Лекция 9 Элементы математической статистики
(Раздел 6)
План лекции
Генеральная совокупность и выборка.
Сущность выборочного метода.
Дискретные и интервальные вариационные ряды.
Полигон и гистограмма.
Числовые характеристики выборки.
Понятие точечной оценки
Точечная оценка для генеральной средней, генеральной дисперсии, генерального среднеквадратического отклонения.
Понятие интервальной оценки.
Надежность доверительного интервала.
Интервальная оценка математического ожидания нормального распределения при известной дисперсии.
Интервальная оценка математического ожидания нормального распределения при неизвестной дисперсии.
Интервальная оценка математического ожидания нормального распределения при неизвестной дисперсии.
Точечная оценка вероятности события.
Интервальная оценка вероятности события.
Математическая (или теоретическая) статистика опирается на методы и понятия теории вероятностей, но решает в каком-то смысле обратные задачи.
В теории вероятностей рассматриваются случайные величины с заданным распределением или случайные эксперименты, свойства которых целиком известны. Предмет теории вероятностей – свойства и взаимосвязи этих величин (распределений).
Но часто эксперимент представляет собой черный ящик, выдающий лишь некие результаты, по которым требуется сделать вывод о свойствах самого эксперимента. Наблюдатель имеет набор числовых (или их можно сделать числовыми) результатов, полученных повторением одного и того же случайного эксперимента в одинаковых условиях.
При этом возникают, например, следующие вопросы: Если мы наблюдаем одну случайную величину – как по набору ее значений в нескольких опытах сделать как можно более точный вывод о ее распределении?
Если мы наблюдаем одновременно проявление двух (или более) признаков, т.е. имеем набор значений нескольких случайных величин — что можно сказать об их зависимости? Есть она или нет? А если есть, то какова эта зависимость?
Часто бывает возможно высказать некие предположения о распределении, спрятанном в “черном ящике”, или о его свойствах. В этом случае по опытным данным требуется подтвердить или опровергнуть эти предположения (“гипотезы”). При этом надо помнить, что ответ “да” или “нет” может быть дан лишь с определенной степенью достоверности, и чем дольше мы можем продолжать эксперимент, тем точнее могут быть выводы. Наиболее благоприятной для исследования оказывается ситуация, когда можно уверенно утверждать о некоторых свойствах наблюдаемого эксперимента – например, о наличии функциональной зависимости между наблюдаемыми величинами, о нормальности распределения, о его симметричности, о наличии у распределения плотности или о его дискретном характере, и т.д.
Итак, о (математической) статистике имеет смысл вспоминать, если
· имеется случайный эксперимент, свойства которого частично или полностью неизвестны,
· мы умеем воспроизводить этот эксперимент в одних и тех же условиях некоторое (а лучше – какое угодно) число раз.
Примером такой серии экспериментов может служить социологический опрос, набор экономических показателей или, наконец, последовательность гербов и решек при тысячекратном подбрасывании монеты.
Математической статистикой называется раздел прикладной математики, изучающий методы сбора, обработки и анализа экспериментальных данных.
Предметом исследования в математической статистике является совокупность объектов, однородных относительно некоторых признаков.
Например, мальчики 10 лет г. Уссурийска; пловцы-мастера спорта России.
Совокупность из всех объектов, объединенных этими признаками, называется генеральной. Задачей исследования является изучение признаков генеральной совокупности, которые определяются влиянием некоторых случайных факторов.
Например, изучение физической подготовленности мальчиков 10 лет г. Уссурийска.
Для решения задач исследования проводится эксперимент (измерение, тестирование, анкетирование), в результате которого получают значение некоторой случайной величины (результаты тестирования, количество баллов). Если в эксперименте участвуют все объекты генеральной совокупности, то такое обследование называют сплошным.
На практике обычно применяют выборочный метод, который заключается в том, что из генеральной совокупности случайным образом извлекают n элементов. Эти элементы называются выборочной совокупностью или выборкой. Количество элементов в выборке называется ее объемом. Исследователь изучает и анализирует выборочную совокупность и на основании полученных показателей делает вывод о параметрах генеральной совокупности.
