Организация данных и способы доступа к ним, обеспечиваемые конкретной СУБД, называются моделью данных.
Существующие базы данных разработаны на основе иерархической, сетевой, реляционной, объектно-ориентированной моделей данных или их подмножеств.
Иерархическая модель данных
Иерархическая модель данных (ИМД) представляет собой древовидную (иерархическую) структуру. В вершинах дерева находятся совокупности свойств данных, описывающих некоторый объект. В терминологии ИМД эти совокупности называются сегментами. Сегмент, у которого нет вышележащего уровня иерархии, называется корневым.
Рассмотрим структуру иерархической базы данных торгового предприятия, имеющего филиалы в нескольких городах, в каждом из которых есть несколько магазинов, имеющих склады для хранения товаров (рис. 2).
Любой блок, изображенный на схеме, представляет собой сегмент, состоящий из нескольких полей, каждое из которых характеризует собой некоторое свойство сегмента. Например, для сегмента Филиал такими свойствами могут быть название города, где находится филиал торгового предприятия, его почтовый и юридический адреса, факс и т. д. Свойствами сегмента Склад могут быть номер склада, его площадь и т. д. Корневым является сегмент Филиал.
Совокупность конкретных значений полей сегмента называется экземпляром сегмента или записью: г. Амурск – ул. Победы, 3 – 18-67-53. Следовательно, один блок на схеме отображает множество фактических записей (экземпляров сегмента).
| |||
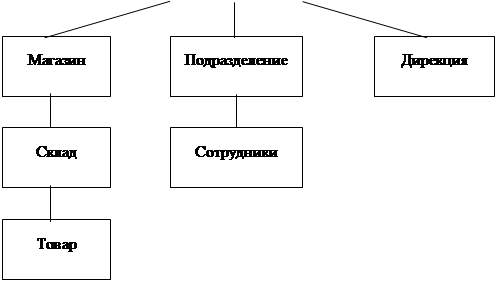 |
Рис. 2. Иерархическая база данных
Поиск нужной записи в иерархической базе данных всегда начинается от корневой записи. Например, необходимо выбрать запись с характеристиками конкретной партии товаров (количество, цвет, размер, цена и т. д.). Следует последовательно указать филиал, магазин, склад, где эти товары находятся. Для упрощения поиска, записи каждого сегмента упорядочиваются по данным некоторого поля.
Основные свойства иерархической модели данных.
1. Каждый из подчиненных сегментов связан только с одним сегментом вышележащего уровня иерархии. Связи между сегментами одного уровня не допускаются.
2. Между сегментами двух уровней могут поддерживаться только связи «один ко многим» (один филиал – много магазинов, один склад – много товаров) или «один к одному» (один филиал – один директор).
Недостатки иерархической модели данных:
1. Асимметричность запросов. В этом можно убедиться, сравнивая два запроса. С помощью первого из них выбирается запись с информацией о партии товаров, для которой известны названия филиала, магазина и склада. В рамках второго запроса по сведениям о партии товаров нужно определить название филиала, в котором она находится.
2. Сложность изменения. Например, при закрытии некоторого склада товары перераспределяются между другими складами. Эта операция потребует кардинального изменения структуры базы данных.
3. Жесткость структуры, не позволяющая учесть в базе данных отдельные реальные ситуации. Например, товары, хранящиеся на одном складе, предназначены нескольким магазинам.
4. Сложность эксплуатации. Работа с иерархическими базами данных требует значительной квалификации пользователей в области программирования. В частности, в СУБД IMS фирмы IBM для описания общей схемы базы данных и блока связи каждого пользователя с базой данных использовался язык программирования Assembler. Для выборки данных из БД – специализированный язык DL/1, для обработки полученной информации – языки PL/1 или Кобол.
Перечисленные причины привели к тому, что иерархическая модель данных в настоящее время практически не используется.
Сетевая модель данных
Стандарт сетевой модели данных впервые был определен в 1975 г. организацией CODASYL (Conference of Data System Languages).
