Анализ качества эмпирического уравнения множественной линейной регрессии
Проверка статистического качества оцененного уравнения регрессии проводится, с одной стороны, по статистической значимости параметров уравнения, а с другой стороны, по общему качеству уравнения регрессии. Кроме этого, проверяется выполнимость предпосылок МНК.
Сначала рассмотрим первые два вида проверок и связанные с ними вопросы. Некоторые предпосылки МНК и проверки их выполнимости будем рассматривать отдельно.
Как и в случае парной регрессии, статистическая значимость параметров множественной линейной регрессии с р факторами проверяется на основе t – статистики:
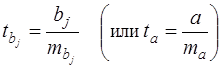 (20)
(20)
где величина 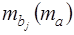 называется стандартной ошибкой параметра
называется стандартной ошибкой параметра 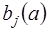 . Она определяется так. Обозначим матрицу:
. Она определяется так. Обозначим матрицу:

и в этой матрице обозначим j – й диагональный элемент как 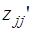 . Тогда выборочная дисперсия эмпирического параметра регрессии равна:
. Тогда выборочная дисперсия эмпирического параметра регрессии равна:
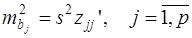 (21)
(21)
а для свободного члена выражение имеет вид:
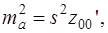 (21’)
(21’)
если считать, что в матрице  индексы изменяются от 0 до р. Здесь S2 – несмещенная оценка дисперсии случайной ошибки ε:
индексы изменяются от 0 до р. Здесь S2 – несмещенная оценка дисперсии случайной ошибки ε:
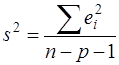 (22)
(22)
Стандартные ошибки параметров регрессии равны
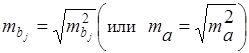 (23)
(23)
Полученная по выражению (20) t – статистика для соответствующего параметра имеет распределение Стьюдента с числом степеней свободы (n-p-1). При требуемом уровне значимости α эта статистика сравнивается с критической точкой распределения Стьюдента t(α; n-p-1) (двухсторонней).
Если |t|>t(α; n-p-1), то соответствующий параметр считается статистически значимым, и нуль – гипотеза в виде Н0:bj=0 или Н0:а=0 отвергается.
В противном случае (|t|<t(α; n-p-1)) параметр считается статистически незначимым, и нуль – гипотеза не может быть отвергнута. Поскольку bj не отличается значимо от нуля, фактор хj линейно не связан с результатом. Его наличие среди объясняющих переменных не оправдано со статистической точки зрения. Не оказывая какого – либо серьёзного влияния на зависимую переменную, он лишь искажает реальную картину взаимосвязи. Поэтому после установления того факта, что коэффициент bj статистически незначим, переменную хj рекомендуется исключить из уравнения регрессии. Это не приведет к существенной потере качества модели, но сделает её более конкретной.
Строгую проверку значимости параметров можно заменить простым сравнительным анализом.
Если 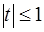 , т.е.
, т.е. 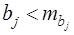 , то коэффициент статистически незначим.
, то коэффициент статистически незначим.
Если  , т.е.
, т.е. 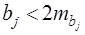 , то коэффициент относительно значим. В данном случае рекомендуется воспользоваться таблицей критических точек распределения Стьюдента.
, то коэффициент относительно значим. В данном случае рекомендуется воспользоваться таблицей критических точек распределения Стьюдента.
Если 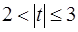 , то коэффициент значим. Это утверждение является гарантированным при (n-p-1)>20 и
, то коэффициент значим. Это утверждение является гарантированным при (n-p-1)>20 и 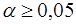 .
.
Если |t|>3, то коэффициент считается сильно значимым. Вероятность ошибки в данном случае при достаточном числе наблюдений не превосходит 0,001.
К анализу значимости коэффициента bj можно подойти по – другому. Для этого строится интервальная оценка соответствующего коэффициента. Если задать уровень значимости α, то доверительный интервал, в который с вероятностью (1-α) попадает неизвестное значение параметра 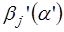 , определяется неравенством:
, определяется неравенством:
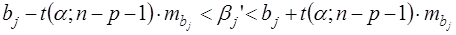 (24)
(24)
или
 (24’)
(24’)
Если доверительный интервал не содержит нулевого значения, то соответствующий параметр является статистически значимым, в противном случае гипотезу о нулевом значении параметра отвергать нельзя.
Для проверки общего качества уравнения регрессии используется коэффициент детерминации R2, который в общем случае рассчитывается по формуле:
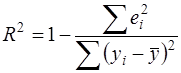 (25)
(25)
Он показывает, как и в парной регрессии, долю общей дисперсии у, объясненную уравнением регрессии. Его значения находятся между нулем и единицей. Чем ближе этот коэффициент к единице, тем больше уравнение регрессии объясняет поведение у.
