AUTOMATIC HYPHENATION
Hyphenation is intended for the proper splitting of words in natural language texts. When a word occurring at the end of a line is too long to fit on that line within the accepted margins, a part of it is moved to the next line. The word is thus wrapped, i.e., split and partially transferred to the next line.
The wrapping can be done only at specific positions within words, which generally, though not always, are syllable boundaries. For example, in Spanish one can split re-ci-bo, re-u-nir-se, dia-blo, ca-rre-te-ra, mu-cha-chas, but not in the following positions: *recib-o, *di-ablo, *car-retera, *muc-hac-has.
In this way, hyphenation improves the outer appearance of computer-produced texts through adjusting their right margins. It saves paper and at the same time preserves impression of smooth reading, just as without any hyphenation.
The majority of the well-known text editors are supplied now with hyphenation tools. For example, Microsoft Word has the menu item Hyphenation.[2]
Usually, the linguistic information taken for such programs is rather limited. It should be known which letters are vowels (a, e, i, o, u in Spanish) or consonants (b, c, d, f, g, etc.), and what letter combinations are inseparable (such as consonants pairs ll, rr, ch or diphthongs io, ue, ai in Spanish).
However, the best quality of hyphenation could require more detailed information about each word. The hyphenation can depend on the so-called morphemic structure of the word, for example: sub-ur-ba-no, but su-bir, or even on the origin of the word, for example: Pe-llicer, but Shil-ler. Only a dictionary-based program can take into account all such considerations. For English, just dictionary-based programs really give perfect results, while for Spanish rather simple programs are usually sufficient, if to neglect potentially error-prone foreign words like Shiller.
SPELL CHECKING
The objective of spell checking is the detection and correction of typographic and orthographic errors in the text at the level of word occurrence considered out of its context.
Nobody can write without any errors. Even people well acquainted with the rules of language can, just by accident, press a wrong key on the keyboard (maybe adjacent to the correct one) or miss out a letter. Additionally, when typing, one sometimes does not synchronize properly the movements of the hands and fingers. All such errors are called typos, or typographic errors. On the other hand, some people do not know the correct spelling of some words, especially in a foreign language. Such errors are called spelling errors.
First, a spell checker merely detects the strings that are not correct words in a given natural language. It is supposed that most of the orthographic or typographic errors lead to strings that are impossible as separate words in this language. Detecting the errors that convert by accident one word into another existing word, such as English then ® ?than or Spanish cazar ® ?casar, supposes a task which requires much more powerful tools.
After such impossible string has been detected and highlighted by the program, the user can correct this string in any preferable way—manually or with the help of the program. For example, if we try to insert into any English text the strings[3] *groop,*greit, or *misanderstand, the spell checker will detect the error and stop at this string, highlighting it for the user. Analogous examples in Spanish can be *caió, *systema, *nesecitar.
The functions of a spell checker can be more versatile. The program can also propose a set of existing words, which are similar enough (in some sense) to the given corrupted word, and the user can then choose one of them as the correct version of the word, without re-typing it in the line. In the previous examples, Microsoft Word’s spell checker gives, as possible candidates for replacement of the string caió, the existing Spanish words shown in Figure III.1.
In most cases, especially for long strings, a spell checker offers only one or two candidates (or none). For example, for the string *systema it offers only the correct Spanish word sistema.
The programs that perform operations of both kinds are called orthographic correctors, while in English they are usually called spell checkers. In everyday practice, spell checkers are considered very helpful and are used by millions of users throughout the world. The majority of modern text editors are supplied now with integrated spell checkers. For example, Microsoft Word uses many spell checkers, a specific one for each natural language used in the text.
The amount of linguistic information necessary for spell checkers is much greater than for hyphenation. A simple but very resource-consuming approach operates with a list, or a dictionary, of all valid words in a specific language. It is necessary to have also a criterion of similarity of words, and some presuppositions about the most common typographic and spelling errors. A deeper penetration into the correction problems requires a detailed knowledge of morphology, since it facilitates the creation of a more compact dictionary that has a manageable size.
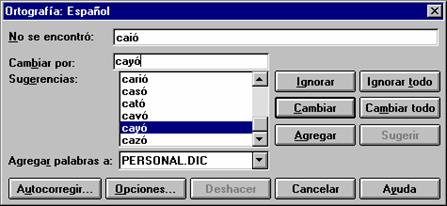 FIGURE III.1. Alternatives for the word *caió.
FIGURE III.1. Alternatives for the word *caió.
|
Spell checkers have been available for more than 20 years, but some quite evident tasks of correction of words, even taken separately, have not been yet solved. To put a specific example, let us consider the ungrammatical string*teached in an English text. None of the spell checkers we have tried suggested the correct form taught. In an analogous way, if a foreigner inserts into a Spanish text such strings as *muestrar or *disponido, the Spanish spell checkers we have tried did not give the forms mostrar and dispuesto as possible corrections.
GRAMMAR CHECKING
Detection and correction of grammatical errors by taking into account adjacent words in the sentence or even the whole sentence are much more difficult tasks for computational linguists and software developers than just checking orthography.