В сетевой модели данных не накладывается никаких ограничений на количество связей, входящих в одну вершину. Следовательно, связи можно устанавливать не только между узлами соседних по подчиненности уровней, но и различных уровней (рис. 3):
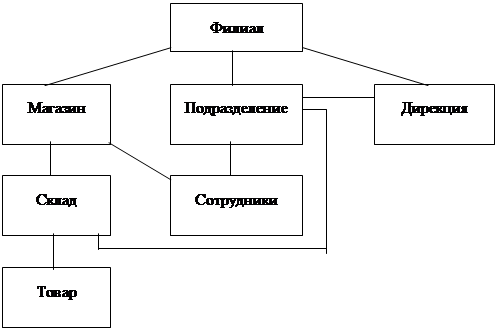 |
Рис. 3 Сетевая база данных
Связи, изображенные на рис. 3 и отсутствующие на рис. 2, могут характеризовать вполне реальные взаимоотношения в работе торгового предприятия: представители дирекции могут курировать работу конкретных подразделений, подразделения предприятия (автохозяйство, ремонтная служба) обеспечивают работу складов, сотрудники подразделений (бухгалтеры, торговые агенты) взаимодействуют с магазинами. Таких связей можно определить очень много.
В результате формируется сеть, которая позволяет отображать связи между объектами предметной области практически любой степени сложности, в частности, кольцевые структуры. В сетевой модели, если на нее не накладывается никаких ограничений, в принципе любой объект может быть точкой входа в систему, каждый из объектов может быть связан с произвольным числом других объектов, и между записями связанных объектов могут быть любые отношения. Например, для сетевой базы данных, изображенной на рис. 3, формируются связи «многие ко многим» (многие подразделения предприятия обеспечивают работу многих складов). На практике в реальных СУБД на модель накладываются определенные ограничения для преобразования связей «многие ко многим» в связи «один ко многим».
Достоинствами сетевой модели данных по сравнению с иерархической моделью являются ее гибкость, возможность образования произвольных связей, экономичность. Недостатки – высокая сложность, практически исключающая возможность ее эксплуатации пользователями, не являющимися специалистами в области информационных технологий, ослабленный контроль целостности связей между объектами базы данных [ 15 ].
По указанным причинам СУБД, построенные на основе сетевой модели (IDMS, db_VistaIII и др.), не получили широкого распространения [ 15 ].
Реляционная модель данных
Реляционная модель данных (РМД) положена в основу большинства современных СУБД. Достоинствами модели являются простота размещения данных и удобство их интерпретации.
Реляционная модель ориентирована на организацию данных в виде таблиц (отношений).
Для РМД существует довольно строгое теоретическое обоснование. Представление данных в виде отношений позволяет использовать для обработки данных формальный математический аппарат реляционной алгебры отношений и реляционного исчисления. Понятия таблицы и отношения с практической точки зрения представляют собой одно и то же, поэтому в дальнейшем будут употребляться оба эти термина.
Каждая таблица реляционной базы данных имеет имя и строку заголовков.
Рассмотрим таблицу базы данных торгового предприятия, в которой хранятся сведения о поставщиках товаров (табл. 1.1):
Таблица 1.1
Поставщики
| Код | Название | Город |
| Волна | Хабаровск | |
| Парус | Владивосток | |
| Звезда | Хабаровск | |
| Парус | Иркутск |
Таблица имеет имя Поставщики, названия столбцов таблицы Код,Название,Город представляют собой строку заголовков.
Табличная форма представления данных позволяет удобно описывать простейший вид связей между ними: информация об объекте, которая хранится в таблице (поставщики товаров), делится на множество подобъектов, каждому из которых соответствует одна строка таблицы (конкретный поставщик). При этом все подобъекты имеют одинаковую структуру или свойства.
В терминологии реляционной модели данных каждый столбец таблицы называется полем (атрибутом), каждая строка таблицы – записью (кортежем).
