Автокорреляция остатков
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений 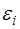 от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями, т.е.
от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями, т.е. 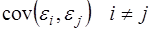 и, в частности, между соседними отклонениями
и, в частности, между соседними отклонениями 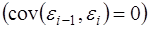 .
.
Автокорреляция (последовательная корреляция) остатков определяется как корреляция между соседними значениями случайных отклонений во времени (временные ряды) или в пространстве (перекрестные данные). Она обычно встречается во временных рядах и очень редко – в пространственных данных. В экономических задачах значительно чаще встречается положительная автокорреляция 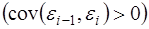 , чем отрицательная автокорреляция
, чем отрицательная автокорреляция 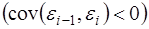 .
.
Чаще всего положительная автокорреляция вызывается направленным постоянным воздействием некоторых не учтенных в регрессии факторов. Например, при исследовании спроса у на прохладительные напитки в зависимости от дохода х на трендовую зависимость накладываются изменения спроса в летние и зимние периоды. Аналогичная картина может иметь место в макроэкономическом анализе с учетом циклов деловой активности.
 |
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать не ежемесячно, а раз в сезон (зима – лето).
| |
Применение МНК к данным, имеющим автокорреляцию в остатках, приводит к таким последствиям:
1. Оценки параметров, оставаясь линейными и несмещенными, перестают быть эффективными. Они перестают быть наилучшими линейными несмещенными оценками.
2. Дисперсии оценок являются смещенными. Часто дисперсии, вычисляемые по стандартным формулам, являются заниженными, что влечет за собой увеличение t – статистик. Это может привести к признанию статистически значимыми факторов, которые в действительности таковыми не являются.
3. Оценка дисперсии регрессии является смещенной оценкой истинного значения σ2, во многих случаях занижая его.
4. Выводы по t – и F – статистикам, возможно, будут неверными, что ухудшает прогнозные качества модели.
Для обнаружения автокорреляции используют либо графический метод, либо статистические тесты. Рассмотрим два наиболее популярных теста.
Метод рядов. По этому методу последовательно определяются знаки отклонений 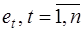 от регрессионной зависимости. Например, имеем при 20 наблюдениях
от регрессионной зависимости. Например, имеем при 20 наблюдениях
(-----)(+++++++)(---)(++++)(-)
Ряд определяется как непрерывная последовательность одинаковых знаков. Количество знаков в ряду называется длиной ряда. Если рядов слишком мало по сравнению с количеством наблюдений n, то вполне вероятна положительная автокорреляция. Если же рядов слишком много, то вероятна отрицательная автокорреляция.
Пусть n – объём выборки, n1 – общее количество положительных отклонений; n2 – общее количество отрицательных отклонений; k – количество рядов. В приведенном примере n=20, n1=11, n2=5.
При достаточно большом количестве наблюдений (n1>10, n2>10) и отсутствии автокорреляции СВ k имеет асимптотически нормальное распределение, в котором
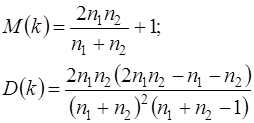
Тогда, если
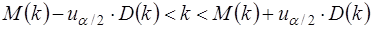
то гипотеза об отсутствии автокорреляции не отклоняется. Если 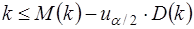 , то констатируется положительная автокорреляция; в случае
, то констатируется положительная автокорреляция; в случае 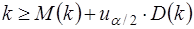 признается наличие отрицательной автокорреляции.
признается наличие отрицательной автокорреляции.
Для небольшого числа наблюдений (n1<20, n2<20) были разработаны таблицы критических значений количества рядов при n наблюдениях. В одной таблице в зависимости от n1 и n2 определяется нижняя граница k1 количества рядов, в другой – верхняя граница k2. Если k1<k<k2, то говорят об отсутствии автокорреляции. Если 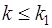 , то говорят о положительной автокорреляции. Если
, то говорят о положительной автокорреляции. Если 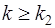 ,то говорят об отрицательной автокорреляции. Например, для приведенных выше данных k1=6, k2=16 при уровне значимости 0,05. Поскольку k=5<k1=6, определяем положительную автокорреляцию.
,то говорят об отрицательной автокорреляции. Например, для приведенных выше данных k1=6, k2=16 при уровне значимости 0,05. Поскольку k=5<k1=6, определяем положительную автокорреляцию.
Критерий Дарбина-Уотсона. Это наиболее известный критерий обнаружения автокорреляции первого порядка. Статистика DW Дарбина-Уотсона приводится во всех специальных компьютерных программах как одна из важнейших характеристик качества регрессионной модели.
Сначала по построенному эмпирическому уравнению регрессии определяются значения отклонений 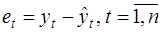 . Рассчитывается статистика
. Рассчитывается статистика
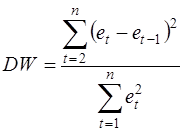
Далее по таблице критических точек Дарбина – Уотсона определяются два числа dl и du и осуществляются выводы по правилу:
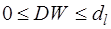 - положительная автокорреляция;
- положительная автокорреляция;
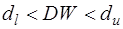 - зона неопределенности;
- зона неопределенности;
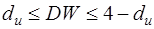 - автокорреляция отсутствует;
- автокорреляция отсутствует;
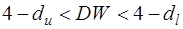 - зона неопределенности;
- зона неопределенности;
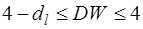 - отрицательная автокорреляция.
- отрицательная автокорреляция.