Допустим, из генеральной совокупности извлечена выборка объемом n, измерена некоторая величина Х, в результате чего получен ряд значений х1, х2, . . . хn. Этот ряд называется простым статистическим рядом.
Полученная в результате статистического наблюдения выборка из n значений (вариант) изучаемого количественного признака X образует вариационный ряд. Ранжированный вариационный ряд получают, расположив варианты xj , где 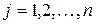 , в порядке возрастания значений, то есть
, в порядке возрастания значений, то есть 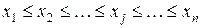 .
.
Изучаемый признак X может быть дискретным, то есть его значения отличаются на конечную, заранее известную величину (год рождения, тарифный разряд, число людей), или непрерывным, то есть его значения отличаются на сколь угодно малую величину (время, вес, объем, стоимость).
Частотой mi в случае дискретного признака X называют число одинаковых вариант xi , содержащихся в выборке. В ранжированном вариационном ряду одинаковые варианты очевидно расположены подряд:
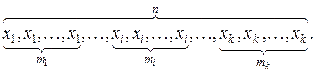
Вариационный ряд для дискретного признака X принято наглядно и компактно представлять в виде таблицы, в первой строке которой указаны k различных значений xi изучаемого признака, а во второй строке – соответствующие этим значениям частоты mi , где 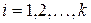 . Такую таблицу называют статистическим (выборочным) распределением.
. Такую таблицу называют статистическим (выборочным) распределением.
Переход от исходного вариационного ряда дискретного признака X к соответствующему статистическому распределению поясним на простом примере:
- вариационный ряд, полученный в результате статистического наблюдения (единицы измерения опускаем) – 7, 17, 14, 17, 10, 7, 7, 14, 7, 14;
- ранжированный вариационный ряд –
xj : 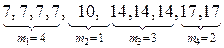 , где
, где 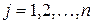 , n = 10;
, n = 10;
- соответствующее статистическое распределение ( 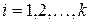 , k = 4):
, k = 4):
| xi | ||||
| mi | 2. |
Статистическое распределение для непрерывного признака X принято представлять интервальным рядом – таблицей, в первой строке которой указаны k интервалов значений изучаемого признака X вида(xi–1 – xi ), а во второй строке – соответствующие этим интервалам частоты mi , где . Обозначение
(xi–1 – xi ) – указывает не разности, а все значения признака X от xi–1 до xi , кроме правой границы интервала xi .
Для непрерывного признака X частота mi – число различных xj , попавших в соответствующий интервал: xjÎ[xi–1 ; xi ):

Переход от исходного вариационного ряда непрерывного признака X к соответствующему статистическому распределению поясним на простом примере:
- вариационный ряд, полученный в результате статистического наблюдения (единицы измерения опускаем) –3,14; 1,41; 2,87; 3,62; 2,71; 3,95;
- ранжированный вариационный ряд –
xj : 1,41; 2,71; 2,87; 3,14; 3,62; 3,95; где , n = 6;
- соответствующее статистическое распределение ( , k = 3):
| xi | 1–2 | 2–3 | 3–4 |
| mi | 3. |
Если число различных значений дискретного признака очень велико, то для удобства дальнейших вычислений и наглядности статистическое распределение такого дискретного признака также может быть представлено в виде интервального ряда.
Вместо частот mi во второй строке могут быть указаны относительные частоты 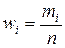 (частости). Очевидно, что сумма частот равна объему выборки (выборочной совокупности) n , а сумма относительных частот (частостей) равна единице:
(частости). Очевидно, что сумма частот равна объему выборки (выборочной совокупности) n , а сумма относительных частот (частостей) равна единице:
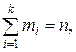
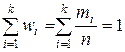 .
.