Данные в одном поле могут иметь значения только из некоторой совокупности допустимых значений, называемой домéном. Например, для поля Код таблицы Поставщики домéном является совокупность целых трехзначных чисел, для поля Город– названий городов. Для каждого поля таблицы должен быть задан конкретный тип данных. Для поля Код он является числовым, для полей Название и Город– текстовым. Обратите внимание, что понятие типа данных шире, чем домена: числа могут быть не только целыми трехзначными, но и дробными, отрицательными и т. д.
К таблицам РМД предъявляются следующие требования:
1. Значения данных, расположенные на пересечении любых строки и столбца, должны быть неделимыми (атомарными, элементарными). Это требование означает, что в каждой ячейке таблицы может находиться только одно значение.
2. В таблице не должно быть полей с одинаковыми названиями, порядок расположения полей является произвольным. Наличие этого требования определяется тем, что поиск информации в таблице реализуется в полях, имена которых указаны в запросе.
3. Порядок следования записей может быть произвольным.
4. В таблице не должно быть одинаковых записей.
Важным следствием отсутствия в таблице одинаковых записей является наличие в ней первичного ключа. Значение первичного ключа должно быть уникальным для каждой записи таблицы, следовательно, должно однозначно определять каждую запись таблицы.
Первичным ключом таблицы Поставщики является поле Код. Поля Название и Город не могут являться первичными ключами, так как в них имеются повторяющиеся значения (см. табл. 1.1). Первичный ключ, определенный по одному полю таблицы, называется простым.
В ситуации, когда в таблице нет поля с уникальными значениями данных, первичный ключ может быть определен по нескольким полям. Например, в таблице Поставки товаров, в которой ведется учет партий товаров, поступивших в магазин, первичным ключом является совокупность полей Артикули Дата поставки (табл. 1.2):
Таблица 1.2
Поставки товаров
| Название товара | Артикул | Количество | Дата поставки | Шифр поставщика |
| Костюм | 10.12.05 | |||
| Сапоги | 10.12.05 | |||
| Туфли | 11.12.05 | |||
| Костюм | 11.12.05 | |||
| Костюм | 12.12.05 | |||
| Костюм | 12.12.05 | |||
| Туфли | 12.12.05 |
Первичный ключ, определенный по нескольким полям, называетсясоставным. В общем случае в таблице может быть несколько вероятных ключей, из которых один выбирается как первичный.
С помощью одной таблицы обычно не удается описать сложные структуры данных из предметной области. Поэтому реляционная модель данных предполагает создание нескольких таблиц, которые при необходимости связываются между собой по ключевым полям. Такая стратегия очень удобна, так как позволяет хранить постоянно и редко используемые данные в разных таблицах.
Предположим, в таблице Дополнительные сведенияхранится подробная информация об организациях, поставляющих товары (табл. 1.3):
Таблица 1.3
Дополнительные сведения
| Поставщик | Директор | Телефон | Адрес | № договора |
| Иванов П. Л. | 64-12-83 | Мира, 4 | ||
| Сеидов О. А. | 22-17-12 | Победы, 18 | ||
| Цой О. М. | 39-18-34 | Блюхера, 1 | ||
| Лодис С. С. | 46-19-23 | Пушкина, 1 |
В таблицу Дополнительные сведениявключены всего пять полей, но их может быть гораздо больше: ИНН организации, Банк организации, Главный бухгалтер и т. д. Очевидно, что такие сведения могут быть востребованы для учета поступающих товаров значительно реже, чем хранящиеся в таблице Поставщики.
Свяжем таблицы Поставщики и Дополнительные сведения с помощью полей Код и Поставщик. Сравнивая значения данных в этих полях и выбирая сочетания записей, для которых они совпадают, можно получить ответы, например, на такие запросы: «Кто является директором организации «Парус» из Владивостока?» (Сеидов О.А.); «Какой адрес у организации «Волна»?» (Мира, 4). Приведенный пример демонстрирует связь между таблицами «один к одному» – одной записи в таблице Поставщики соответствует одна запись в таблице Дополнительные сведения.
