Фиктивные переменные в регрессионных моделях
В регрессионных моделях наряду с количественными переменными часто используются качественные переменные, которые выражаются в виде фиктивных (искусственных) переменных, отражающих два противоположных состояния качественного фактора. Например, D=0, если потребитель не имеет высшего образования, D=1, если потребитель имеет высшее образование. Переменная D называется фиктивной, или двоичной переменной, а также индикатором.
Таким образом, кроме моделей, содержащих только количественные переменные, в регрессионном анализе рассматриваются также модели, содержащие лишь качественные переменные (обозначаемые Di), либо те и другие одновременно.
Регрессионные модели, содержащие лишь качественные объясняющие переменные, называются ANOVA – моделями (моделями дисперсионного анализа).
Например, зависимость начальной заработной платы от образования может быть записана так:
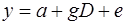 ,
,
где D=0, если претендент на рабочее место не имеет высшего образования, D=1, если имеет. Тогда при отсутствии высшего образования начальная заработная плата равна:
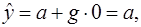
а при его наличии
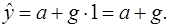
При этом параметр а определяет среднюю начальную заработную плату при отсутствии высшего образования. Коэффициент g показывает, на какую величину отличаются средние начальные заработные платы при наличии и при отсутствии высшего образования у претендента. Проверяя статистическую значимость коэффициента g с помощью t-статистики, можно определить, влияет или нет наличие высшего образования на начальную заработную плату.
Нетрудно заметить, что ANOVA – модели представляют собой кусочно-постоянные функции. Такие модели в экономике крайне редки. Гораздо чаще встречаются модели, содержащие как количественные, так и качественные переменные. Такие модели называются ANCOVA – моделями (моделями ковариационного анализа).
Сначала рассмотрим простую модель заработной платы сотрудника фирмы в зависимости от стажа работы х и пола сотрудника D:
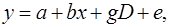 (65)
(65)
где
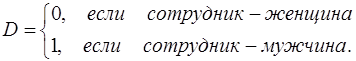
Тогда для женщин ожидаемое значение заработной платы будет
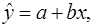
а для мужчин - :
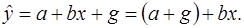
Эти зависимости являются линейными относительно стажа работы х и различаются только величиной свободного члена. Если коэффициент g является статистически значимым, то можно сделать вывод, что в фирме имеет место дискриминация в заработной плате по половому признаку. При g>0 она будет в пользу мужчин, при g<0 – в пользу женщин. На графике такие зависимости изображаются параллельными прямыми.
 |
В случае, когда качественная переменная принимает на два, а большее число значений, может возникнуть ситуация, которая называется ловушкой фиктивной переменной. Она возникает, когда для моделирования k значений качественного признака используется ровно k бинарных (фиктивных) переменных. В этом случае одна из таких переменных линейно выражается через все остальные, и матрица значений переменных становится вырожденной. Тогда исследователь попадает в ситуацию совершенной мультиколлинеарности. Избежать подобной ловушки позволяет правило:
- если качественная переменная имеет k альтернативных значений, то при моделировании используется только (k-1) фиктивных переменных.
Например, если качественная переменная имеет 3 уровня, то для моделирования достаточно двух фиктивных переменных D1 и D2. Тогда для обозначения третьего уровня достаточно принять, например, обе переменные равными нулю: D1=D2=0. В частности, для обозначения уровня экономического развития страны (развитая, развивающаяся или страна «третьего мира») можно использовать обозначения:
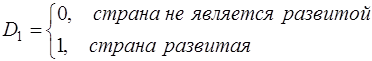
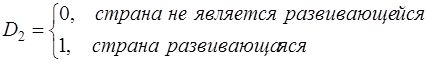
Тогда D1=D2=0 означает страну «третьего мира». Нулевой уровень качественной переменной называется базовым или сравнительным.
Кроме того, значения фиктивных переменных можно изменять на противоположные. Суть модели от этого не изменится. Изменится только знак коэффициента g в модели (65).
Коэффициент g в модели (65) называется дифференциальным свободным членом, т.к. он показывает, на какую величину изменится свободный член модели при изменении значения фиктивной переменной.
Возможны модели, в которых используются несколько фиктивных переменных, не связанных между собой по смыслу. Например, переменная D1 означает пол работника, а D2 – наличие или отсутствие у него высшего образования. Тогда возможны все комбинации значений различных качественных переменных, в которых регрессии отличаются лишь свободными членами.
Подобные схемы можно распространить на произвольное число количественных или качественных факторов. При этом не следует забывать, что если качественный фактор имеет k альтернативных состояний, то для его описания можно использовать только k различных сочетаний значений (k-1) фиктивных переменных. Например, если качественная переменная имеет 4 уровня, то для её описания следует использовать 3 фиктивные (бинарные) переменные. Максимально возможное число сочетаний их значений равно восьми (два в третьей степени), однако в регрессии можно реально использовать только четыре из них.