Для множественной регрессии R2 является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R2. Действительно, каждая следующая объясняющая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной.
В формуле (25) используется остаточная дисперсия, которая имеет систематическую ошибку в сторону уменьшения, тем более значительную, чем больше параметров определяется в уравнении регрессии при заданном объёме наблюдений n. Если число параметров (р+1) приближается к n, то остаточная дисперсия будет близка к нулю и коэффициент детерминации приблизится к единице даже при слабой связи факторов с результатом.
Поэтому в числителе и знаменателе дроби в (25) делается поправка на число степеней свободы остаточной и общей дисперсии соответственно:
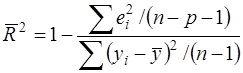 (26)
(26)
Поскольку величина (25), как правило, увеличивается при добавлении объясняющей переменной к уравнению регрессии даже без достаточных на то оснований, скорректированный коэффициент (26) компенсирует это увеличение путем наложения «штрафа» за увеличение числа независимых переменных. Перепишем (26) следующим образом:
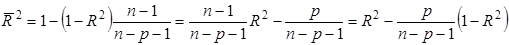 (27)
(27)
По мере роста р увеличивается отношение р/(n-p-1) и, следовательно, возрастает размер корректировки коэффициента R2 в сторону уменьшения.
Из (27) очевидно, что 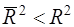 при р>1. С ростом р
при р>1. С ростом р 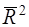 растет медленнее, чем R2. Другими словами, он корректируется в сторону уменьшения с ростом числа объясняющих переменных. При этом
растет медленнее, чем R2. Другими словами, он корректируется в сторону уменьшения с ростом числа объясняющих переменных. При этом 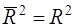 только при R2=1. может даже принимать отрицательные значения (например, при R2=0). Поэтому для корректировки (26) нет строгого математического обоснования.
только при R2=1. может даже принимать отрицательные значения (например, при R2=0). Поэтому для корректировки (26) нет строгого математического обоснования.
Доказано, что увеличивается при добавлении новой объясняющей переменной тогда и только тогда, когда t – статистика для этой переменной по модулю больше единицы. Из этого отнюдь не следует, как можно было бы предположить, что увеличение означает улучшение спецификации уравнения. Тем не менее добавление в модель новых факторов осуществляется до тех пор, пока растет скорректированный коэффициент детерминации.
Обычно приводятся данные как по R2 , так и по , являющиеся суммарными мерами общего качества уравнения регрессии. Однако не следует абсолютизировать значимость коэффициентов детерминации. Существует немало примеров неправильно построенных моделей, имеющих высокие коэффициенты детерминации. Поэтому коэффициент детерминации в настоящее время рассматривается лишь как один из ряда показателей, которые нужно проанализировать, чтобы уточнить строящуюся модель.
Анализ статистической значимости коэффициента детерминации проводится на основе проверки нуль – гипотезы Н0: R2=0 против альтернативной гипотезы Н1: R2>0. Для проверки данной гипотезы используется следующая F – статистика:
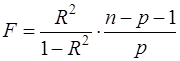 (28)
(28)
Величина F при выполнении предпосылок МНК и при справедливости нуль – гипотезы имеет распределение Фишера. Из (28) видно, что показатели F и R2 равны или не равны нулю одновременно. Если F=0, то R2=0, и линия регрессии 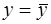 является наилучшей по МНК, и, следовательно, величина у линейно не зависит от
является наилучшей по МНК, и, следовательно, величина у линейно не зависит от 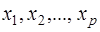 . Для проверки нуль – гипотезы при заданном уровне значимости α по таблицам критических точек распределения Фишера находится критическое значение Fтабл(α; p; n-p-1). Если F>Fтабл, нуль – гипотеза отклоняется, что равносильно статистической значимости R2, т.е. R2>0.
. Для проверки нуль – гипотезы при заданном уровне значимости α по таблицам критических точек распределения Фишера находится критическое значение Fтабл(α; p; n-p-1). Если F>Fтабл, нуль – гипотеза отклоняется, что равносильно статистической значимости R2, т.е. R2>0.
Эквивалентный анализ может быть предложен рассмотрением другой нуль – гипотезы, которая формулируется как 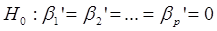 . Эту гипотезу можно назвать гипотезой об общей значимости уравнения регрессии. Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех р объясняющих переменных на зависимую переменную у можно считать статистически несущественным, а общее качество уравнения регрессии невысоким.