Свяжем теперь таблицы Поставщики и Поставки товаров с помощью полей Код и Шифр поставщика. Возникает вопрос о правомерности выполненных действий. Так как значения данных в поле Шифр поставщика повторяются, это поле не может являться первичным ключом таблицы Поставки товаров.
На самом деле никакого противоречия не существует – поле Шифр поставщика является внешним ключом таблицы Поставки товаров. Внешний ключ – это поле или группа полей таблицы, которые не являются первичным ключом в данной таблице, но являются первичным ключом в другой таблице.
С помощью связывания таблиц Поставщики и Поставки товаров по ключевым полям, можно получить ответы на запросы: «Какая организация поставила костюмы 10 декабря 2005 г.?» (Волна); «Из каких городов были привезены туфли?» (Хабаровск, Иркутск).
Связывая таблицы Поставки товаров и Дополнительные сведения, можно получить ответы на запросы: «Какой номер телефона у организации, поставившей костюмы с артикулом 500?» (64-12-83); «В соответствии с каким договором поставлялись костюмы с артикулом 400?» (№ 35).
Рассмотренные примеры очень просты. При работе с реальными базами данных можно выполнять более сложные запросы, связывая одновременно несколько таблиц. При этом не исключено, что для каждой связи будут использованы разные поля таблиц и типы ключей (простые или составные). Нет необходимости поддерживать постоянные связи между таблицами – они могут быть созданы в любой момент, когда возникнет соответствующая потребность.
Для связывания таблиц, данные в связующих полях обязательно должны быть получены из одного домена. Имена связующих полей могут отличаться друг от друга (Код, Шифр поставщика, Поставщик), расположение связующих полей в таблицах может быть произвольным (см. табл. 1.1 – 1.3).
Объектно-ориентированная модель данных
Создание объектно-ориентированных СУБД считается одним из наиболее перспективных направлений в области разработки новых типов баз данных.
Объектно-ориентированные СУБД базируются на идеях, сформулированных в объектно-ориентированных языках программирования (наследования, инкапсуляции и полиморфизма). Предметная область представляется в виде множества классов объектов. Структура и поведение объектов одного класса (например, товаров базы данных торгового предприятия) являются одинаковыми.
Объект обладает следующими характеристиками [ 12 ]:
1. Имеет уникальный идентификатор, однозначно определяющий объект.
2. Принадлежит к некоторому классу, обладающему определенными поведением и свойствами.
3. Может обмениваться сообщениями с другими объектами.
4. Имеет некоторую внутреннюю структуру. Объекты, внутренняя структура которых скрыта от пользователей (известно только, какие функции может выполнять данный объект), называются инкапсулированными.
Поведение объекта задается с помощью методов его класса – операций, которые можно применять к объекту. Способность применять один и тот же метод для разных классов называется полиморфизмом [ 2 ].
В объектно-ориентированной модели возможно создание нового класса объектов на основе уже существующего класса. Этот процесс называется наследованием. Новый класс, называемый подклассом существующего класса (суперкласса), наследует все свойства и методы суперкласса [ 4 ]. Кроме того, для него могут быть определены дополнительные свойства и методы.
Объектно-ориентированная СУБД позволяет хранить объекты и обеспечивает их совместное использование различными приложениями. Для этого она должна обладать следующими компонентами [ 12 ]:
1. Языком баз данных, который позволяет декларировать классы объектов, а затем создавать, сохранять, извлекать и удалять объекты.
2. Хранилищем объектов, к которому могут получить доступ разные приложения. Для ссылок на объекты используются их идентификаторы.
Для практической реализации объектно-ориентированных баз данных применяются два подхода [ 12 ]:
1. Используется язык объектно-ориентированного программирования (например, С++), дополненный средствами, позволяющими при необходимости сохранять объекты после завершения программы, с помощью которой они были созданы.
2. Основой является реляционная система, к которой добавляются объектно-ориентированные компоненты.
