TOPICAL SUMMARIZATION
In many cases, it is necessary to automatically determine what a given document is about. This information is used to classify the documents by their main topics, to deliver by Internet the documents on a specific subject to the users, to automatically index the documents in an IRS, to quickly orient people in a large set of documents, and for other purposes.
Such a task can be viewed as a special kind of summarization: to convey the contents of the document in a shorter form. While in “normal” summarization by the contents the main ideas of the document are considered, here we consider only the topics mentioned in the document, hence the term topical summarization.
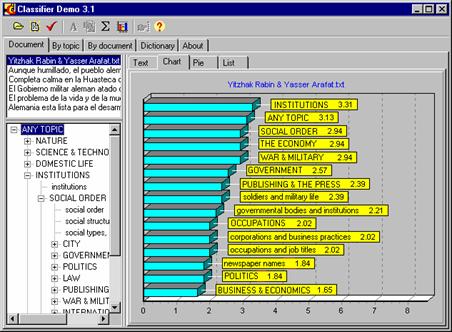 FIGURE III.3. Classifier program determines the main topics of a document.
FIGURE III.3. Classifier program determines the main topics of a document.
|
As an example, let us consider the system Clasitex™ that automatically determines the main topics of a document. A variant of its implementation, Classifier™, was developed in the Center of Computing Research, National Polytechnic Institute at Mexico City [46] (see Figure III.3). It uses two kinds of linguistic information:
· First, it neutralizes morphologic variations in order to reduce any word found in the text to its standard (i.e., dictionary) form, e.g., oraciones ® oración, regímenes ® régimen, lingüísticas ® lingüístico, propuesto ® proponer.
· Second, it puts into action a large dictionary of thesaurus type, which gives, for each word in its standard form, its corresponding position in a pre-defined hierarchy of topics. For example, the word oración belongs to the topic lingüística, which belongs in turn to the topic ciencias sociales, which in its turn belongs to the topic ciencia.
Then the program counts how many times each one of these topics occurred in the document. Roughly speaking, the topic mentioned most frequently is considered the main topic of the document. Actually, the topics in the dictionary have different weights of importance [43, 45], so that the main topic is the one with the greatest total weight in the document.
Applied linguistics can improve this method in many possible ways. For example, in its current version, Clasitex does not count any pronouns found in the text, since it is not obvious what object a personal pronoun such as él can refer to.
What is more, many Spanish sentences contain zero subjects, i.e. implicit references to some nouns. This becomes obvious in English translation: Hay un libro. Es muy interesante Þ There is a book. It is very interesting ÞEl libro es muy interesante. Thus, each Spanish sentence without any subject is implicitly an occurrence of the corresponding word, which is not taken into account by Clasitex, so that the gathered statictics is not completely correct.
Another system, TextAnalystÔ, for determining the main topics of the document and the relationships between words in the document was developed by MicroSystems, in Russia (see Figure III.4). This system is not dictionary-based, though it does have a small dictionary of stop-words (these are prepositions, articles, etc., and they should not be processed as meaningful words).
This system reveals the relationships between words. Words are considered related to each other if they co-occurred closely enough in the text, e.g., in the same sentence. The program builds a network of the relationships between words. Figure III.4 shows the most important words found by TextAnalyst in the early draft of this book, and the network of their relationships.
As in Clasitex, the degree of importance of a word, or its weight, is determined in terms of its frequency, and the relationships between words are used to mutually increase the weights. The words closely related to many of the important words in the text are also considered important.
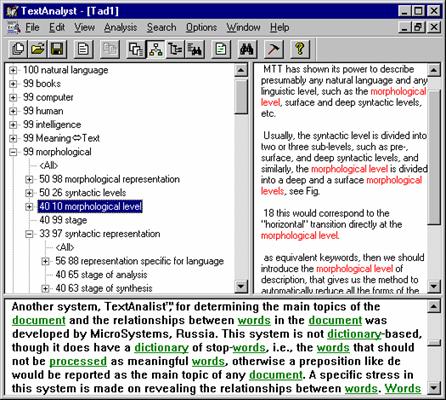 FIGURE III.4. TextAnalyst program reveals the relationships between words.
FIGURE III.4. TextAnalyst program reveals the relationships between words.
|
In TextAnalyst, the list of the important words is used for the following tasks:
· Compression of text by eliminating the sentences or paragraphs that contain the minimal number of important words, until the size of the text reaches the threshold selected by the user,
· Building hypertext by constructing mutual references between the most important words and from the important words to others to which they are supposedly related.
The TextAnalyst technology is based on a special type of a dynamic neural network algorithm. Since the Clasitex program is based on a large dictionary, it is a knowledge-based program, whereas TextAnalyst is not.
Дата добавления: 2016-09-06; просмотров: 1871;
Поиск по сайту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
