И их применение в анализе и прогнозе.
Корреляционно-регрессионной моделью системы взаимосвязанных признаков является такое уравнение регрессии, которое включает основные факторы, влияющие на результативный признак, обладает высоким (не ниже 0.5) коэффициентом детерминации и коэффициентами регрессии.
Приведенное определение КРМ включает достаточно строгие условия: далеко не всякое уравнение регрессии можно считать моделью.
Теория и практика выработали ряд рекомендация для построения корреляционно-регрессионной модели:
1. Признаки-факторы должны находиться в причинной связи с результативным признаком (следствием).
2. Признаки-факторы не должны быть составными частями результативного признака или его функциями.
3. Признаки-факторы не должны дублировать друг друга, т.е. быть коллинеарными (с коэффициентом корреляции более 0.8).
4. Не следует включать в модель факторы разных уровней иерархии, т.е. фактор ближнего порядка и его субфакторы.
5. Желательно, чтобы между результативным признаком и факторами соблюдалось единство единиц совокупности, к которой они отнесены.
6. Математическая форма уравнения регрессии должна соответствовать логике связи факторов с результатом в реальном объекте. Например, такие факторы как дозы различных удобрений, уровень плодородия, число прополок и т.п. создают прибавки величины урожайности мало зависящие друг от друга; урожайность может существовать и без любого из этих факторов. Такому характеру связи соответствует аддитивное уравнение регрессии: y=a+b1x1+b2x2+....bnxn
7. Принцип простоты; предпочтительнее модели с меньшим числом факторов при том же коэффициенте детерминации или даже при существенно меньшем коэффициенте.
8. Следует обращать внимание, что полученное уравнение регрессии не полностью описывает эмпирические данные и, в общем случае, Дисперсия (общая) = Дисперсия (объяснена уравнением регрессии) + Дисперсия (остаточная).
Интерпретировать корреляционные показатели строго следует лишь в терминах вариации (различий в пространстве) отклонений от средней величины. Если же задача исследования состоит в измерении связи не между вариацией двух признаков в совокупности, а между измерениями признаков объекта во времени, то метод корреляциооно-регрессионного анализа требует значительного изменения.
Из вышеприведенного определения об интерпретации показателей корреляции следует, что нельзя трактовать корреляцию признаков как связь их уровней. Это ясно хотя бы из такого примера: Если бы все студенты, которые ходят на лекции, учились бы только на пятерки, то вариация этого признака равнялась бы нулю, а следовательно успеваемость абсолютно не могла бы влиять на посещаемость. Параметры корреляции между успеваемостью и посещаемостью всегда будут равняться нулю. Но ведь и в этом случае уровень знаний зависел бы от числа лекций - он был бы тем выше, чем больше лекций.
Итак, строго говоря, метод корреляциооно-регрессионного анализа не может объяснить роли факторных признаков в создании результативного признака. Это очень серьезное ограничение метода, о котором не следует забывать.
Следующий общий вопрос - это вопрос о “чистоте” измерения влияния каждого признака. Группировка совокупности по одному факторному признаку может отразить влияние именно данного признака на результативный признак при условии, что все другие факторы не связаны с изучаемым, а случайные отклонения и ошибки взаимопогасились в большой совокупности. Если же изучаемый фактор связан с другими факторами, влияющими на результативный признак, будет получена не “чистая” характеристика влияния только одного фактора, а сложный комплекс, состоящий как из непосредственного влияния фактора, так и из его косвенных влияний, через его связь с другими факторами и их влияние на результативный признак. Данное положение полностью относится и к парной корреляционной связи. Главным достоинством корреляционно-регрессионного метода заключается в возможности разделить влияние комплекса факторных признаков, анализировать различные стороны сложной системы взаимосвязей. Корреляционный метод при объеме совокупности около 100 единиц позволяет вести анализ системы с 8-10 факторами и разделить их влияние.
Необходимо сказать и о других задачах применения метода, имеющих не формально математических, а содержательный характер.
1. Задача выделения важнейших факторов, влияющих на результативный признак (т.е. на вариацию его значений в совокупности). Эта задача решается в основном на базе мер тесноты связи факторов с результативным признаком.
