SYSTEMS OF LANGUAGE UNDERSTANDING
Natural language understanding systems are the most general and complex systems involving natural language processing. Such systems are universal in the sense that they can perform nearly all the tasks of other language-related systems, such as grammar and style checking, information retrieval, automatic translation, natural language interface, extraction of factual data from texts, text generation, and so forth.
For example, automatic translation can be implemented as a text understanding system, which understands the text in the source language and then generates a precise description of the learned information in the target language.
Hence, creation of a text understanding system is the most challenging task for the joint efforts of computational linguistics and artificial intelligence.
To be more precise, the natural language processing module is only one part of such a system. Most activities related to logical reasoning and understanding proper are concentrated in another its part—a reasoning module. These two modules, however, are closely interrelated and they should work in tight cooperation.
The linguistic subsystem is usually bi-directional, i.e., it can both “understand,” or analyze, the input texts or queries, and produce, or generate, another text as the answer. In other words, this subsystem transforms a human utterance into an internal, or semantic, representation comprehensible to the reasoning subsystem, produces a response in its own internal format, and then transforms the response into a textual answer.
In different systems, the reasoning subsystem can be called the knowledge-based reasoning engine, the problem solver, the expert system, or something else, depending on the specific functions of the whole system. Its role in the whole system of natural language understanding is always very important.
Half a century ago, Alan Turing suggested that the principal test of intelligence for a computer would be its ability to conduct an intelligent dialogue, making reasonable solutions, giving advice, or just presenting the relevant information during the conversation.
This great goal has not been achieved thus far, but research in this direction has been conducted over the past 30 years by specialists in artificial intelligence and computational linguistics.
In order to repeat, the full power of linguistic science and the full range of linguistic data and knowledge are necessary to develop what we can call a true language understanding system.
RELATED SYSTEMS
There are other types of applications that are not usually considered systems of computational linguistics proper, but rely heavily on linguistic methods to accomplish their tasks. Of these we will mention here two, both related to pattern recognition.
Optical character recognition systems recognize the graphemes, i.e., letters, numbers, and punctuation marks, in a point-by-point image of an arbitrary text printed on paper, and convert them to the corresponding ASCII codes. The graphemes can be in any font, typeface or size; the background of the paper can contain some dots and spots. An example of what the computer sees is given in Figure III.6.
A human being easily reads the following text Reglas de interpretación semántica: 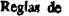

 because he or she understands the meaning of the words. However, without understanding the meaning it is not possible to recognize, say, the first letter of the last string (is it a, s or g?), or the first letter(s) of the second line (is it r, i or m?).
because he or she understands the meaning of the words. However, without understanding the meaning it is not possible to recognize, say, the first letter of the last string (is it a, s or g?), or the first letter(s) of the second line (is it r, i or m?).
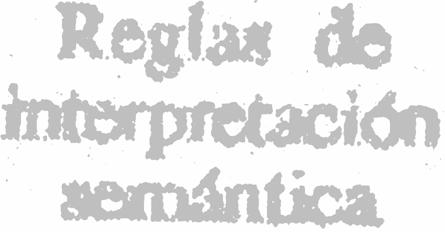 FIGURE III.6. The image of a text, as the computer sees it.
FIGURE III.6. The image of a text, as the computer sees it.
 FIGURE III.7. Several letters of the same text, as the computer sees them.
FIGURE III.7. Several letters of the same text, as the computer sees them.
|
The first letters of the second line are shown separately in Figure III.7. One who does not know what the whole word means, cannot even say for sure that this picture represents any letters. However, one can easily read precisely the same image, shown above, of the same letters in their complete context. Hence, it is obvious that the task of optical character recognition cannot be solved only by the methods of image recognition, without linguistic information.
The image recognition proper is beyond the competence of computational linguistics. However, after the recognition of an image even of much higher quality than the one shown in Figure III.6, some peculiar errors can still appear in the textual representation of the image. They can be fixed by the operations similar to those of a spell checker. Such a specialized spell checker should know the most frequent errors of recognition. For example, the lower-case letter l is very similar to the figure 1, the letter n is frequently recognized as the pair ii, while the m can be recognized as iii or rn. Vice versa, the digraphs in, rn and ni are frequently recognized as m, and so forth.
Most such errors can be corrected without human intervention, on the base of linguistic knowledge. In the simplest case, such knowledge is just a dictionary of words existing in the language. However, in some cases a deeper linguistic analysis is necessary for disambiguation. For example, only full parsing of the context sentence can allow the program to decide whether the picture recognized as *danios actually represents the existing Spanish words darnos or damos.
A much more challenging task than recognition of printed texts is handwriting recognition. It is translation into ASCII form of the texts written by hand with a pen on paper or on the surface of a special computer device, or directly with a mouse on the computer screen. However, the main types of problem and the methods of solution for this task are nearly the same as for printed texts, at least in their linguistic aspect.
Speech recognition is another type of recognition task employing linguistic methods. A speech recognition system recognizes specific sounds in the flow of a speech of a human and then converts them into ASCII codes of the corresponding letters. The task of recognition itself belongs both to pattern recognition and tophonology, the science bordering on linguistics, acoustics, and physiology, which investigates the sounds used in speech.
The difficulties in the task of speech recognition are very similar or quite the same as in optical character recognition: mutilated patterns, fused patterns, disjoint parts of a pattern, lost parts of the pattern, noise superimposing the pattern. This leads to even a much larger number of incorrectly recognized letters than with optical character recognition, and application of linguistic methods, generally in the same manner, is even more important for this task.
CONCLUSIONS
A short review of applied linguistic systems has shown that only very simple tasks like hyphenation or simple spell checking can be solved on a modest linguistic basis. All the other systems should employ relatively deep linguistic knowledge: dictionaries, morphologic and syntactic analyzers, and in some cases deep semantic knowledge and reasoning. What is more, nearly all of the discussed tasks, even spell checking, have to employ very deep analysis to be solved with an accuracy approaching 100%. It was also shown that most of the language processing tasks could be considered as special cases of the general task of language understanding, one of the ultimate goals of computational linguistics and artificial intelligence.
IV. LANGUAGE AS A MEANING Û TEXT TRANSFORMER
IN THIS CHAPTER, we will return to linguistics, to make a review of several viewpoints on natural language, and to select one of them as the base for further studies. The components of the selected approach will be defined, i.e., text and meaning. Then some conceptual properties of the linguistic transformations will be described and an example of these transformations will be given.
Дата добавления: 2016-09-06; просмотров: 1739;
Поиск по сайту
Узнать еще
- ANALOGY IN NATURAL LANGUAGES
- Chief characteristics of the Germanic languages
- Chief characteristics of the Germanic Languages.
- COMMON FEATURES OF MODERN MODELS OF LANGUAGE
- Explore the development of the fuel cell and study the different systems.
- Formation of the National language
- Geographical Expansion of the English Language from the 17th to 19th c. English Outside Great Britain
- GRAMMAR IN THE SYSTEMIC CONCEPTION OF LANGUAGE

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