Далее показаны четыре возможных формы представления статистических распределений с соответствующими краткими названиями:
| Дискретный ряд частот | Интервальный ряд частот | ||||||||||
| xi | x1 | x2 | … | xk | xi–1–xi | x0–x1 | x1–x2 | … | xk–1–xk | ||
| mi | m1 | m2 | mk , | mi | m1 | m2 | … | mk , | |||
| Дискретный ряд частостей | Интервальный ряд частостей | ||||||||||
| xi | x1 | x2 | … | xk | xi–1–xi | x0–x1 | x1–x2 | … | xk–1–xk | ||
| wi | w1 | w2 | wk , | wi | w1 | w2 | … | wk . |
Если в статистическом распределении вместо частот (относительных частот) указать накопленные частоты (относительные накопленные частоты), то такой ряд распределения называют кумулятивным.
Накопленной частотой называется число значений признака Х, меньших заданного значения x : H(x) = m(Х< x), то есть, число вариант xj в выборке, отвечающих условию xj < x.
Переход от дискретного ряда частот к кумулятивному ряду – дискретному ряду накопленных частот задается соотношениями:
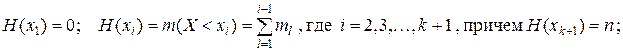
или в табличной форме:
| xi | x1 | x2 | x3 | … | xi | … | xk | xk+1 |
| H(xi) | m1 | m1+m2 | … | H(xi–1) + mi–1 | … | H(xk–1)+ mk–1 | H(xk)+ mk= n. |
Переход от интервального ряда частот к кумулятивному ряду – интервальному ряду накопленных частот задается соотношениями:
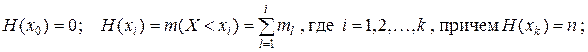
или в табличной форме:
| xi–1–xi | –¥–x0 | x0–x1 | x1–x2 | … | xi–1–xi | … | xk–1–xk |
| H(xi) | m1 | m1+m2 | … | H(xi–1)+ mi | … | H(xk–1)+ mk= n. |
Накопленной относительной частотой (накопленной частостью) называется отношение числа значений признака Х, меньших заданного значения x , к объему выборки n : 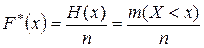 , то есть, доля вариант xj в выборке, отвечающих условию xj < x.
, то есть, доля вариант xj в выборке, отвечающих условию xj < x.
По аналогии с теоретической функцией распределения генеральной совокупности 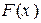 , которая определяет вероятность события Х <
, которая определяет вероятность события Х < 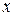 : = P(Х < ), вводят понятие эмпирической функции распределения
: = P(Х < ), вводят понятие эмпирической функции распределения 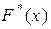 , которая определяет относительную частоту этого же события Х < , то есть =
, которая определяет относительную частоту этого же события Х < , то есть = 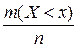 . Таким образом, эмпирическая функция распределения задается рядом накопленных относительных частот.
. Таким образом, эмпирическая функция распределения задается рядом накопленных относительных частот.
Из теоремы Бернулли следует, что стремится по вероятности к F(x):
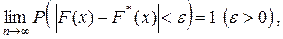
поэтому эмпирическую функцию распределения можно использовать для оценки теоретической функции распределения генеральной совокупности.
Дискретный ряд накопленных относительных частот может быть получен двумя равноправными способами:
1) переход от дискретного ряда частостей к кумулятивному ряду – дискретному ряду накопленных частостей задается соотношениями:
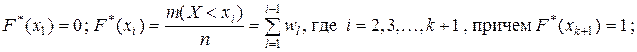
или в табличной форме:
| xi | x1 | x2 | x3 | … | xi | … | xk | xk+1 |
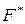 (xi) (xi)
| w1 | w1+w2 | … | (xi–1) + wi–1
| … | (xk–1)+ wk–1
| (xk)+ wk= 1;
|
2) переход от дискретного ряда накопленных частот к дискретному ряду накопленных частостей задается соотношением:
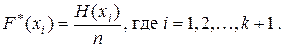
Интервальный ряд накопленных относительных частот может быть получен двумя равноправными способами:
1) переход от интервального ряда частостей к кумулятивному ряду – интервальному ряду накопленных частостей задается соотношениями:
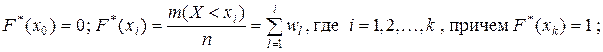
или в табличной форме:
| xi–1–xi | –¥–x0 | x0–x1 | x1–x2 | … | xi–1–xi | … | xk–1–xk |
| (xi)
| w1 | w1+w2 | … | (xi–1)+ wi
| … | (xk–1)+ wk= 1;
|
2) переход от интервального ряда накопленных частот к интервальному ряду накопленных частостей задается соотношением:
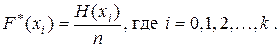
Для наглядности принято использовать следующие формы графического представления статистических распределений:
· дискретный ряд изображают в виде полигона. Полигон частот – ломаная линия, отрезки которой соединяют точки с координатами ( i , 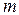 i); аналогично, полигон относительных частот – ломаная, отрезки которой соединяют точки с координатами (
i); аналогично, полигон относительных частот – ломаная, отрезки которой соединяют точки с координатами ( 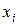 , wi );
, wi );
· интервальный ряд изображают в виде гистограммы. Гистограмма частот есть ступенчатая фигура, состоящая из прямоугольников, основания которых – интервалы длиной 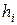 , а высоты – плотности частот
, а высоты – плотности частот 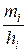 . В случае гистограммы относительных частот высоты прямоугольников – плотности относительных частот
. В случае гистограммы относительных частот высоты прямоугольников – плотности относительных частот 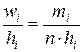 . Здесь в общем случае
. Здесь в общем случае 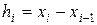 , однако на практике чаще всего полагают величину h одинаковой для всех интервалов:
, однако на практике чаще всего полагают величину h одинаковой для всех интервалов: 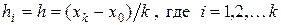 . Очевидно для ранжированного вариационного ряда
. Очевидно для ранжированного вариационного ряда 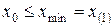 ;
; 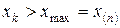 . В скобках указаны индексы j исходного ранжированного вариационного ряда.
. В скобках указаны индексы j исходного ранжированного вариационного ряда.
Площадь гистограммы есть сумма площадей ее прямоугольников:
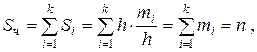
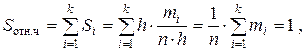
таким образом, площадь гистограммы частот 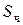 равна объему выборки, а площадь гистограммы относительных частот
равна объему выборки, а площадь гистограммы относительных частот 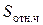 равна единице.
равна единице.
В теории вероятностей гистограмме относительных частот соответствует график плотности распределения вероятностей 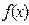 . Поэтому гистограмму можно использовать для подбора закона распределения генеральной совокупности;
. Поэтому гистограмму можно использовать для подбора закона распределения генеральной совокупности;
· кумулятивные ряды графически изображают в виде кумуляты. Для ее построения на оси абсцисс откладывают варианты признака или интервалы, а на оси ординат – накопленные частоты Н( ) или относительные накопленные частоты , а затем точки с координатами ( i ; H( i )) или ( i ; 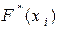 ) соединяют отрезками прямой. В теории вероятностей кумуляте соответствует график интегральной функции распределения .
) соединяют отрезками прямой. В теории вероятностей кумуляте соответствует график интегральной функции распределения .
Замечание 1. Если в статистическом исследовании исходным является статистическое распределение в виде интервального ряда (сгруппированные данные), а исходный вариационный ряд недоступен, то точное расположение отдельных вариант, попавших в каждый из интервалов неизвестно. Только выбирая в качестве аргумента эмпирической функции распределения правую границу интервала (xi–1–xi), мы уверены, что все варианты, попавшие в этот интервал, будут учтены (просуммированы) в значении накопленной частоты (накопленной относительной частоты), соответствующей этому интервалу.
Поэтому в случае интервального ряда значения и H(x) точно определены лишь для правой границы интервала: x = xi . В остальных точках интервала xi–1 < x < xi значения и H(x) можно задать лишь приближенно. Примером может служить кумулята, отрезки прямых которой представляют собой выраженную в графической форме линейную интерполяцию значений и H(x) на интервале xi–1 < x < xi .
