Сжатие данных в протоколах MNP
Расширяемость MNP при сохранении совместимости с существующими ре-ализациями ярко продемонстрирована в его поддержке Рекомендации ITU-T V.42bis.
В процессе установления соединения передатчик и приемник "оговаривают" использование сжатия данных в процессе. Это выполняется с помощью параметра 9 или 14 блока PDU LR (см. гл. 7). Параметр 9, который специфицирует сжатие данных MNP5 или MNP7, был расширен, чтобы обеспечить "краткую" форму спецификации V.42bis. Параметр 14 является новым параметром, применяемым для детализации особенностей V.42bis, используемого в данном канале.
Если существует возможность поддерживать MNP5 и (или) MNP7 и V.42bis, передатчик может включить как параметр 9 (сжатие MNP), так и параметр 14 (сжатие V.42bis). Ответственность за выбор типа сжатия данных, который будет использоваться, в этом случае несет приемник. Он возвращает PDU LR, который указывает выбранный тип сжатия данных. Если передатчик и приемник поддерживают несколько методов сжатия, то приемник делает свой выбор в соответствии со следующим приоритетом.
Приемник не включает информацию о поддержке V.42bis в свой PDU LR, если он не принял запрос на V.42bis в LR от передатчика. Если передатчик включил такой запрос в свой PDU LR, но не получил подтверждения, он отказывается от использования сжатия по протоколу V.42bis.
Далее рассмотрим особенности реализации сжатия в протоколах MNP.
Таблица 8.8. Приоритеты выбора метода сжатия
| Тип сжатия | Приоритет |
| V.42bis | Высокий |
| MNP7 | Средний |
| MNP5 | Низкий |
Протокол MNP5
Протокол MNP 5 реализует комбинацию адаптивного кодирования с применением кода Хаффмена и группового кодирования. При этом хорошо поддающиеся сжатию данные уменьшают свой исходный объем примерно на 50% и, следовательно, реальная скорость их передачи возрастает вдвое по сравнению с номинальной скоростью передачи данных модемом.
На первом этапе процедуры сжатия используется метод группового кодирования для удаления из потока передаваемых данных слишком длинных последовательностей повторяющихся символов. Этот метод преобразует каждую группу из трех и более (вплоть до 253) одинаковых смежных символов к виду символ и число символов. Поскольку групповое кодирование не связано с большими вычислениями, этот метод особенно хорош для реализации в реальном масштабе времени, в частности, при передаче данных по линиям связи.
Согласно данного метода система группового кодирования проверяет проходящий поток данных. Алгоритм остается пассивным до тех пор, пока в этом потоке не обнаружатся три одинаковых смежных символа. После этого алгоритм начинает счет и удаляет из потока данных до 250 одинаковых следующих друг за другом символов. Счетный байт посылается вслед за тремя исходными символами, и передача продолжается. На рис. 8.2 показан пример группового кодирования потока данных.
Способность метода группового кодирования сжимать длинные последовательности очевидна. Тем не менее, рис. 8.2 иллюстрирует также одну из слабостей данного алгоритма. Кодирование группы из трех символов, наоборот, расширяет поток данных.
На втором этапе сжатия данных протокол MNP5 использует адаптивное кодирование на основе метода Хаффмена, известное также как адаптивное частотное кодирование. Этот способ кодирования основан на предположении,
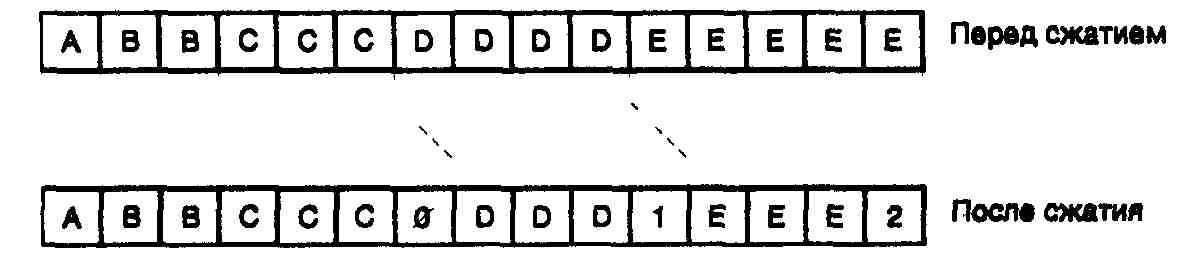
Рис. 8.2. Групповое кодирование по протоколу MNP5
что некоторые символы будут встречаться в потоке данных чаще, чем другие. Символы, которые встречаются чаще, кодируются с использованием небольшого числа битов. Реже встречающиеся символы передаются с использованием более длинных кодовых последовательностей.
