Кодирование длин серий (Элиас)
Входной поток для кодирования рассматривается как последовательность из нулей и единиц. Идея кодирования заключается в том, чтобы кодировать последовательности одинаковых элементов (например, нулей) как целые числа, указывающие количество элементов в этой последовательности. Последовательность одинаковых элементов называется серией, количество элементов в ней – длиной серии. Например, входную последовательность (общая длина 31бит) можно разбить на серии, а затем закодировать их длины.
000000 1 00000 1 0000000 1 1 00000000 1
Используем, например, γ-код Элиаса. Т.к. в коде нет кодового слова для нуля, то будем кодировать длину серии +1, т.е. последовательность 7 6 8 1 9
7 6 8 1 9 Þ 00111 00110 0001000 1 0001001
Длина полученно й кодовой последовательности равна 25 бит. Метод актуален для кодирования данных, в которых есть длинные последовательности одинаковых бит. В нашем примере, если P(0) >> P(1).
16.3 Алфавитное кодирование
Кодирование F может сопоставлять код всему сообщению из множества S как единому целому или строить код сообщения из кодов его частей. Элементарной частью сообщения является одна буква алфавита А={a1,a2,…,an}.
Пример 1 А={a1,a2,a3} , B={0,1} a1 ®1001, a2 ®0, a3®010
сообщение a2a1a2a3 ® 010010010
Пример 2 Азбука Морзе. Входной алфавит – английский. Наиболее часто встречающиеся буквы кодируются более короткими словами:
А ® 01, В ® 1000, С ® 1010, D ® 100, E ® 0, …
Побуквенное кодирование задается таблицей кодовых слов:σ = < α1® β1, … , αn ® βn>, αiÎA, βi ÎB*.Множество кодовых слов V={βi} называется множеством элементарных кодов. Побуквенное кодирование пригодно для любого множества сообщений S: F: A* ®B*, αi1 …αik=α ÎA*, F(α)=βi1…βik.
Количество букв в слове α=α1…αk называется длиной слова |α| = k. Пустое слово обозначим Λ. Если α=α1α2, то α1 – начало (префикс) слова α, α2 – окончание (постфикс) слова α.
Побуквенный код называется разделимым (или однозначно декодируемым), если любое сообщение из символов алфавита источника, закодированное этим кодом, может быть однозначно декодировано, т.е. если βi1 …βik = βj1 …βjt , то k=t и при любых s=1,…,k is=js , т.е. любое кодовое слово единственным образом разлагается на элементарные коды. Например, код из первого примера не является разделимым, поскольку кодовое слово 010010 может быть декодируемо двумя способами a3a3 или a2a1a2.
Побуквенный код называется префиксным, если в его множестве кодовых слов ни одно слово не является началом другого, т.е. элементарный код одной буквы не является префиксом элементарного кода другой буквы. Например, код из первого примера не является префиксным, поскольку элементарный код буквы a2 является префиксом элементарного кода буквы a3.
Утверждение. Префиксный код является разделимым.
Доказательство (от противного). Пусть префиксный код не является разделимым. Тогда существует такая кодовая последовательность β, что она представлена различными способами из элементарных кодов: β=βi1, …,βik = βj1, …,βjt (побитовое представление одинаковое) и существует L такое, что при любом S<L следует (βis= βjs) и (βit≠ βjt), т.е. начало каждого из этих представлений имеет одинаковую последовательность элементарных кодов. Уберем эту часть. Тогда βiL…βik = βjL, …,βjt, т.е. последовательности элементарных кодов разные и существует β/, что βiL=βjLβ/ или βjL=βiLβ/ , т.е. βiL – начало βjL, или наоборот. Получили противоречие с префиксностью кода.
Заметим, что разделимый код может быть не префиксным.
Пример. Разделимый, но не префиксный код: A={a,b}, B={0,1}, φ = {a®0, b®01}
Приведем основные теоремы побуквенного кодирования.