2. Задача прогнозирования возможных значений результативного признака при задаваемых значениях факторных признаков. Такая задача решается путем подстановки ожидаемых, или планируемых, или возможных значений факторных признаков в уравнение связи и вычисления ожидаемых значений результативного признака. Приходится решать и обратную задачу: вычисление необходимых значений факторных признаков для обеспечения планового или желаемого значения результативного признака. Эта задача обычно не имеет одного решения.
При решении каждой из названных задач нужно учитывать особенности и ограничения корреляционного метода. Всякий раз необходимо специально обосновывать возможность причинной интерпретации уравнения как объясняющего связь между вариацией фактора и результата. Трудно обеспечить раздельную оценку влияния каждого из факторов. В этом отношении корреляционные методы глубоко противоречивы. С одной стороны, их идеал - измерения чистого влияния каждого фактора. С другой стороны, такое измерение возможно при отсутствии связи между факторами и случайной вариации признаков. А тогда связь является функциональной, и корреляционные методы анализа излишни. В реальных системах связь всегда имеет статистический характер.
Множественная регрессия
Регрессионный анализ, по-видимому, наиболее широко используемый метод многомерного статистического анализа. Различные аспекты регрессионного анализа подробно рассмотрены в специальной литературе32. Термин ''множественная регрессия'' объясняется тем, что анализу подвергается зависимость одного признака (результирующего) от набора независимых (факторных) признаков. Разделение признаков на результирующий и факторные осуществляется исследователем на основе содержательных представлений об изучаемом явлении (процессе). Все признаки должны быть количественными (хотя допускается и использование дихотомических признаков, принимающих лишь два значения, например 0 и 1).
Для корректного использования регрессионного анализа требуется выполнение определенных условий. Факторные признаки должны быть некоррелированы (отсутствие мультиколлинеарности), они предполагаются замеренными точно и в их измерениях нет автокорреляции, т.е. значения признаков у одного объекта не должны зависеть от значений признаков у других объектов. Результирующий признак должен иметь постоянную дисперсию (Напомним определения основных показателей рассеяния (разброса) количественных признаков: дисперсии (D), среднеквадратического отклонения (σ) и коэффициента вариации (V).
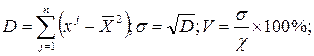
здесь п - число объектов; xj- значение признака xn для j -го объекта; 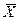 - среднее значение признака X;
- среднее значение признака X; 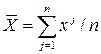 . Чем сильнее степень разброса значений признака X, тем больше значения D, σ и V , Коэффициент вариации V - сопоставимая величина для признаков разной природы, его значения выражаются в процентах. Мы не рассматриваем здесь известный вопрос о форме распределения. Отметим лишь, что для признаков, распределение которых близко к нормальному, некоррелированность влечет независимость. Кроме того, при изучении связей таких признаков можно корректно вычислить выборочные оценки, построить доверительные интервалы.), не зависящую от факторных признаков (наличие гомоскепастичности). Число объектов должно превосходить число признаков в несколько раз, чтобы параметры уравнения множественной регрессии были статистически надежными. Исследуемая совокупность должна быть в достаточной мере качественно однородной. Существенные нарушения этих условий приводят к некорректному использованию моделей множественной регрессии.
. Чем сильнее степень разброса значений признака X, тем больше значения D, σ и V , Коэффициент вариации V - сопоставимая величина для признаков разной природы, его значения выражаются в процентах. Мы не рассматриваем здесь известный вопрос о форме распределения. Отметим лишь, что для признаков, распределение которых близко к нормальному, некоррелированность влечет независимость. Кроме того, при изучении связей таких признаков можно корректно вычислить выборочные оценки, построить доверительные интервалы.), не зависящую от факторных признаков (наличие гомоскепастичности). Число объектов должно превосходить число признаков в несколько раз, чтобы параметры уравнения множественной регрессии были статистически надежными. Исследуемая совокупность должна быть в достаточной мере качественно однородной. Существенные нарушения этих условий приводят к некорректному использованию моделей множественной регрессии.
При построении регрессионных моделей прежде всего возникает вопрос о виде функциональной зависимости, характеризующей взаимосвязи между результирующим признаком и несколькими признаками-факторами. Выбор формы связи должен основываться на качественном, теоретическом и логическом анализе сущности изучаемых явлений.