Недостатки объектно-ориентированных баз данных [ 12 ]:
1) отсутствуют необходимое унифицированное теоретическое обоснование и стандартизованная терминология;
2) не существует формально сформулированной методологии проектирования баз данных;
3) отсутствуют средства создания нерегламентированных запросов;
4) нет общих правил поддержания согласованности данных.
В заключение можно отметить, что объектно-ориентированные базы данных в настоящее время очень сложны в проектировании и эксплуатации, что ограничивает их практическое применение. Поэтому, несмотря на продолжающиеся интенсивные исследования, объектно-ориентированная модель данных пока поддерживается лишь немногими СУБД (POET, Jasmine, Versant, Iris) [ 15 ].
2. Целостность баз данных
Одной из важнейших задач, решаемой СУБД, является поддержание в любой момент времени взаимной непротиворечивости, правильности и точности данных, хранящихся в БД. Этот процесс называется обеспечением целостности базы данных.
Следует различать проблемы обеспечения целостности базы данных и защиты базы данных от несанкционированного доступа (см. п. 6). Поддержание целостности базы данных может интерпретироваться как защита данных от неправильных действий пользователей или некоторых случайных внешних воздействий. В обеих ситуациях нарушения целостности базы данных имеют непреднамеренный характер.
Целостность базы данных может быть нарушена в результате сбоя оборудования; программной ошибки в СУБД, операционной системе или прикладной программе; неправильных действий пользователей. Эти ситуации могут возникать даже в хорошо проверенных и отлаженных системах, несмотря на применяемые системы контроля. Поэтому СУБД должна иметь средства обнаружения таких ситуаций и восстановления правильного состояния базы данных.
Целостность базы данных поддерживается с помощью набора специальных логических правил, накладываемых на данные, называемых ограничениями целостности. Ограничения целостности представляют собой утверждения о допустимых значениях отдельных информационных единиц и связях между ними [ 3 ]. Ограничения целостности хранятся в словаре БД.
Ограничения целостности могут определяться:
· спецификой предметной области (возраст сотрудников организации может находиться в диапазоне от 16 до 80 лет);
· непосредственно информационными характеристиками (артикул товара должен быть целым числом).
В процессе работы пользователя с базой данных СУБД проверяет, соответствуют ли выполняемые действия установленным ограничениям целостности. Действия, нарушающие целостность базы данных, отменяются, при этом обычно выводится соответствующее информационное сообщение.
Рассмотрим проблемы поддержания целостности баз данных на примере реляционной СУБД. Следует отметить, что приводимые далее рассуждения в общем виде справедливы и для других моделей данных [ 3 ].
Ограничения целостности в реляционной модели данных могут относиться к полям, записям, таблицам, связям между таблицами.
Ограничения целостности для полей
Большая часть ограничений целостности для полей обеспечивает выполнение требования, приведенного в п. 1.2 – данные в одном поле могут иметь значения только из некоторой совокупности допустимых значений, называемой домéном. Практическая реализация этого требования может осуществляться разными способами:
1. Для поля устанавливается конкретный тип данных: текстовый, числовой, дата/время, логический и т. д. Это не позволяет вводить, например, в числовое поле текст или даты, в поле с типом данных дата/время – числа.
2. Домен указывается непосредственно – перечислением входящих в него значений или с помощью указания диапазона допустимых значений.
Проиллюстрируем процесс создания рассмотренных ограничений целостности для полей на примере СУБД MS Access. Все они легко задаются при формировании структуры таблицы в режиме Конструктора.
Тип данных создаваемого поля выбирается из предложенного списка доступных типов. При необходимости с помощью свойства поля Размер поля можно уточнить область определения размещаемых в нем данных. Указывается максимальный размер данных, сохраняемых в поле: количество символов для тестовых полей; размеры поля для числовых полей: байт (целое число от 0 до 255), целое (число в диапазоне от минус 32768 до 32768), одинарное с плавающей точкой и т. д.