Влияние качественного фактора может сказываться не только на значении свободного члена, но и на угловом коэффициенте линейной регрессионной модели. Обычно это характерно для временных рядов экономических данных при изменении институциональных условий, введении новых правовых или налоговых ограничений. Тогда зависимость может быть выражена так:
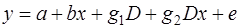 , (81)
, (81)
где
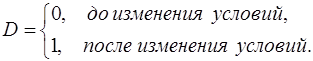
В этой ситуации ожидаемое значение зависимой переменной определяется следующим образом:
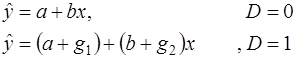
Коэффициенты g1 и g2 называются соответственно дифференциальным свободным членом и дифференциальным угловым коэффициентом. Фиктивная переменная разбивает зависимость на две части – до и после внесения изменений в условия её действия.
 |
|
Общая зависимость имеет вид кусочно-линейной функции, а изменения условий отображаются изменением угла наклона прямой к оси абсцисс (линии 1 – 2).
Здесь исследователь должен принять решение, стоит ли разбивать выборку на части и строить для каждой из них уравнение регрессии (прямые 1 и 2) или ограничиться одной общей линией регрессии (линия 3). Для этого используют тест Чоу, который состоит в следующем.
Вся выборка объёма n разбивается на две подвыборки объёмами n1 и n2 (n1+n2=n), и для каждой строится уравнение регрессии. Обозначим через s1 и s2 остаточные СКО для каждой из регрессий. Кроме того, строится общая регрессия для всех наблюдений (линия 3), и для неё определяется остаточная СКО, которую обозначим s3. Равенство s3=s1+s2 возможно лишь при совпадении коэффициентов регрессии для всех трёх уравнений. Если сумма s1+s2 будет значительно меньше, чем s3, то можно считать разбиение общей выборки на две подвыборки обоснованным. В этом смысле разность (s3-(s1+s2)) можно считать мерой улучшения качества модели при разбиении выборки на две части. Однако при разбиении уменьшается число степеней свободы каждой из подвыборок. Эта альтернатива между числом степеней свободы и уменьшением остаточной СКО выражается через статистику
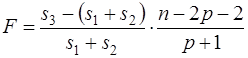 (82)
(82)
где p – число факторов. Выражение (82) равно отношению уменьшения необъясненной дисперсии к необъясненной дисперсии кусочно-линейной модели.
Если уменьшение дисперсии статистически незначимо, статистика (82) имеет распределение Фишера с (p+1, n-2p-2) степенями свободы. Если на заданном уровне значимости α 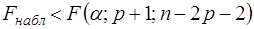 , то нет смысла разбивать уравнение регрессии на части. В противном случае разбиение на подвыборки целесообразно с точки зрения улучшения качества модели.
, то нет смысла разбивать уравнение регрессии на части. В противном случае разбиение на подвыборки целесообразно с точки зрения улучшения качества модели.
Если гипотеза о структурной стабильности выборки отклоняется, то исследуется вопрос о причинах структурных различий в подвыборках. Пусть данные в подвыборках описываются двумя уравнениями регрессии:
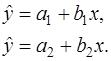
Тогда возможны следующие варианты:
1. Различие между а1 и а2 является статистически значимым, а коэффициенты b1 и b2 статистически не различаются. При этом наблюдается скачкообразное изменение зависимости при сохранении наклона линии регрессии:
 |
2. Различие между b1 и b2 статистически значимо, а различие между а1 и а2 статистически не значимо:
 |
3. Статистически значимыми являются и различия между а1 и а2, и различия между b1 и b2:
 |
Для тестирования всех этих ситуаций применяется следующая методика, предложенная Гуйарати. Она основана на включении в модель регрессии фиктивной переменной D, которая равна 1 для всех x<x* и равна 0 для всех x>x*. Далее определяются параметры следующего уравнения регрессии:
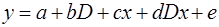 (83)
(83)
Отсюда видно, что
а1=(а+b); b1=(c+d) (D=1),
a2=a; b2=b; (D=0).
Следовательно, параметр b есть разница между a1 и а2, параметр d – разница между b1 и b2. Если в уравнении (83) b является статистически значимым, а d – нет, то имеем первый вариант структурной перестройки. Если, наоборот, статистически значимым является d, а b – незначим, имеем второй вариант структурных изменений. Наконец, третий вариант имеем в случае, если оба коэффициента b и d являются статистически значимыми.
В заключение следует отметить, что преимущество метода Гуйарати перед тестом Чоу состоит в том, что нужно построить только одно, а не три уравнения регрессии.
Дата добавления: 2016-07-27; просмотров: 6751;
Поиск по сайту
Узнать еще
- Автоматические переменные
- Внешние параметры для программы и переменные среды
- Вопрос 18. Понятие литературного жанра, его функции. Переменные и устойчивые жанровые признаки в литературном процессе. Жанровые типологии (Бахтин, Поспелов).
- Динамические переменные
- Динамические переменные
- ЕСТЕСТВЕННЫЕ ПЕРЕМЕННЫЕ ЭЛЕКТРОМАГНИТНЫЕ ПОЛЯ
- Знакопеременные ряды. Знакочередующиеся ряды. Признак сходимости.
- Константы и переменные

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