Чаще всего ограничиваются линейной регрессией, т.е. зависимостью вида:
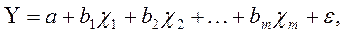
где Y - результирующий признак; x1, …, xm - факторные признаки; b1,…,bm - коэффициенты регрессии; а - свободный член уравнения; 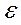 - ''ошибка" модели.
- ''ошибка" модели.
Уравнение является линейным по коэффициентам bj и в общем случае нелинейным по признакам Xj, где j=1,2,…,т (в уравнении (1) вместо Xj могут стоять Xj2 log Xj и т.д.). Вопрос о том, нужны ли преобразования исходных факторов Xj, а если нужны, то какие, подробно рассматривается в литературе33 . Наиболее распространенным на практике является логарифмическое преобразование (log X). Его используют, если наибольшее значение Х вдвое (или больше) превышает наименьшее при высокой корреляции между Х и Y (rXY>0,9). Если максимальное значение X в 20 или более раз превосходит минимальное, то это преобразование необходимо почти всегда.
В большинстве приложений регрессионной модели признаки берут в исходном виде, т.е. уравнение получается линейным и по признакам X1,...,Xm. При использовании нелинейных преобразований исходных признаков регрессионную модель нередко называют нелинейной регрессией.
Коэффициенты регрессии bj определяются таким образом, чтобы рассогласования ε, характеризующие степень приближения реальных значений результирующего признака Y с помощью линейной модели 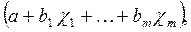 были минимальными, Это достигается на основе метода наименьших квадратов.
были минимальными, Это достигается на основе метода наименьших квадратов.
Если уравнение множественной регрессии (l) уже построено, то в вариации результирующего признака Y можно выделить часть, обусловленную изменениями факторных признаков, т.е. объясненную с помощью регрессионной модели, и остаточную, необъясненную часть. Очевидно, чем большую часть вариации признака V объясняет уравнение регрессии, тем точнее по значениям факторных признаков можно восстановить значение результирующего, и, следовательно, тем теснее связь между ними. Естественной мерой тесноты этой связи служит отношение дисперсии признака Y, объясненной регрессионной моделью, к общей дисперсии признака Y :
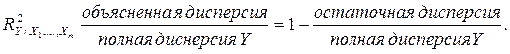
Величина R называется коэффициентом множественной корреляции и определяет степень тесноты связи результирующего признака Y со всем набором факторных признаков X1,...,Xm. В случае парной регрессии (т.е. при наличии всего одного фактора X1) 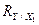 совпадает с обычным коэффициентом парной корреляцииrx,y. (Коэффициент корреляции rx,y - статистическая мера тесноты линейной связи пары признаков X и Y. Значения rx,y находятся в пределах [-1;+1]; чем ближе rx,y к
совпадает с обычным коэффициентом парной корреляцииrx,y. (Коэффициент корреляции rx,y - статистическая мера тесноты линейной связи пары признаков X и Y. Значения rx,y находятся в пределах [-1;+1]; чем ближе rx,y к 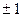 , тем теснее связь данной пары признаков, тем ближе она к функциональной. Значения rx,y, близкие к нулю, указывают на отсутствие линейной связи признаков.) Чем ближе R2 к единице, тем точнее описывает уравнение регрессии (1) эмпирические данные.
, тем теснее связь данной пары признаков, тем ближе она к функциональной. Значения rx,y, близкие к нулю, указывают на отсутствие линейной связи признаков.) Чем ближе R2 к единице, тем точнее описывает уравнение регрессии (1) эмпирические данные.
Укажем содержательный смысл коэффициентов bj, в уравнении множественной линейной регрессии (I): величина bj - показывает, насколько в среднем изменяется результирующий признак Y при увеличении соответствующего фактора Xj на единицу шкалы его измерения при фиксированных (постоянных) значениях других факторов, входящих в уравнение регрессии (т.е. оценивается "чистое" воздействие каждого фактора на результат).
Из этого определения следует, что коэффициенты регрессии bj непосредственно не сопоставимы между собой, так как зависят от единиц измерения факторов Xj. Чтобы сделать эти коэффициенты сопоставимыми, все признаки выражают в стандартизированном масштабе:
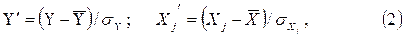
где 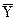 и
и 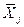 , - средние значения признаков Y и Xj, σY и σXi средние квадратичные отклонения признаков Y и Xi.