Замечание 2. В случае дискретного ряда использовать кумуляту для изображения и H(x) можно лишь условно, для наглядности. Более корректным является изображение эмпирической функции распределения (а также H(x)) по аналогии с теоретической функцией распределения 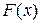 дискретной случайной величины (см. рис. 2) ступенчатым графиком – отрезками прямых, параллельных оси абсцисс; длины отрезков – hi = xi – xi–1 , расстояния от отрезков до оси абсцисс –
дискретной случайной величины (см. рис. 2) ступенчатым графиком – отрезками прямых, параллельных оси абсцисс; длины отрезков – hi = xi – xi–1 , расстояния от отрезков до оси абсцисс – 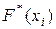 (или H(xi)).
(или H(xi)).
Пример 1. Имеется распределение 80 предприятий по числу работающих на них (чел.):
|
| |||||||
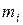
| 5 . |
Решение. Признак Х – число работающих (чел.) на предприятии. В данной задаче признак Х является дискретным. Поскольку различных значений признака сравнительно немного – k = 7, применять интервальный ряд для представления статистического распределения нецелесообразно (в прикладной статистике в подобных задачах часто используют именно интервальный ряд). Ряд распределения – дискретный. Построим полигон распределения частот
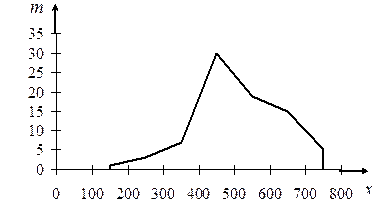
Пример 2. Дано распределение 100 рабочих по затратам времени на обработку одной детали (мин):
| xi–1–xi | 22–24 | 24–26 | 26–28 | 28–30 | 30–32 | 32–34 |
|
| 2 . |
Решение. Признак Х – затраты времени на обработку одной детали (мин). Признак Х – непрерывный, ряд распределения – интервальный. Построим гистограмму частот, предварительно определив 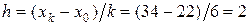 (k = 6) и плотность частоты
(k = 6) и плотность частоты 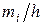 :
:
| xi–1–xi | 22–24 | 24–26 | 26–28 | 28–30 | 30–32 | 32–34 |
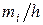
| 1 . |
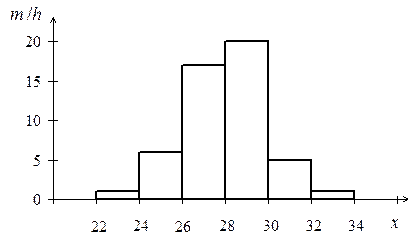
Пример 3. В распределении, данном в примере 1, найти накопленные частоты H( i ) и построить кумуляту.
Решение. Используем: H(x1) = 0, H(xi) = H(xi–1) + mi–1 (i=2,3,¼, k+1, k = 7).
| i | ||||||||
| xi | ||||||||
| mi | ||||||||
| H( i )
| 0+1=1 | 1+3=4 | 4+7=11 | 11+30=41 | 41+19=60 | 60+15=75 | 75+5=80. |
На рис. 3 показана кумулята распределения предприятий по числу работающих (чел.).
Пример 4. В распределении, данном в примере 2, составить эмпирическую функцию распределения и построить кумуляту относительных частот.
Решение. Используем: H(x0) = 0, H(xi) = H(xi–1) + mi (i=1,2,¼, k , k = 6). 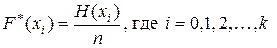 ;
; 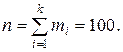 Проверка:
Проверка: 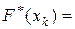 1.
1.
| i | ||||||||||||||||
| xi–1–xi | –¥–22 | 22–24 | 24–26 | 26–28 | 28–30 | 30–32 | 32–34 | |||||||||
| mi | ||||||||||||||||
| H( i )
| 0+2=2 | 2+12=14 | 14+34=48 | 48+40=88 | 88+10=98 | 98+2=100 | ||||||||||
|
| 0,02 | 0,14 | 0,48 | 0,88 | 0,98 | 1. | ||||||||||
Построим кумуляту распределения

Для описания основных свойств статистических распределений чаще всего используют выборочные характеристики следующих двух видов:
1) средние;
| Выборочная средняя: | а) характеризует типичное для выборки значение признака X; б) приближенно характеризует (оценивает) типичное для генеральной совокупности значение признака X (см. п. 3.2); | ||
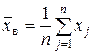
| – средняя арифметическая; применяется к вариационному ряду (данные наблюдения не сгруппированы); | ||
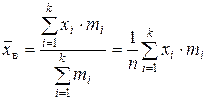 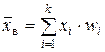
| – взвешенная средняя арифметическая (частоты mi , и частости wi называют весами); используется, если данные сгруппированы; непосредственно применима только к статистическому распределению дискретного признака (дискретному ряду). | ||
| Структурные (порядковые) средние. | Если 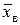 = хмo = хме , то распределение симметричное. При нарушении симметрии равенство нарушается (хотя бы одно). = хмo = хме , то распределение симметричное. При нарушении симметрии равенство нарушается (хотя бы одно).