При непосредственном задании домена необходимые параметры можно указать в свойстве поля Условие на значение. Например, если в структуру торгового предприятия входят три магазина: «Парус», «Волна» и «Лотос», для поля Название магазина некоторой таблицы, в которое вводятся соответствующие значения, целесообразно предусмотреть следующее ограничение целостности:
Условие на значение “Парус” OR “Волна” OR “Лотос”
В результате попытка ввести в поле Название магазина другие значения будет восприниматься как ошибка.
Если известно, что цены товаров должны находиться в диапазоне от 100 до 100 000 рублей, ограничение целостности для поля Цена должно иметь вид:
Условие на значение >= 100 AND <=100000
Частным случаем определения домена можно считать автоматическое (по умолчанию) задание конкретного значения данных в некотором поле (в MS Access свойство поля Значение по умолчанию).
Некоторые нарушения целостности полей таблиц базы данных СУБД контролирует автоматически. Например, в поле, для которого определен тип данных дата/время, невозможно ввести значения 10.15.05 или 35.01.05.
В ситуациях, когда вводимое в некоторое поле значение данных не соответствует установленным для этого поля ограничениям целостности, СУБД Access выводит на экран сообщение «Введенное значение не подходит для данного поля». Пользователь может самостоятельно создать нестандартный текст этого сообщения с помощью свойства поля Сообщение об ошибке.
Для полей таблиц могут поддерживаться и другие ограничения целостности.
1. Контролируется, введены ли данные в поле. Например, в таблице со сведениями о сотрудниках предприятия для каждого сотрудника обязательно должны быть данные о его фамилии и инициалах. В MS Access это ограничение целостности создается для конкретного поля с помощью выбора значения Да свойства Обязательное поле.
2. Контролируется уникальность значений данных в поле. Если поле является простым первичным ключом таблицы, проверка уникальности значений данных в этом поле выполняется СУБД автоматически. При наличии в таблице вероятных простых ключей, можно исключить ввод в соответствующие поля повторяющихся значений данных. Для этого в MS Access для этих полей в свойстве Индексированное полеустанавливается значение Да (Совпадения не допускаются).
Все рассмотренные ограничения целостности проверяют не только правильность ввода новых данных в поля таблиц, но и контролируют процесс редактирования уже имеющихся в таблицах значений.
Перечисленные ограничения целостности называют статическими, так как они определяют условия, которые должны выполняться для каждого состояния базы данных. СУБД может поддерживать и динамические ограничения целостности, контролирующие возможность перехода от одних значений данных, хранящихся в поле, к другим. Например, если в таблице базы данных хранятся сведения о возрасте и стаже работы сотрудников предприятия, значения данных в этих полях должны только увеличиваться [ 3 ]. При попытках внести в базу данных некорректные изменения, СУБД должна выводить сообщение о допущенной ошибке.
Ограничения целостности для записей
В рамках данного вида ограничений может контролироваться согласованность значений данных в разных полях записей. Например, в каждой записи таблицы базы данных магазина хранится информация о конкретном товаре. Количество товаров, проданных магазином за отчетный период (поле Продано), не может превышать количества товаров, имеющихся в магазине на начало периода (поле Наличие товара).
Для задания этого ограничения целостности в MS Access необходимо вызвать диалоговое окно свойств таблицы и в свойстве Условие на значение ввести необходимые условия:
[Наличие товара] >= [Продано]
Ограничения целостности для таблиц
Эти ограничения целостности проверяют согласованность данных в различных записях одной таблицы.
Например, если в таблице приводятся сведения о товарах и их комплектующих, СУБД должна контролировать, чтобы некоторое изделие не входило в состав самого себя. При учете продаж товара несколькими магазинами торгового предприятия следует проверять, чтобы суммарное количество продаж не превышало общего количества товара, полученного предприятием от поставщиков.
В рамках ограничений целостности данного вида может контролироваться также отсутствие одинаковых записей в таблице (на практике это реализуется с помощью создания простых или составных ключей таблицы).
Ограничения целостности для таблиц в основном реализуются специально созданными для этого программами (процедурами) [ 3 ].
Ограничения целостности для связей между таблицами
Ограничения целостности этого типа позволяют обеспечить согласованность данных в связующих полях (первичном и внешнем ключах) нескольких таблиц.