Grammar errors are those violating, for example, the syntactic laws or the laws related to the structure of a sentence. In Spanish, one of these laws is the agreement between a noun and an adjective in gender and grammatical number. For example, in the combination *mujer viejos each word by itself does exist in Spanish, but together they form a syntactically ill-formed combination. Another example of a syntactic agreement is the agreement between the noun in the role of subject and the main verb, in number and person (*tú tiene).
The words that must agree can be located in quite different parts of the sentence. For example, it is rather difficult for a program to find the error in the following sentence: *Las mesas de madera son muy largos.
Other types of grammatical errors include incorrect usage of prepositions, like in the phrases *debajo la puerta, or *¡basta con verla!, or *casarse a María. Some types of syntactic errors may be not so evident even for a native speaker.
It became clear long ago that only a complete syntactic analysis (parsing) of a text could provide an acceptable solution of this task. Because of the difficulty of such parsing, commercial grammar checkers are still rather primitive and rarely give the user useful assistance in the preparation of a text. The Windows Sources, one of the well-known computer journals, noted, in May 1995, that the grammar checker Grammatik in the WordPerfect text editor, perhaps the best grammar checker in the world at that time, was so imperfect and disorienting, that “nobody needs a program that’s wrong in more cases than it’s right.”
In the last few years, significant improvements have been made in grammar checkers. For example, the grammar checker included in Microsoft Word is helpful but still very far from perfection.
Sometimes, rather simple operations can give helpful results by detecting some very frequent errors. The following two classes of errors specific for Spanish language can be mentioned here:
· Absence of agreement between an article and the succeeding noun, in number and gender, like in *la gatos. Such errors are easily detectable within a very narrow context, i.e., of two adjacent words. For this task, it is necessary to resort to the grammatical categories for Spanish words.
· Omission of the written accent in such nouns as *articulo, *genero, *termino. Such errors cannot be detected by a usual spell checker taking the words out of context, since they convert one existing word to another existent one, namely, to a personal form of a verb. It is rather easy to define some properties of immediate contexts for nouns that never occur with the corresponding verbs, e.g., the presence of agreed articles, adjectives, or pronouns [38].
We can see, however, that such simplistic techniques fail in too many cases. For example, in combinations such as *las pruebas de evaluación numerosos, the disagreement between pruebas and numerosos cannot be detected by considering only the nearest context.
What is worse, a program based on such a simplistic approach would too frequently give false alarms where there is no error in fact. For example, in the correct combination las pruebas de evaluación numerosas, such a simplistic program would mention disagreement in number between the wordforms evaluaciónand numerosas.
In any case, since the author of the text is the only person that definitely knows what he or she meant to write, the final decision must always be left up to the user, whether to make a correction suggested by the grammar checker or to leave the text as it was.
STYLE CHECKING
The stylistic errors are those violating the laws of use of correct words and word combinations in language, in general or in a given literary genre.
This application is the nearest in its tasks to normative grammars and manuals on stylistics in the printed, oriented to humans, form. Thus, style checkers play a didactic and prescriptive role for authors of texts.
For example, you are not recommended to use any vulgar words or purely colloquial constructions in official documents. As to more formal properties of Spanish texts, their sentences should not normally contain ten prepositions de, and should not be longer than, let us say, twenty lines. With respect to Spanish lexicon, it is not recommended to use the English words parking and lobby instead of estacionamiento and vestíbulo, or to use the Americanism salvar in the meaning ‘to save in memory’ instead of guardar.
In the Spanish sentence La recolección de datos en tiempo real es realizada mediante un servidor, the words in boldface contain two stylistic anomalies: se realiza is usually better than es realizada, and such a close neighborhood of words with the same stem, like real and realizada, is unwanted.
In the Spanish sentence La grabación, reproducción y simulación de datos son funciones en todos los sistemas de manipulación de información, the frequency of words with the suffix -ción oversteps limits of a good style.
The style checker should use a dictionary of words supplied with their usage marks, synonyms, information on proper use of prepositions, compatibility with other words, etc. It should also use automatic parsing, which can detect improper syntactic constructions.
There exist style checkers for English and some other major languages, but mainly in laboratory versions. Meanwhile commercial style checkers are usually rather primitive in their functions.
As a very primitive way to assess stylistic properties of a text, some commercial style checkers calculate the average length of words in the text, i.e., the number of letters in them; length of sentences, i.e., the number of words in them; length of paragraphs, i.e., the number of words and sentences. They can also use other statistical characteristics that can be easily calculated as a combination of those mentioned.
The larger the average length of a word, sentence or paragraph, the more difficult the text is to read, according to those simplest stylistic assessments. It is easy also to count the occurrences of prepositions de or nouns ending in -ción in Spanish sentences.
Such style checkers can only tell the user that the text is too complicated (awkward) for the chosen genre, but usually cannot give any specific suggestions as to how to improve the text.
The assessment of deeper and more interesting stylistic properties, connected with the lexicon and the syntactic constructions, is still considered a task for the future.
Дата добавления: 2016-09-06; просмотров: 1636;
Поиск по сайту
Узнать еще

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
