже мы рассмотрим два самых важных из них.
3.2.ASCII
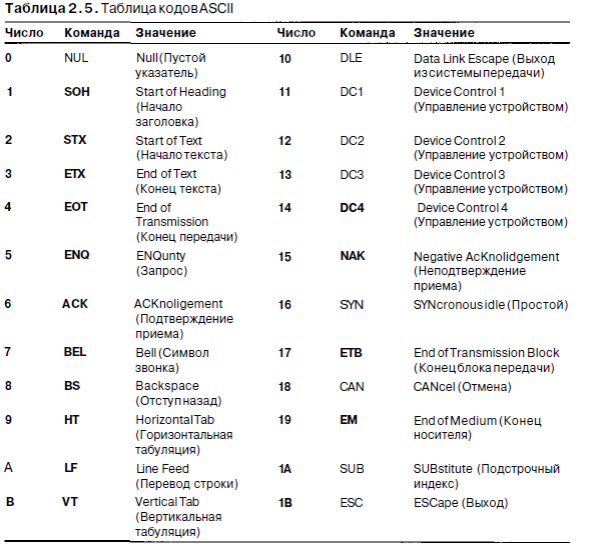
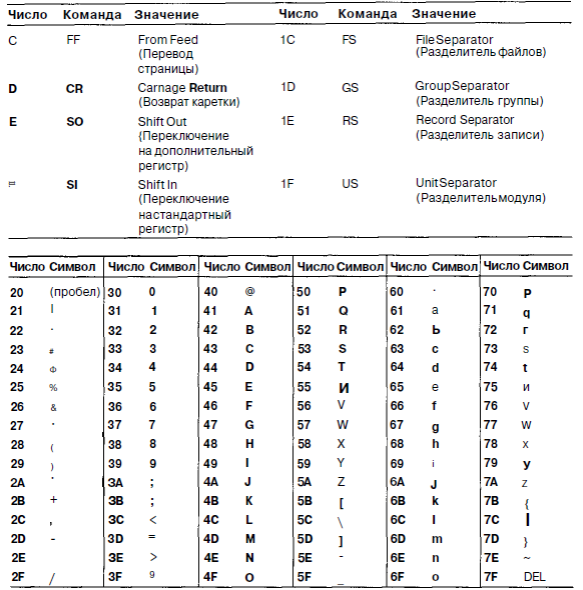
Один широко распространенный код называется ASCII (American Standard Code for Information Interchange - американский стандартный код для обмена информацией) Каждый символ ASCII-кода содержит 7 битов, таким образом, всего может быть 128 символов (табл. 2 5) Коды от 0 до 1F (в шестиадцатеричной системе счисления) соответствуют управляющим символам, которые не печатаются.
Многие непечатные символы ASCII предназначены для передачи данных. Например, послание может состоять из символа начала заголовка SOH (Start of Header), самого заголовка, символа начала текста STX (Start of Text), самого текста, символа конца текста ЕТХ (End of Text) и, наконец, символа конца передачи EOT (End of Transmission). Однако на практике послания, отправляемые по телефонным линиям и сетям, форматируются по-другому, так что непечатные символы передачи ASCII практически не используются.
Печатные символы ASCII наглядны, они включают буквы верхнего и нижнего регистров, цифры, знаки пунктуации и некоторые математические символы.
3.3.UNICODE
Компьютерная промышленность развивалась преимущественно в США, что привело к появлению кода ASCII. Этот код подходит для английского языка, но не очень удобен для других языков. Во французском языке есть надстрочные знаки (например, systeme), в немецком — умляуты (например, far) и т. д. В некоторых европейских языках есть несколько букв, которых нет в ASCII, например, немецкое 3 или датское 0. Некоторые языки имеют совершенно другой алфавит (например, русский или арабский), а у некоторых вообще нет алфавита (например, китайский). Компьютеры распространились по всему свету, и поставщики программного обеспечения хотят реализовывать свою продукцию не только в англоязычных, но и в тех странах, где большинство пользователей не говорят по-английски и где
нужен другой набор символов.
Первой попыткой расширения ASCII был IS 646, который добавлял к ASCII
еще 128 символов, в результате чего получился 8-битный код под названием Latin-1.
Добавлены были в основном латинские буквы со штрихами и диакритическими знаками. Следующей попыткой был IS 8859, который ввел понятие кодовая страница. Кодовая страница — набор из 256 символов для определенного языка или группы языков. IS 8859-1 - это Latin-1. IS 8859-2 включает славянские языки с латинским алфавитом (например, чешский, польский и венгерский). IS 8859-3 содержит символы турецкого, мальтийского, эсперанто и галисийского языков и т. д. Главным недостатком такого подхода является то, что программное обеспечение должно следить, с какой именно кодовой страницей оно имеет дело в данный момент, и при этом невозможно смешивать языки. К тому же эта система не охватывает японский и китайский языки.
Группа компьютерных компаний разрешила эту проблему, создав новую систему под названием UNICODE, и объявила эту систему международным стандартом (IS 10646). UNICODE поддерживается некоторыми языками программирования (например, Java), некоторыми операционными системами (например, Windows NT) и многими приложениями. Вероятно, эта система будет распространяться по всему миру.
