Область переполнения
| Адрес (номер страницы) | Номер накладной | Название товара | Арти- кул | Коли-чество | Дата поставки | Ссылка на синонимы |
  500 500
| 29 | Брюки | 750 | 90 | 13.12.05 | |
| 96 | Сапоги | 220 | 120 | 13.12.05 | 
| |
 502 502
| 40 | Костюм | 300 | 35 | 14.12.05 |  500 500
|
Рис. 6. Пример хеширования с областью переполнения
Стратегия разрешения коллизий с помощью свободного замещения
В рамках данной стратегии память не разделяется на отдельные области. Если в базу данных вводится новая запись и значение хеш-функции соответствует адресу пустой страницы, запись помещается на этой странице и становится первой в цепочке синонимов. Когда возникает коллизия, новая запись размещается на первом свободном месте в памяти. С помощью ссылок создается цепочка синонимов, при этом используются те же принципы, что и в стратегии с областью переполнения.
Технологии поиска и удаления записей в обеих стратегиях также аналогичны.
При реализации стратегии разрешения коллизий с помощью свободного замещения может возникнуть ситуация, когда запись, размещаемая на первой свободной странице в памяти, занимает место, на которое позднее будет претендовать запись, значение хеш-функции которой соответствует адресу этой страницы. В такой ситуации запись, занимающая свое место «незаконно», перемещается на другую страницу, при этом изменяются ссылки в цепочке синонимов.
Основной проблемой хеширования является сложность выбора оптимальной хеш-функции. При выполнении данной работы анализируются размеры записей и страниц внешней памяти, вероятное распределение получаемых адресов. Неудачно выбранная хеш-функция может вызвать неравномерное распределение записей в памяти или формирование слишком длинных цепочек синонимов.
Весьма сложной является ситуация, когда количество запоминаемых записей больше, чем предполагалось, и необходимо увеличить место в памяти для их хранения или размеры таблицы хеширования. В этой ситуации потребуется выполнить полное повторное хеширование.
Следует иметь в виду, что хеширование позволяет организовать быстрый поиск информации только по одному полю, данные которого использовались для хеширования. Нельзя хранить записи в порядке, определяемом несколькими хеш-функциями.
Несмотря на отмеченные недостатки хеширования, данный способ организации хранения и быстрого извлечения необходимых данных широко применяется, в первую очередь в объектно-ориентированных базах данных [ 12 ].
3.6. Кластеризация
Кластеризация использует принцип близкого размещения во внешней памяти логически связанных данных. Этим обеспечиваются быстрый поиск и извлечение необходимой информации.
Физически кластеризация достигается размещением логически связанных записей на одной странице (если сделать это позволяют размеры страниц и записей) или на страницах, расположенных рядом. Если из таблицы Сведения о поставках товаров в магазинчасто извлекаются сведения для товаров с одинаковыми названиями, а на каждой странице во внешней памяти размещаются две записи, структура хранения может иметь вид (табл. 3.7):
Таблица 3.7
Сведения о поставках товаров в магазин
| Номер накладной | Название товара | Артикул | Количество | Дата поставки | Номер страницы |
| Костюм | 10.12.05 | ||||
| Костюм | 11.12.05 | ||||
| Костюм | 12.12.05 | ||||
| Костюм | 12.12.05 | ||||
| Сапоги | 10.12.05 | ||||
| Туфли | 11.12.05 | ||||
| Туфли | 12.12.05 |
В результате из множества страниц формируются блоки, называемые кластерами, в каждом из которых хранятся записи с одинаковыми названиями товаров.
Новая запись, вводимая в базу данных, должна быть размещена в конкретном кластере. Этот процесс может быть выполнен на уже имеющейся странице (в рассматриваемом примере, если товар называется Сапоги, на странице с номером 5) или при отсутствии на ней свободного места, на странице физически наиболее близкой (товар Костюм– на странице с номером 3).
Для кластеризированных таблиц можно создать неплотные индексы (см. п. 3.4) с указателями на первые записи, входящие в каждый кластер (блок).
Рассмотренный способ кластеризации реализуется для одного логического объекта (файла) базы данных. Такая кластеризация называется внутрифайловой [ 2 ]. Иногда применяется межфайловая кластеризация, когда на одной странице во внешней памяти размещаются записи из нескольких логических объектов (файлов) базы данных [ 2 ]. Например, на страницах, где содержатся сведения о поставках товаров в магазин с конкретными названиями и артикулами, может храниться информация о таких характеристиках этих товаров, как производитель, поставщик, цена, цвет изделия и т. д. из другого логического объекта. Такой принцип хранения данных может существенно ускорить выполнение запросов, включающих критерии отбора для характеристик, хранимых совместно, но он замедляет поиск информации для всех других запросов. Поэтому кластеризация является оправданной, если к базе данных наиболее часто выполняются запросы одного типа. При этом следует иметь в виду, что одновременно можно реализовать только один вариант кластеризации базы данных, так как речь идет о физическом хранении информации.
