AUTOMATIC TRANSLATION
Translation from one natural language to another is a very important task. The amount of business and scientific texts in the world is growing rapidly, and many countries are very productive in scientific and business domains, publishing numerous books and articles in their own languages. With the growth of international contacts and collaboration, the need for translation of legal contracts, technical documentation, instructions, advertisements, and other texts used in the everyday life of millions of people has become a matter of vital importance.
The first programs for automatic, or machine, translation were developed more than 40 years ago. At first, there existed a hope that texts could be translated word by word, so that the only problem would be to create a dictionary of pairs of words: a word in one language and its equivalent in the other. However, that hope died just after the very first experiments.
Then the ambitious goal was formulated to create programs which could understand deeply the meaning of an arbitrary text in the source language, record it in some universal intermediate language, and then reformulate this meaning in the target language with the greatest possible accuracy. It was supposed that neither manual pre-editing of the source text nor manual post-editing of the target text would be necessary. This goal proved to be tremendously difficult to achieve, and has still not been satisfactorily accomplished in any but the narrowest special cases.
At present there is a lot of translation software, ranging from very large international projects being developed by several institutes or even several corporations in close cooperation, to simple automatic dictionaries, and from laboratory experiments to commercial products. However, the quality of the translations, even for large systems developed by the best scientists, is usually conspicuously lower than the quality of manual human translation.
As for commercial translation software, the quality of translation it generates is still rather low. A commercial translator can be used to allow people quite unfamiliar with the original language of the document to understand its main idea. Such programs can help in manual translation of texts. However, post-editing of the results, to bring them to the degree of quality sufficient for publication, often takes more time than just manual translation made by a person who knows both languages well enough.[4] Commercial translators are quite good for the texts of very specific, narrow genres, such as weather reports. They are also acceptable for translation of legal contracts, at least for their formal parts, but the paragraphs specifying the very subject of the contract may be somewhat distorted.
To give the reader an impression of what kind of errors a translation program can make, it is enough to mention a well-known example of the mistranslation performed by one of the earliest systems in 1960s. It translated the text from Bible The spirit is willing, but the flesh is weak (Matt. 26:41) into Russian and then back into English. The English sentence then turned out to be The vodka is strong, but the meat is rotten [34]. Even today, audiences at lectures on automatic translation are entertained by similar examples from modern translation systems.
Two other examples are from our own experience with the popular commercial translation package PowerTranslator by Globalink, one of the best in the market. The header of an English document Plans is translated into Spanish as the verb Planifica, while the correct translation is the Spanish noun Planes (see Figure III.5). The Spanish phrase el papel de Francia en la guerra is translated as the paper of France in the war, while the correct translation is the role of France in the war. There are thousands of such examples, so that nearly any automatically translated document is full of them and should be reedited.
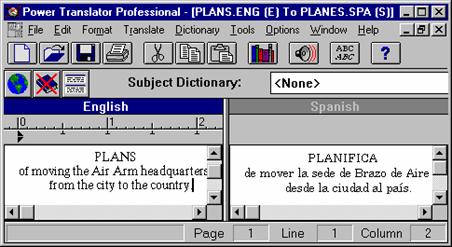 FIGURE III.5. One of commercial translators.
FIGURE III.5. One of commercial translators.
|
Actually, the quality of translation made by a given program is not the same in the two directions, say, from English to Spanish and from Spanish to English. Since automatic analysis of the text is usually a more difficult task than generation of text, the translation from a language that is studied and described better has generally higher quality than translation into this language. Thus, the elaboration of Spanish grammars and dictionaries can improve the quality of the translation from Spanish into English.
One difficult problem in automatic translation is the word sense disambiguation. In any bilingual dictionary, for many source words, dozens of words in the target language are listed as translations, e.g., for simple Spanish word gato: cat, moneybag, jack, sneak thief, trigger, outdoor market, hot-water bottle, blunder, etc. Which one should the program choose in any specific case? This problem has proven to be extremely difficult to solve. Deep linguistic analysis of the given text is necessary to make the correct choice, on the base on the meaning of the surrounding words, the text, as a whole, and perhaps some extralinguistic information [42].
Another, often more difficult problem of automatic translation is restoring the information that is contained in the source text implicitly, but which must be expressed explicitly in the target text. For example, given the Spanish text José le dio a María un libro. Es interesante, which translation of the second sentence is correct: He is interesting, or She is interesting, or It is interesting, or This is interesting? Given the English phrase computer shop, which Spanish translation is correct: tienda de computadora or tienda de computadoras? Compare this with computer memory. Is they are beautiful translated as son hermosos orson hermosas? Is as you wish translated as como quiere, como quieres, como quieren, or como queréis?[5] Again, deep linguistic analysis and knowledge, rather than simple word-by-word translation, is necessary to solve such problems.
Great effort is devoted in the world to improve the quality of translation. As an example of successful research, the results of the Translation group of Information Science Institute at University of South California can be mentioned [53]. This research is based on the use of statistical techniques for lexical ambiguity resolution.
Another successful team working on automatic translation is that headed by Yu. Apresian in Russia [34]. Their research is conducted in the framework of the Meaning Û Text model.
Дата добавления: 2016-09-06; просмотров: 1809;
Поиск по сайту
Узнать еще

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