Основная идея UNICODE - приписывать каждому символу единственное постоянное 16-битное значение, которое называется указателем кода. Многобайтные символы и escape-последовательности не используются. Поскольку каждый символ состоит из 16 битов, писать программное обеспечение гораздо проще. Так как символы UNICODE состоят из 16 битов, всего получается 65 536 кодовых указателей. Поскольку во всех языках мира в общей сложности около 200 000 символов, кодовые указатели являются очень скудным ресурсом, который нужно распределять с большой осторожностью. Около половины кодов уже распределено, и консорциум, разработавший UNICODE, постоянно рассматривает предложения на распределение оставшейся части. Чтобы ускорить принятие UNICODE, консорциум использовал Latin-1 в качестве кодов от 0 до 255, легко преобразуя ASCII в UNICODE.
Во избежание излишней растраты кодов каждый диакритический знак имеет
свой собственный код. А сочетание диакритических знаков с буквами – задача программного обеспечения. Вся совокупность кодов разделена на блоки, каждый блок содержит 16 кодов. Каждый алфавит в UNICODE имеет ряд последовательных зон. Приведем некоторые примеры (в скобках указано число задействованных кодов): латынь (336), греческий (144), русский (256), армянский (96), иврит (112), деванагари (128), гурмуки(128), ория(128), телугу (128)иканнада(128). Отметим, что каждому из этих языков приписано больше кодов, чем в нем есть букв. Это было сделано отчасти потому, что во многих языках у каждой буквы есть несколько вариантов. Например, каждая буква в английском языке представлена в двух вариантах: там есть строчные и заглавные буквы. В некоторых языках буквы имеют три или более форм, выбор которых зависит от того, где находится буква: в начале, конце или середине слова.
Кроме того, некоторые коды были приписаны диакритическим знакам (112),
знакам пунктуации (112), подстрочным и надстрочным знакам (48), знакам валют (48), математическим символам (256), геометрическим фигурам (96) и рисункам (192). Затем идут символы для китайского, японского и корейского языков. Сначала идут 1024 фонетических символа (например, катакана и бопомофо), затем иероглифы, используемые в китайском и японском языках (20 992), а затем слоги корейского языка (11 156).
Чтобы пользователи могли создавать новые символы для особых целей, существует еще 6400 кодов.
Хотя UNICODE разрешил многие проблемы, связанные с интернационализа-
цией, он все же не мог разрешить абсолютно все проблемы. Например, латинский алфавит упорядочен, а иероглифы - нет, поэтому программа для английского языка может расположить слова «cat? и «dog» по алфавиту, сравнив значение кодов первых букв, а программе для японского языка нужны дополнительные таблицы, чтобы можно было вычислять, в каком порядке расположены символы в словаре.
Еще одна проблема состоит в том, что постоянно появляются новые слова. 50 лет назад никто не говорил об апплетах, киберпространстве, гигабайтах, лазерах, модемах, «смайликах» или видеопленках. С появлением новых слов в английском языке новые коды не нужны. А вот в японском нужны. Кроме новых терминов, необходимо также добавить, по крайней мере, 20 000 новых имен собственных и географических названий (в основном китайских). Шрифт Брайля, которым пользуются слепые, вероятно, тоже должен быть задействован. Представители различных профессиональных кругов также заинтересованы в наличии каких-либо особых символов. Консорциум по созданию UNICODE рассматривает все новые предложения и выносит по ним решения.
UNICODE использует один и тот же код для символов, которые выглядят почти одинаково, но имеют несколько значений или пишутся немного поразному в китайском и японском языках (как если бы английские текстовые процессоры всегда писали слово «blue» как «blew», потому что они произносятся одинаково).
Одни считают такой подход оптимальным для экономии скудного запаса кодов, другие рассматривают его как англо-саксонский культурный империализм (а вы думали, что приписывание символам 16-битных значений не носит политического характера?). Дело усложняется тем, что полный японский словарь содержит 50 000 иероглифических знаков (не считая собственных имен), поэтому при наличии 20 992 кодов приходится делать выбор и чем-то жертвовать. Далеко не все японцы считают, что консорциум компьютерных компаний, даже если некоторые из них японские, является идеальным форумом, чтобы принимать решения, чем именно нужно жертвовать.
Лекция 6. Основные цифровые логические схемы.
1. Интегральные схемы.
2. Комбинационные схемы.
3. Арифметические схемы.
В предыдущих разделах мы увидели, как реализовать простейшие схемы с использованием отдельных вентилей. На практике в настоящее время схемы очень редко конструируются вентиль за вентилем, хотя когда-то это было распространено. Сейчас стандартные блоки представляют собой модули, которые содержат ряд вентилей. В следующих разделах мы рассмотрим эти стандартные блоки более подробно и увидим, как они используются и как их можно построить из отдельных вентилей.
Дата добавления: 2016-10-26; просмотров: 5208;
Поиск по сайту
Узнать еще
- Автоматическая локомотивная сигнализация непрерывного действия с числовым кодированием (АЛСН)
- Алфавитное кодирование, порядок его применения.
- Архивация информации.
- Асинхронное и синхронное кодирование как основа для манчестерского кода.
- Блок дополнительной информации.
- Ввод оперативной маршрутной информации.
- Вспомогательное буферное запоминающее устройство телевизионных графических СОИ. Кодирование информации о графике знаков.
- Вторая стадия: поиск информации.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