Можно показать, что статистика DW тесно связана с коэффициентом автокорреляции первого порядка:
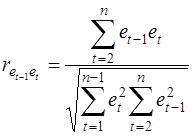
Связь выражается формулой:
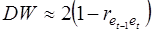
Отсюда вытекает смысл статистического анализа автокорреляции. Поскольку значения r изменяются от –1 до +1, DW изменяется от 0 до 4. Когда автокорреляция отсутствует, коэффициент автокорреляции равен нулю, и статистика DW равна 2. DW=0 соответствует положительной автокорреляции, когда выражение в скобках равно нулю (r=1). При отрицательной автокорреляции (r=-1) DW=4, и выражение в скобках равна двум.
Ограничения критерия Дарбина – Уотсона:
1. Критерий DW применяется лишь для тех моделей, которые содержат свободный член.
2. Предполагается, что случайные отклонения определяются по итерационной схеме
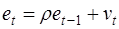 (1)
(1)
называемой авторегрессионной схемой первого порядка AR(1). Здесь vt - случайный член.
3. Статистические данные должны иметь одинаковую периодичность (не должно быть пропусков в наблюдениях).
4. Критерий Дарбина – Уотсона не применим к авторегрессионным моделям вида:
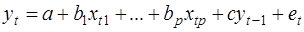
которые содержат в числе факторов также зависимую переменную с временным лагом (запаздыванием) в один период.
Для авторегрессионных моделей предлагается h – статистика Дарбина
 ,
,
где 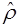 - оценка коэффициента автокорреляции первого порядка (66), D(c) – выборочная дисперсия коэффициента при лаговой переменной yt-1, n – число наблюдений.
- оценка коэффициента автокорреляции первого порядка (66), D(c) – выборочная дисперсия коэффициента при лаговой переменной yt-1, n – число наблюдений.
При большом n и справедливости нуль – гипотезы H0: ρ=0 h~N(0,1). Поэтому при заданном уровне значимости определяется критическая точка из условия
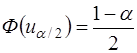 ,
,
и h-статистика сравнивается с uα/2. Если |h|>uα/2, то нуль – гипотеза об отсутствии автокорреляции должна быть отклонена. В противном случае она не отклоняется.
Обычно значение рассчитывается по формуле 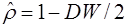 , а D(c) равна квадрату стандартной ошибки mc оценки коэффициента с. Cледует отметить, что вычисление h – статистики невозможно при nD(c)>1.
, а D(c) равна квадрату стандартной ошибки mc оценки коэффициента с. Cледует отметить, что вычисление h – статистики невозможно при nD(c)>1.
Автокорреляция чаще всего вызывается неправильной спецификацией модели. Поэтому следует попытаться скорректировать саму модель, в частности, ввести какой – нибудь неучтенный фактор или изменить форму модели (например, с линейной на полулогарифмическую или гиперболическую). Если все эти способы не помогают и автокорреляция вызвана какими – то внутренними свойствами ряда {et}, можно воспользоваться преобразованием, которое называется авторегрессионной схемой первого порядка AR(1).
Рассмотрим AR(1) на примере парной регрессии:
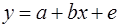 (2)
(2)
Тогда соседним наблюдениям соответствует формула:
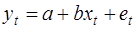 (3)
(3)
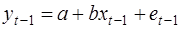 (4)
(4)
Если случайные отклонения определяются выражением (1), где коэффициент ρ известен, то можем получить
 (5)
(5)
Сделаем замены переменных
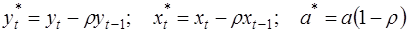 (6)
(6)
получим с учетом (1):
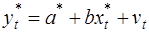
Поскольку случайные отклонения vt удовлетворяют предпосылкам МНК, оценки а* и b будут обладать свойствами наилучших линейных несмещенных оценок. По преобразованным значениям всех переменных с помощью обычного МНК вычисляются оценки параметров а* и b, которые затем можно использовать в регрессии (2).
Однако способ вычисления преобразованных переменных (6) приводит к потере первого наблюдения, если нет информации о предшествующих наблюдениях. Это уменьшает на единицу число степеней свободы, что при больших выборках не очень существенно, однако при малых выборках приводит к потере эффективности. Тогда первое наблюдение восстанавливается с помощью поправки Прайса-Уинстена:
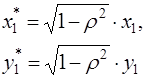
Авторегрессионное преобразование может быть обобщено на произвольное число объясняющих переменных, т.е. использовано для уравнения множественной регрессии.
Для преобразования AR(1) важно оценить коэффициент автокорреляции ρ. Это делается несколькими способами. Самое простое – оценить ρ на основе статистики DW:
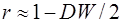
где r берется в качестве оценки ρ. Этот метод хорошо работает при большом числе наблюдений.
В случае, когда есть основания считать, что автокорреляция отклонений очень велика, можно использовать метод первых разностей. В частности, при высокой положительной автокорреляции полагают ρ=1, и уравнение (5) принимает вид

или
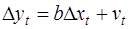 , (7)
, (7)
где 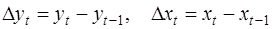 .
.
Из уравнения (9) по МНК оценивается коэффициент b. Параметр а здесь не определяется непосредственно, однако из МНК известно, что 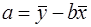 .
.
В случае ρ=-1, сложив (3) и (4) с учетом (1), получаем уравнение регрессии:
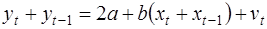
или
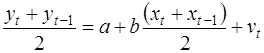 .
.
Дата добавления: 2016-07-27; просмотров: 8052;
Поиск по сайту
Узнать еще
- Автокорреляция в остатках. Критерий Дарбина-Уотсона
- Автокорреляция вещественного сигнала
- Автокорреляция дискретного сигнала
- Автокорреляция уровней временного ряда
- Безвозмездное устранение недостатков
- Возмещение вреда, причиненного вследствие недостатков товаров, работ или услуг. Компенсация морального вреда.
- Выбор видов спорта для укрепления здоровья, коррекции недостатков физического развития и телосложения

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