. Эту гипотезу можно назвать гипотезой об общей значимости уравнения регрессии. Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех р объясняющих переменных на зависимую переменную у можно считать статистически несущественным, а общее качество уравнения регрессии невысоким.
Проверка такой гипотезы осуществляется на основе дисперсионного анализа сравнения объясненной и остаточной дисперсий, т.е. нуль – гипотеза формулируется как Н0:Dфакт=Dост против альтернативной гипотезы Н1:Dфакт>Dост. При этом строится F – статистика:
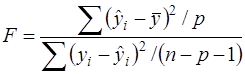 (29)
(29)
Здесь в числителе – объясненная (факторная) дисперсия в расчете на одну степень свободы (число степеней свободы равно числу факторов, т.е. р). В знаменателе – остаточная дисперсия на одну степень свободы. Её число степеней свободы равно (n-p-1). Потеря (р+1) степени свободы связана с необходимостью решения системы (р+1) линейных уравнений при определении параметров эмпирического уравнения регрессии. Если учесть, что число степеней свободы общей дисперсии равно (n-1), то число степеней свободы объясненной дисперсии равна разности (n-1) – (n-p-1), т.е. р. Следует отметить, что выражение (29) эквивалентно (28). Это становится ясно, если числитель и знаменатель (29) разделить на общую СКО:
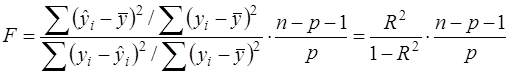
Поэтому методика принятия или отклонения нуль – гипотезы для статистики (29) ничем не отличается от таковой для статистики (28).
Анализ статистики F позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации R2 должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
Например, пусть при оценке регрессии с двумя объясняющими переменными по 30 наблюдениям R2 =0,65. Тогда
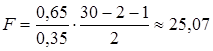
По таблицам критических точек распределения Фишера найдем F(0,05; 2; 27)=3,36; F(0,01; 2; 27)=5,49. Поскольку Fнабл=25,05>Fкр как при 5% - ном, так и при 1% - ном уровне значимости, то нулевая гипотеза в обоих случаях отклоняется. Если в той же ситуации R2=0,4, то
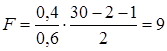
Предположение о незначимости связи отвергается и здесь.
Другим важным направлением использования статистики Фишера является проверка гипотезы о равенстве нулю не всех коэффициентов регрессии одновременно, а только некоторой части этих коэффициентов. Это позволяет оценить обоснованность исключения или добавления в уравнение регрессии некоторых наборов факторов, что особенно важно при совершенствовании линейной регрессионной модели.
Пусть первоначально построенное по n наблюдениям уравнение регрессии имеет вид (4), и коэффициент детерминации для этой модели равен  . Исключим из рассмотрения k объясняющих переменных. Не нарушая общности, предположим, что это будут k последних переменных. По первоначальным n наблюдениям для оставшихся факторов построим другое уравнение регрессии:
. Исключим из рассмотрения k объясняющих переменных. Не нарушая общности, предположим, что это будут k последних переменных. По первоначальным n наблюдениям для оставшихся факторов построим другое уравнение регрессии:
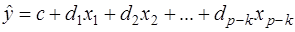 (30)
(30)
для которого коэффициент детерминации равен 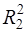 . Очевидно,
. Очевидно, 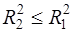 , т.к. каждая дополнительная переменная объясняет часть рассеивания зависимой переменной. Проверяя гипотезу
, т.к. каждая дополнительная переменная объясняет часть рассеивания зависимой переменной. Проверяя гипотезу 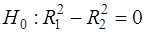 , можно определить, существенно ли ухудшилось качество описания поведения зависимой переменной. Для этого используют статистику:
, можно определить, существенно ли ухудшилось качество описания поведения зависимой переменной. Для этого используют статистику:
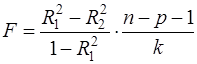 (31)
(31)
В случае справедливости Н0 приведенная статистика имеет распределение Фишера с числом степеней свободы k и (n-p-1). Здесь 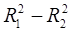 - потеря качества уравнения в результате отбрасывания k факторов; k – число дополнительно появившихся степеней свободы;
- потеря качества уравнения в результате отбрасывания k факторов; k – число дополнительно появившихся степеней свободы;  - необъясненная дисперсия первоначального уравнения.
- необъясненная дисперсия первоначального уравнения.