Рассмотрим таблицы Поставщики (табл. 1.1) и Поставки товаров (табл. 1.2). Эти таблицы связаны между собой с помощью ключевых полей Коди Шифр поставщика. Таблица Поставщики является главной таблицей, таблица Поставки товаров – подчиненной. Значения данных в связующих полях получены из одного домена, представляющего в рассматриваемом примере множество положительных целых трехзначных чисел.
Нарушение целостности связи между таблицами возможно при возникновении следующих ситуаций:
1. В главной таблице удаляется запись, для которой существуют связанные записи в подчиненной таблице. Действительно, если в таблице Поставщики удалить первую запись (код поставщика равен 345), база данных будет находиться в несогласованном состоянии – неизвестно, какая фирма осуществила поставки, представленные первой, четвертой и пятой записями таблицы Поставки товаров (см. табл. 1.2).
Ввод в таблицу Поставщики дополнительной записи не приводит к нарушению целостности базы данных, так как в таблице появятся сведения еще об одном поставщике, информация о поставках товаров которым может быть добавлена в таблицу Поставки товаров после начала этих действий.
2. В главной таблице изменяются значения данных в поле (полях) первичного ключа, если существуют связанные с ними значения в поле (полях) внешнего ключа подчиненной таблицы (например, в таблице Поставщики код поставщика, равный 345, изменяется на значение 725, а такого значения в поле Шифр поставщика таблицы Поставки товаров нет).
3. В поле (полях) внешнего ключа подчиненной таблицы вводятся значения данных, отсутствующие в поле (полях) первичного ключа главной таблицы (например, в таблицу Поставки товаров нельзяввести шифр поставщика 750, которого нет в поле Код таблицы Поставщики).
В СУБД MS Access для исключения возможности возникновения перечисленных ситуаций, нарушающих согласованность базы данных, при создании каждой конкретной связи между таблицами в диалоговом окне Связи устанавливается флажок Обеспечение целостности данных. После этого любая попытка выполнить действия, нарушающие целостность связей между таблицами, будет игнорироваться (при этом выводится сообщение об ошибке).
Если возникает необходимость удаления или обновления связанных записей в таблицах БД при сохранении целостности данных, в диалоговом окне Связи требуется установить флажки Каскадное обновление связанных полей и Каскадное удаление связанных полей. При установке первого из этих флажков изменения данных в поле (полях) первичного ключа главной таблицы приводят к автоматическому изменению соответствующих значений в связанных полях подчиненных таблиц. Установка второго флажка позволяет автоматически удалить все записи в подчиненных таблицах, связанные с удаляемой записью в главной таблице.
Для многотабличной БД могут быть созданы также ограничения целостности, проверяющие отсутствие логических противоречий между данными связанных таблиц. Например, для каждой товарной группы в одной из таблиц базы данных хранятся диапазоны значений артикулов товаров. При размещении в другой таблице сведений о текущих поставках товаров эти данные используются для контроля правильности вводимой информации.
В качестве ограничения целостности может быть использован запрет на обновление данных в отдельных полях, записях или таблицах БД [ 3 ]. Очевидно, что должны быть защищены от случайных изменений, например, данные о реализованных поставках товаров, справочники о номенклатуре и характеристиках выпускаемых изделий и т.д.
Ограничения целостности могут создаваться при описании баз данных (декларативный способ) или в программах обработки данных (процедурный способ). Рекомендуется применять декларативный способ, так как создаваемые с его помощью только один раз ограничения целостности будут использоваться многократно при выполнении различных действий с данными. Кроме того, в декларативном способе используется более высокий уровень языковых средств [ 3 ].
3. Внутренняя организация СУБД
3.1. Общие положения
Данные на внешних носителях информации (например, магнитных или оптических дисках) хранятся в виде файлов. Запись данных во внешнюю память и чтение их из нее реализуются операционной системой компьютера, предоставляющей прикладным программам (в том числе и СУБД) услуги по вводу-выводу информации и управлению памятью. Обработка файлов операционной системой на логическом уровне выполняется с помощью файловой системы, на физическом уровне – системы управления файлами.