| ||
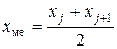 , если n = 2j – четное;
хме= хj+1 , если n = 2j+1 – нечетное. , если n = 2j – четное;
хме= хj+1 , если n = 2j+1 – нечетное.
| Медиана – это серединное значение признака X; по определению: 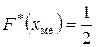 . .
| ||
| хмo = xi , если mi = mmax (справедливо только для дискретного ряда). | Мода – наиболее часто встречающееся значение признака X. | ||
2) характеристики вариации (рассеяния).
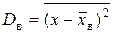
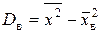
| – выборочная дисперсия есть выборочная средняя арифметическая квадратов отклонений значений признака X от выборочной средней (равна “среднему квадрату без квадрата средней”):
| |||
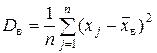
| – выборочная дисперсия; применяется к вариационному ряду (данные наблюдения не сгруппированы); | |||
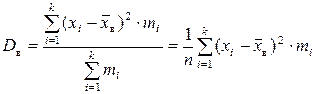
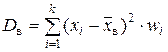
| – выборочнаявзвешенная дисперсия; используется, если данные сгруппированы; непосредственно применима только к статистическому распределению дискретного признака (дискретному ряду); | |||
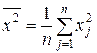
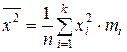
| – средний квадрат есть выборочная средняя арифметическая квадратов значений признака X (для вариационного ряда и для дискретного распределения соответственно). | |||
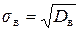
| – выборочное среднее квадратическое отклонение есть арифметическое значение корня квадратного из дисперсии; оно показывает, на сколько в среднем отклоняются значения xj признака X от выборочной средней .
| |||
| R = хmax– хmin | – размах вариации. | |||
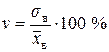
| – коэффициент вариации; применяют для сравнения вариации признаков сильно отличающихся по величине, или имеющих разные единицы измерения (разные наименования). | |||
Замечание. Если исходный вариационный ряд недоступен, приведенные выше формулы вычисления выборочных характеристик, применимые только к дискретному ряду, могут быть использованы для приближенного вычисления выборочных характеристик непрерывного признака, представленного интервальным рядом. Для этого предварительно каждый интервал xi–1–xi заменяется его серединой 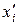 = (xi–1+ xi) / 2, то есть производится замена интервального ряда дискретным, соответствующим ему приближенно.
= (xi–1+ xi) / 2, то есть производится замена интервального ряда дискретным, соответствующим ему приближенно.
Пример 5.Найти числовые характеристики распределения предприятий по числу работающих (пример 1).
Решение. Признак Х – число работающих (чел.) на предприятии. Для расчета характеристик данного распределения удобнее использовать таблицу:
| Число работающих на предприятии, (хi ,чел.) | Число предприятий (mi) | хi mi | Н(хi) | (хi – 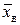 )2 mi )2 mi
| хi2mi |
| Итого | - | 22040000 . |
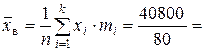 510 (чел.) – среднее число работающих на предприятии.
510 (чел.) – среднее число работающих на предприятии.
Легко убедиться, что в случае дискретного признака Х в ранжированном вариационном ряду xj = xi при Н(хi) + 1 £ j £ Н(хi+1). Для рассматриваемого примера: xj = 450 при 12£ j £ 41.
Объем выборки n = 80 – число четное. Пусть n = 2j , тогда j = 40. Поэтому:
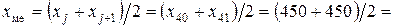 450 (чел.).
450 (чел.).