Когда формат передаваемых данных относительно хорошо известен и постоянен, кодовые битовые последовательности, или лексемы, могут быть определены заранее. Однако адаптивный алгоритм может подстраиваться под поток данных путем "обучения" с последующим изменением своих лексем.
В протоколе MNP5 определяются 256 лексем для всех возможных 8-разрядных величин (октетов). Лексема состоит из 3-разрядного префикса (заголовка) и суффикса (тела, или основы), который может включать от 1 до 8 разрядов. Как передатчик, так и приемник инициализируют свои символьно-лексемные таблицы в соответствии с табл. 8.9. Первая и последняя записи
Таблица 8.9. Карта символьно-лексемного кодирования в начале процедуры уплотнения данных
| Значение октета (десятичное) | Заголовок лексемы | Тело лексемы |
| о | ||
| о | ||
| ..'. | ||
| . | ||
(строки) этой таблицы содержат наиболее и наименее часто встречающиеся октеты, соответственно.
После того как обработан каждый октет, таблица переопределяется, исходя из частоты появления каждого символа. Октетам, которые появляются чаще всего, приписываются наиболее короткие лексемы. На приемном конце лексемы преобразуются в символы. В соответствии с частотой появления тех или иных символов трансформируется таблица приемника. Тем самым осуществляется самосинхронизация, таблиц кодирования и декодирования.
Протокол MNP7
Протокол MNP7 использует более эффективный (по сравнению с MNP5) алгоритм сжатия данных и позволяет достичь коэффициента сжатия порядка 3:1. MNP7 использует улучшенную форму кодирования методом Хаффмена всочетании с марковским алгоритмом прогнозирования для создания кодовых последовательностей минимально возможной длины.
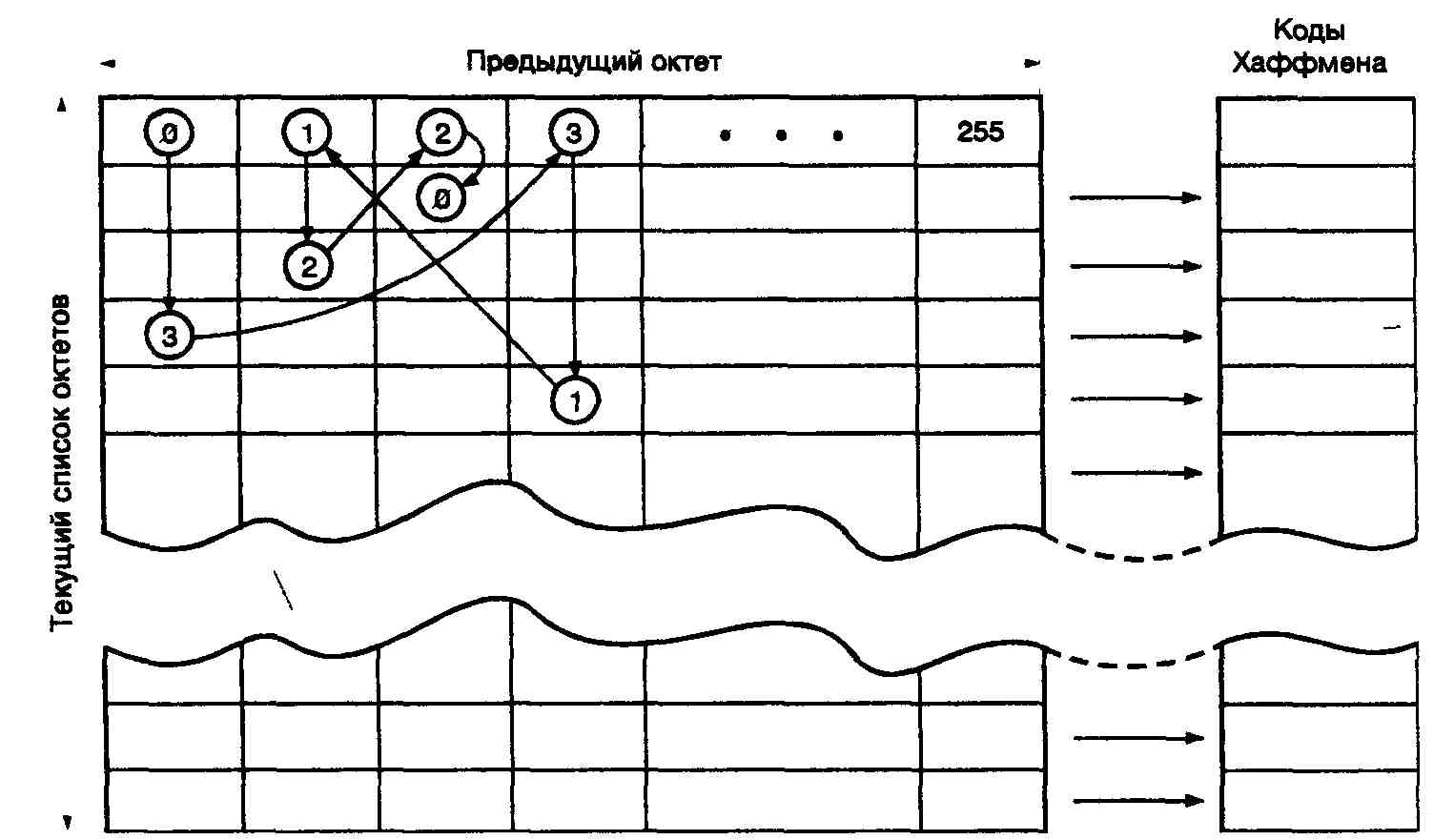
Рис. 8.3. Кодирование при помощи марковского алгоритма прогнозирования и кода Хаффмена