4. Распределенная обработка данных
4.1. Режимы работы с базой данных
В зависимости от характера решаемых задач, обрабатываемой информации, используемой СУБД, работа с базами данных может быть организована различными способами (рис. 7):
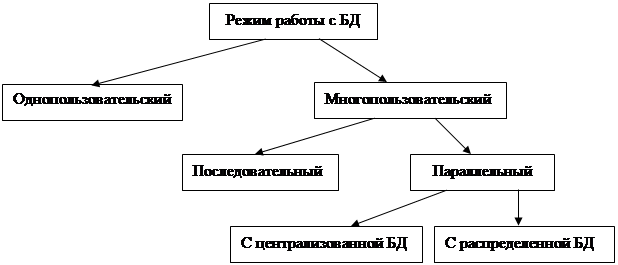 |
Рис. 7. Режимы работы с базами данных [ 4 ]
Если с базой данных, размещенной на автономном или входящем в состав локальной вычислительной сети компьютере, в течение одного или нескольких сеансов работает только один человек, такой режим называется однопользовательским (монопольным).
В рамках последовательного многопользовательского режима к базе данных имеют доступ несколько человек, которые сменяют друг друга в процессе работы.
Параллельные режимы работы с базой данных предполагают, что с одной и той же базой данных одновременно работают несколько пользователей.
Несмотря на очевидную простоту рассмотренных понятий, студенты часто неправильно их интерпретируют, полагая, что сам факт одновременного выполнения заданий с помощью СУБД MS Access во время лабораторных занятий на компьютерах, включенных в локальную вычислительную сеть, обеспечивает параллельный режим работы. При этом забывается, что каждый пользователь работает со своей локальной базой данных, сохраняемой под уникальным именем.
Для обеспечения надежной и качественной работы с базой данных в монопольном и последовательном многопользовательском режимах обычно не требуются сложные специальные методы и технологии. Необходимый результат может быть достигнут с помощью простых организационных мер: регламентации действий и ограничения полномочий отдельных пользователей, внедрения детально разработанных инструкций о характере и последовательности выполняемых действий и т. д.
Монопольный и последовательный многопользовательский режимы в основном применяются для работы с небольшими, локальными базами данных (учет поступления товаров в отдельный магазин, решение несложной научно-исследовательской задачи и т. д.). Если база данных предназначена для обеспечения деятельности даже небольших организаций, фирм, учреждений, с высокой степенью вероятности можно ожидать, что она будет эксплуатироваться в параллельном режиме.
Для понимания особенностей параллельного режима работы с базой данных предварительно рассмотрим фундаментальные понятия клиент и сервер.
4.2. Архитектура «клиент-сервер»
Термины «клиент» и «сервер» изначально применялись для архитектуры программного обеспечения, которое можно было разделить на два вычислительных процесса. Клиентский процесс запрашивает некоторые услуги у сервера, серверный процесс предоставляет эти услуги клиенту. Один сервер может обслуживать несколько клиентов.
В дальнейшем, в связи с развитием вычислительных сетей, возникла возможность распределения указанных задач между отдельными компьютерами. Поэтому в настоящее время под клиентом и сервером обычно понимают разные компьютеры, выполняющие эти задачи. По мнению К. Дж. Дейта, такое понимание терминов «клиент» и «сервер» является небрежным, но очень распространенным [ 2 ].
С позиций теории баз данных сервер – это собственно СУБД. Сервер обеспечивает хранение и обработку данных, их защиту и целостность и т.д.
Клиенты представляют собой различные приложения, выполняемые «над» СУБД. Они могут быть написаны непосредственно пользователями в процессе работы с базой данных на одном из языков программирования (С++, Pascal и т.д.) или являться встроенными приложениями, поставляемыми производителями СУБД или другими организациями (процессоры языков запросов, генераторы отчетов и приложений, графические бизнес-системы и т. д.) [ 2 ].
Исходя из рассмотренных положений, архитектуру «клиент-сервер» можно представить в следующем общем виде [ 2 ]:
 |
Пользователи
 |
Клиенты
 |
Сервер
 |
База данных
Рис. 8. Архитектура «клиент-сервер» [ 2 ]
Архитектура «клиент-сервер» имеет ряд достоинств:
1. БД может использоваться одновременно несколькими клиентами.
2. Работа с данными клиентом и сервером выполняется параллельно. В результате процесс обработки данных существенно ускоряется.
3. Компьютер сервера может иметь большие вычислительные возможности, что обеспечивает высокую производительность системы.
4. Компьютер клиента можно адаптировать к требованиям конкретного конечного пользователя.
Основываясь на архитектуре «клиент-сервер», рассмотрим особенности режимов работы с централизованной и распределенной базами данных.
Централизованная база данных
Централизованное хранение баз данных применяется уже несколько десятилетий. База данных хранится на внешних устройствах центральной ЭВМ, работающей под управлением многозадачной операционной системы. Пользователи обращаются к базе данных с удаленных терминалов, часто не имеющих собственных вычислительных ресурсов – процессора и памяти (рис. 9):
 | | ||||
 |
Пользователи
 | |||||
 |  | ||||
Клиенты
 |
Сервер
 |
База данных
Рис. 9. Централизованная база данных [ 2 ]
Достоинствами этого режима являются простота эксплуатации системы и ее относительная дешевизна. Недостатки – большая зависимость от качества работы центрального узла и повышенные требования к его производительности.
Дата добавления: 2020-10-25; просмотров: 943;
Поиск по сайту
Узнать еще
- P-область n-область
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 1 глава
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 10 глава
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 11 глава
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 12 глава
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 13 глава
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 14 глава
- Адаптивная физическая культура как учебная дисциплина и область социальной практики 15 глава

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