Частота достигает максимума: mi = mmax = 30 при xi = 450, поэтому:
хмо = 450 (чел.).
Очевидно хмo= хме¹ – распределение асимметричное (см. рис. 1).
R = хmax – хmin= 750 – 150 = 600 (чел.).
Дисперсию рассчитываем двумя способами.
1) 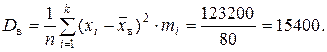
2) 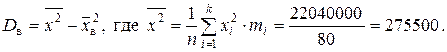
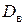 = 275500 – (510)2 = 15400.
= 275500 – (510)2 = 15400.
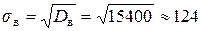 (численность работающих на каждом предприятии отклоняется от средней численности в среднем на 124 чел.)
(численность работающих на каждом предприятии отклоняется от средней численности в среднем на 124 чел.)
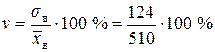 » 24,3 %.
» 24,3 %.
На практике считают, что если 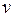 < 33 % , то совокупность однородная. В данном случае исследуемая совокупность однородная.
< 33 % , то совокупность однородная. В данном случае исследуемая совокупность однородная.
Пример 6. Найти числовые характеристики распределения затрат времени на обработку одной детали (пример 2).
Решение. Признак Х – затраты времени на обработку одной детали (мин) – непрерывный. Распределение задано интервальным рядом. Характеристики такого ряда находят по тем же формулам, что и для дискретного ряда, предварительно заменив интервальный ряд дискретным. Для этого каждый интервал xi–1–xi заменяется его серединой . Расчеты представим в таблице:
| Затраты времени на обработку 1 детали (Х, мин): xi–1–xi | Число рабочих (mi) |
| mi
| Н( )
| 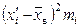
| ( )2 mi
|
| 22–24 24–26 26–28 28–30 30–32 32–34 | ||||||
| Итого | - | - | 78772 . |
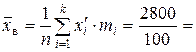 28 (мин) – среднее время на обработку одной детали.
28 (мин) – среднее время на обработку одной детали.
Легко убедиться, что в случае дискретного признака Х в ранжированном вариационном ряду xj = при Н( ) + 1 £ j £ Н( 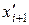 ). Для рассматриваемого примера: xj = 29 при 49£ j £ 88.
). Для рассматриваемого примера: xj = 29 при 49£ j £ 88.
Объем выборки n = 100 – число четное. Пусть n = 2j , тогда j = 50. Поэтому:
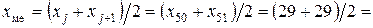 29 (мин).
29 (мин).
Частота достигает максимума: mi = mmax = 40 при xi = 29, поэтому:
хмо = 29 (мин).
Очевидно хмo = хме ¹ – распределение асимметричное (см. рис. 2).
R = хmax – хmin = 34 – 22 = 12 (мин).
Дисперсию рассчитываем двумя способами.
1) 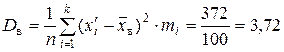 ;
;
2) 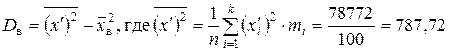 ;
;
= 787,72 – (28)2 = 3,72.
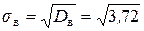 » 1,93 (мин), то есть затраты времени на обработку одной детали каждым рабочим отклоняются от средних затрат времени в среднем на 1,93 мин.
» 1,93 (мин), то есть затраты времени на обработку одной детали каждым рабочим отклоняются от средних затрат времени в среднем на 1,93 мин.
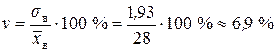 – совокупность однородная.
– совокупность однородная.
Дата добавления: 2016-06-22; просмотров: 4650;
Поиск по сайту
Узнать еще
- D-элементы, их применение в медицине и фармации.
- III. 7 ЭЛЕМЕНТЫ СПЕЦИАЛЬНОЙ ТЕОРИИ ОТНОСИТЕЛЬНОСТИ
- Автомобильные дороги: определение группы сооружений, основные конструктивные элементы
- Аккамуляторы и топливные элементы
- Актеры и элементы Use Case
- Активные элементы из неодимового стекла
- Активные элементы схемы замещения
- Активные элементы схемы замещения

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