Марковский алгоритм может предсказывать следующий символ в последовательности, исходя из появившегося предыдущего символа. Для каждого ок-Teia формируется таблица из всех 256 возможных следующих за ним октетов, расположенных в соответствии с частотой их появления. Октет кодируется путем выбора столбца, соответствующего предыдущему октету (озаглавливающему столбец), с последующим отысканием в этом столбце значения текущего октета. Строка, в которой находится текущий октет, определяет лексему точно так же, как в описанном выше случае кодирования с использованием кода Хаффмена После того как каждый октет будет закодирован, порядок следования записей (октетов) в выбранном столбце изменяется в соответствии с новыми относительными частотами появления октетов.
На рис. 8.3 показан пример кодирования последовательности октетов 3120 в предположении, что перед этим был передан октет 0. Из рис. 8.3. видно, что в столбце, соответствующем предыдущему октету 0, отыскивается запись (строка) октета 3. После этого передается код Хаффмена для этой записи (октета 3) в таблице. Далее в столбце, соответствующем этому только что переданному октету 3, отыскивается строка с записью следующего октета — в данном случае октета 1, и передается код Хаффмена для этой строки и т.д. В этом примере отсутствует иллюстрация адаптивной части алгоритма, изменяющей порядок расположения октетов в каждом столбце.
Дата добавления: 2016-05-30; просмотров: 2412;
Поиск по сайту
Узнать еще
- JPEG-сжатие цифрового изображения
- Автоматизация обработки табличных данных (обработка списков)
- Автоматизированные банки данных
- Автоматическая генерация базы данных
- Администрирование данных
- Анализ и интерпретация данных контент-анализа
- Анализ и интерпретация данных экспериментально-психологического исследования
- Анализ исходных данных и формирование материала для эскизного проекта колористического решения интерьера

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