Если величина (31) превосходит критическое 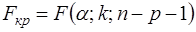 на требуемом уровне значимости α, то нуль – гипотеза должна быть отклонена. В этом случае одновременное исключение из рассмотрения k объясняющих переменных некорректно, т.к. существенно превышает . Это означает, что общее качество первоначального уравнения регрессии существенно лучше качества уравнения регрессии с отброшенными переменными, т.к. первоначальное уравнение объясняет гораздо большую долю разброса зависимой переменной. Если же, наоборот, Fнабл<Fкр, это означает что разность
на требуемом уровне значимости α, то нуль – гипотеза должна быть отклонена. В этом случае одновременное исключение из рассмотрения k объясняющих переменных некорректно, т.к. существенно превышает . Это означает, что общее качество первоначального уравнения регрессии существенно лучше качества уравнения регрессии с отброшенными переменными, т.к. первоначальное уравнение объясняет гораздо большую долю разброса зависимой переменной. Если же, наоборот, Fнабл<Fкр, это означает что разность 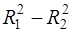 незначительна и можно сделать вывод о целесообразности одновременного отбрасывания k факторов, поскольку это не привело к существенному ухудшению общего качества уравнения регрессии. Тогда нуль – гипотеза не может быть отброшена.
незначительна и можно сделать вывод о целесообразности одновременного отбрасывания k факторов, поскольку это не привело к существенному ухудшению общего качества уравнения регрессии. Тогда нуль – гипотеза не может быть отброшена.
Аналогичные рассуждения можно использовать и для проверки обоснованности включения новых k факторов. В этом случае рассматривается следующая статистика:
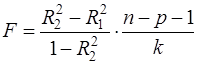 (32)
(32)
Если она превышает критическое значение Fкр, то включение новых факторов объясняет существенную часть не объясненной ранее дисперсии зависимой переменной. Поэтому такое добавление оправдано. Добавлять переменные, как правило, целесообразно по одной. Кроме того, при добавлении факторов логично использовать скорректированный коэффициент детерминации, т.к. обычный R2 всегда растет при добавлении новой переменной, а в скорректированном одновременно растет величина р, уменьшающая его. Если увеличение доли объясненной дисперсии при добавлении новой переменной незначительно, то может уменьшиться. В этом случае добавление указанного фактора нецелесообразно.
Кроме коэффициента детерминации R2, в уравнении множественной регрессии используется другой показатель, тесно связанный с R2. Это так называемый показатель множественной корреляции, равный корню квадратному из R2:
 (33)
(33)
Границы его изменения те же, что и в парной регрессии: от 0 до 1. Чем ближе его значение к единице, тем теснее связь результативного признака со всем набором исследуемых факторов.
Для линейного уравнения множественной регрессии формула индекса корреляции может быть представлена выражением:
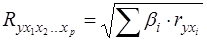 (34)
(34)
где βj – стандартизованные коэффициенты регрессии, 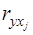 - парные коэффициенты корреляции результата с каждым из факторов.
- парные коэффициенты корреляции результата с каждым из факторов.
Формула индекса множественной корреляции для линейной регрессии получила название линейного коэффициента множественной корреляции, или совокупного коэффициента корреляции.
При линейной зависимости определение совокупного коэффициента корреляции возможно без построения регрессии и оценки её параметров, а с использованием только матрицы парных коэффициентов корреляции:
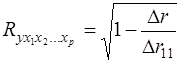 , (35)
, (35)
где Δr – определитель матрицы парных коэффициентов корреляции:
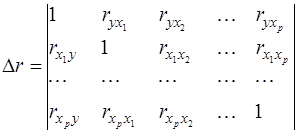 (36)
(36)
а Δr11 – определитель матрицы межфакторной корреляции:
 (37)
(37)
Определитель (37) остаётся после вычеркивания из матрицы коэффициентов парной корреляции первого столбца и первой строки, что и соответствует матрице коэффициентов парной корреляции между факторами.
Дата добавления: 2016-07-27; просмотров: 4257;
Поиск по сайту
Узнать еще
- Case-study (анализ конкретных ситуаций, ситуационный анализ)
- II Расчет и анализ трехфазных цепей
- II. БОЕВЫЕ КАЧЕСТВА
- II. Качественный контроль (социологический анализ).
- II. СРАВНИТЕЛЬНАЯ ОЦЕНКА КАЧЕСТВА ИЗГОТОВЛЕНИЯ ПАЯННЫХ И ЦЕЛЬНОЛИТЫХ ЗУБНЫХ ПРОТЕЗОВ
- III и IV нейроны слухового пути. Третьи и четвертые нейроны слухового проводящего пути. Ядра слухового анализатора. Признаки поражения слухового пути.
- R - полная аэродинамическая сила; Y - подъемная сила; X- сила лобового сопротивления; a- угол атаки;q- угол качества
- VII. Анализ характера

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