, - средние значения признаков Y и Xj, σY и σXi средние квадратичные отклонения признаков Y и Xi.
Уравнение множественной регрессии, построенное с использованием стандартизованных признаков, называется стандартизованным уравнением регрессии, а соответствующие коэффициенты регрессии - стандартизованными, илиβ (бэта) - коэффициентами. Между коэффициентами Вj и βi- существует простая связь:
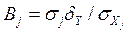
Стандартизованный коэффициент регрессии βi показывает, на сколько средних квадратичных отклонений σY изменяется Y при увеличении Xj - на одно среднеквадратическое отклонение 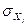 , если остальные факторы, входящие в уравнение регрессии считать неизменными.
, если остальные факторы, входящие в уравнение регрессии считать неизменными.
Сопоставление факторов можно проводить и не на основе β -коэффициентов, а по их "вкладу" в объясненную дисперсию.
В том случае, когда модель множественной регрессии строится для выборочной совокупности, необходимо проверять значимость коэффициентов регрессии Вj (с этой целью используется t -критерий Стыодента), а также коэффициента множественной корреляции R (этой цели служит F-критерий Фишера). С помощью F-критерия осуществляется проверка достоверности и соблюдения условий, которым должна удовлетворять исходная информация в уравнении множественной регрессии.
Указанные критерии математической статистики используют и при изучении взаимосвязей признаков в генеральной совокупности. В этом случае проверяют, не вызвана ли выявленная статистическая закономерность стечением случайных обстоятельств, насколько она характерна для того комплекса условий, в которых находится обследуемая совокупность. Эта совокупность - не выборка из реальной генеральной совокупности, существование которой лишь предполагается. Имеющиеся данные рассматривают как выборку из некоторой гипотетической совокупности единиц, находящихся в тех же условиях. Гипотетическая совокупность является научной абстракцией. При интерпретации вероятностной оценки результатов сплошного наблюдения (оценки значимости и т.д.) надо учитывать, что в действительности никакой генеральной совокупности нет. Устанавливается не истинность полученного результата для какой-то более обширной генеральной совокупности, а степень его закономерности, свободы от случайных воздействий.
Данный подход к оценке результатов сплошного наблюдения последовательно излагается в литературе по математической статистике. Его широко используют на практике, в частности для отсева незначимых поt-статистике факторов. Здесь необходимо отметить, что этот метод проверки существенности факторов заслуживает доверия лишь в тех случаях, когда признаки-факторы не коррелированы (или весьма слабо коррелированны), что зачастую невыполнимо на практике. В моделях множественной регрессии с взаимокоррелированными признаками возможны ситуации, когда t -критерий будет давать ложные результаты, указывая на статистическую незначимость признаков, в действительности существенно влияющих на результирующий признак.
Рассмотренный подход, на наш взгляд, более применим для оценки устойчивости параметров регрессионной модели, степени ее адекватности реальным данным. Но судить о том, насколько закономерна установленная по сплошным данным зависимость, не вызвана ли она стечением случайных обстоятельств, только на основе t - или F -критериев едва ли целесообразно. Здесь необходим качественный анализ, знание конкретных исторических условий, относящихся к изучаемому явлению.
При построении уравнений множественной регрессии основным этапом является отбор наиболее существенных факторов, воздействующих на результирующий признак. Этот этап построения модели множественной регрессии производится на основе качественного, теоретического анализа в сочетании с использованием статистических приемов. Обычно отбор факторов проходит две стадии. На первой стадии на основе содержательного анализа намечают круг факторов, теоретически существенно влияющих на результирующий признак. На второй стадии качественный анализ дополняется количественными оценками, которые позволяют отобрать статистически существенные факторы для рассматриваемых конкретных условий реализации связи. Таких оценок существует довольно много. Они основаны на использовании парных или частных коэффициентов корреляции факторных признаков с результирующим признаком Y, t-критерия вкладов факторов в объясненную дисперсию и т.д.
Отбор факторов на второй стадии исследования начинают обычно с анализа матрицы парных коэффициентов корреляции признаков, полученных на первой стадии. Выявляются факторы, тесно связанные между собой 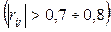 . При наличии таких связей между факторными признаками один или несколько из них нужно исключить таким образом, чтобы между оставшимися факторами не было тесных связей (при этом коэффициенты корреляции между результирующим признаком Y и факторами могут быть, конечно, высокими). Эта процедура позволяет избежать отрицательных эффектов мультиколлинеарности.