Наибольшую производительность работы СУБД обеспечивают физические устройства хранения данных прямого доступа (магнитные и оптические диски и т. д.), обеспечивающие непосредственное считывание необходимой информации, если известно ее местоположение. Оптимальным является размещение данных в файлах прямого доступа, позволяющих выбирать нужные записи базы данных без просмотра всего содержимого файла. Для ускорения поиска информации применяются различные структуры хранения данных (способы их упорядочивания). Существенное внимание специалистов к разработке структур хранения и технологий методов доступа к данным определяется необходимостью сокращения числа дисковых операций ввода-вывода данных из-за относительно большого времени доступа к внешним устройствам [ 2 ].
Данные в процессе работы считываются и записываются страницами – блоками фиксированных размеров (в зависимости от используемой системы обычно 2, 4 или 8 килобайт) [ 12 ]. Каждая страница, хранящаяся на диске, имеет свой уникальный идентификатор, указывающий на физическое место ее хранения. Этот идентификатор используется системой управления файлами для чтения страницы и ее записи после изменения размещенных на ней данных в то же место на диске, откуда страница была считана.
Файл базы данных представляет собой набор страниц. При создании файла по запросу файловой системы система управления файлами выделяет ему требуемое количество страниц. Каждой странице в полученном наборе страниц присваивается некоторый «логический» (например, порядковый) номер. Обычно система управления файлами ведет каталог, в котором содержатся сведения о наборах страниц и указателях к каждой странице в их пределах. Когда СУБД в рамках решения прикладной задачи взаимодействует с конкретным файлом, логические номера страниц используются файловой системой, не знающей, где физически на диске хранится нужная страница, для обращения к системе управления файлами, осуществляющей чтение и запись данных (рис. 4).
На одной странице могут храниться одна или несколько записей с данными. После считывания из внешней памяти в оперативную память необходимой страницы выполняется выборка и обработка нужной записи. Для этого используется идентификационный номер записи, состоящий из двух частей: номера страницы и параметра, определяющего место расположения записи на странице [ 2 ].
В очень редких случаях запись, размеры которой превышают размеры страницы, может размещаться на двух (но не более) страницах. В таких ситуациях используются страницы переполнения [ 2 ].
В различных СУБД рассмотренная общая схема может быть реализована по разным принципам. Например, в СУБД Paradox каждая таблица или другой объект базы данных представляют собой отдельный файл, в СУБД MS Access все таблицы, запросы, отчеты, схема базы данных и т.д. хранятся в одном файле с расширением .mdb.
СУБД
 |
Обращения к файлам
 |
Файловая система
 |
Обращения к логическим страницам
 |
Система управления файлами
| |
Доступ к физическим страницам
| | |||
 |
Рис. 4. Обращение СУБД к данным на диске
3.2. Линейный список
Линейный (последовательный) список – последовательность записей базы данных, сформированная по некоторым логическим принципам. Например, в таблице, содержащей информацию о поступлении товаров в магазин, сведения о каждой поставке представляют собой записи, вводимые в базу данных в хронологическом порядке и размещаемые в физическо<
Дата добавления: 2020-10-25; просмотров: 929;
Поиск по сайту
Узнать еще
- II раздел. Организация работы логопеда в группе для детей с ОНР
- II. Бесполые способы размножения.
- III. Способы формирования фонда капитального ремонта
- III. СТРУКТУРА И ОРГАНИЗАЦИЯ ДЕЯТЕЛЬНОСТИ
- STEP – стандарт для описания данных об изделии
- VI. Организация и финансирование капитального ремонта многоквартирного дома при формировании фонда капитального ремонта на специальном счете
- VII. Организация и финансирование капитального ремонта многоквартирного дома при формировании фонда капитального ремонта у регионального оператора
- А) Способы изображения пространственного строения энантиомеров

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