. При наличии таких связей между факторными признаками один или несколько из них нужно исключить таким образом, чтобы между оставшимися факторами не было тесных связей (при этом коэффициенты корреляции между результирующим признаком Y и факторами могут быть, конечно, высокими). Эта процедура позволяет избежать отрицательных эффектов мультиколлинеарности.
Затем можно использовать стратегию шагового отбора, реализованную в ряде алгоритмов пошаговой регрессии. Здесь получили распространение две схемы отбора. В соответствии с первой схемой признак включается в уравнение в том случае, если его включение существенно увеличивает значение множественного коэффициента корреляции, что позволяет последовательно отбирать факторы, оказывающие существенное влияние на результирующий признак даже в условиях мультиколлинеарности системы признаков, отобранных в качестве аргументов из содержательных соображений36. При этом, очевидно, первым в уравнение включается фактор, наиболее тесно коррелирующий с Y, вторым в уравнение включается тот фактор, который в паре с первым из отобранных дает максимальное значение множественного коэффициента корреляции, и т.д. Существенно, что на каждом шаге получают новое значение множественного коэффициента (большее, чем на предыдущем шаге); тем самым определяется вклад каждого отобранного фактора в объясненную дисперсию Y.
Вторая схема пошаговой регрессии основана на последовательном исключении факторов с помощью t -критерия. Она заключается в том, что после построения уравнения регрессии и оценки значимости всех коэффициентов регрессии из модели исключают тот фактор, коэффициент при котором незначим и имеет наименьший коэффициент доверия t . После этого получают новое уравнение множественной регрессии и снова производят оценку значимости всех оставшихся коэффициентов регрессии. Если среди них опять окажутся незначимые, то опять исключают фактор с наименьшим значением t -критерия. Процесс исключения факторов останавливается на том шаге, при котором все регрессионные коэффициенты значимы. При использовании этой схемы пошаговой регрессии следует иметь в виду те особенности применения t -критерия, о которых шла речь выше (в частности, негативные последствия мулътиколлинеарности).
Характеризуя в целом последствия мультиколлинеарности, отметим, что при ее наличии снижается точность оценок регрессионных коэффициентов (стандартные ошибки коэффициентов получаются слишком большими); становится невозможной оценка статистической значимости коэффициентов регрессии с помощью t -критерия, отсюда вероятно некорректное введение в анализ тех или иных переменных; резко возрастает чувствительность коэффициентов регрессии к особенностям исходных данных, так что добавление, например, небольшого числа наблюдений может привести к сильным сдвигам в значениях βi .
Отметим, что мультиколлинеарность может быть выявлена не только при анализе парных коэффициентов корреляции. Существуют более тонкие методы оценки существенности мультиколлинеарности и определения факторов, "ответственных" за нее.
При отсутствии мультиколлинеарности и выполнении остальных требований (они перечислены выше) модель множественной регрессии позволяет оценить значимость каждого из рассматриваемых факторов, определить степень существенности воздействия каждого фактора на результат (разные аспекты этой существенности проявляются в значенияхβ -коэффициентов и вкладов факторов, получаемых из пошаговой схемы), получить количественную оценку величины средних изменений результирующего признака при изменениях каждого из факторов (значения регрессионных коэффициентов Вj ). Наконец, величина коэффициента множественной корреляции R дает оценку веса учтенных факторов в объяснении вариаций результирующего признака Y (и соответственно оценку веса неучтенных факторов). Оценка неучтенных факторов представляется большим достоинством моделей множественной регрессии
Дата добавления: 2020-10-01; просмотров: 688;
Поиск по сайту
Узнать еще
- Анализ режимов цепей постоянного тока с применением закона Ома
- Аналитические процедуры, их применение в аудите.
- В детерминированном факторном анализе
- В мировой практике для получения гидрированных жиров нашел применение селективный катализатор
- В) широкое применение женского и детского труда.
- Важнейшие представители и их применение
- Векторный магнитный потенциал. Векторное уравнение Пуассона. Применение для вычисления магнитных потоков
- Вероятностный анализ работоспособности портовых портальных кранов с применением сетей уверенностей

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