Теорема (Крафт). Для того, чтобы существовал побуквенный двоичный префиксный код с длинами кодовых слов L1,…,Ln необходимо и достаточно, чтобы
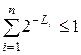 .
.
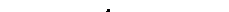 Доказательство. Докажем необходимость. Пусть существует префиксный код с длинами L1,…,Ln. Рассмотрим полное двоичное дерево. Каждая вершина закодирована последовательностью нулей и единиц (как показано на рисунке).
Доказательство. Докажем необходимость. Пусть существует префиксный код с длинами L1,…,Ln. Рассмотрим полное двоичное дерево. Каждая вершина закодирована последовательностью нулей и единиц (как показано на рисунке).
Рисунок 65 Полное двоичное дерево с помеченными вершинами
В этом дереве выделим вершины, соответствующие кодовым словам. Тогда любые два поддерева, соответствующие кодовым вершинам дерева, не пересекаются, т.к. код префиксный. У i-того поддерева на r-том уровне – 2r-Li вершин. Всего вершин в поддереве 2r. Тогда 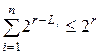 ,
, 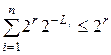 , .
, .
Докажем достаточность утверждения. Пусть существует набор длин кодовых слов такой, что . Рассмотрим полное двоичное дерево с помеченными вершинами. Пусть длины кодовых слов упорядочены по возрастанию L1≤ L2≤ … ≤ Ln. Выберем в двоичном дереве вершину V1 на L1 уровне. Уберем поддерево с корнем в вершине V1. В оставшемся дереве возьмем вершину V2 на уровне L2 и удалим поддерево с корнем в этой вершине и т.д. Последовательности, соответствующие вершинам V1, V2,…, Vn образуют префиксный код.
Пример. Построить префиксный код с длинами L1=1, L2=2, L3=2 для алфавита A={a1,a2,a3}. Проверим неравенство Крафта для набора длин 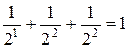 . Неравенство выполняется и, следовательно, префиксный код с таким набором длин кодовых слов существует. Рассмотрим полное двоичное дерево с 23 помеченными вершинами и выберем вершины дерева, как описано выше. Тогда элементарные коды могут быть такими a1 ®0, a2®10, a3 ®11.
. Неравенство выполняется и, следовательно, префиксный код с таким набором длин кодовых слов существует. Рассмотрим полное двоичное дерево с 23 помеченными вершинами и выберем вершины дерева, как описано выше. Тогда элементарные коды могут быть такими a1 ®0, a2®10, a3 ®11.

Рисунок 66 Построение префиксного кода с заданными длинами
Процесс декодирования выглядит следующим образом. Просматриваем полученное сообщение, двигаясь по дереву. Если попадем в кодовую вершину, то выдаем соответствующую букву и возвращаемся в корень дерева и т.д.
Теорема (МакМиллан). Для того, чтобы существовал побуквенный двоичный разделимый код с длинами кодовых слов L1,…,Ln , необходимо и достаточно, чтобы .
Доказательство. Покажем достаточность. По теореме Крафта существует префиксный код с длинами L1,…,Ln, и он является разделимым.
Докажем необходимость утверждения. Рассмотрим тождество
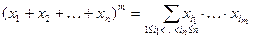
Положим 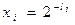 . Тогда тождество можно переписать следующим образом
. Тогда тождество можно переписать следующим образом
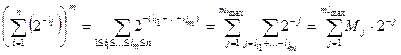 ,
,
где 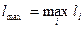 ,
, 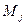 – число всевозможных представлений числа j в виде суммы
– число всевозможных представлений числа j в виде суммы 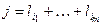 . Сопоставим каждому представлению числа j в виде суммы последовательность нулей и единиц длины j по следующему правилу
. Сопоставим каждому представлению числа j в виде суммы последовательность нулей и единиц длины j по следующему правилу
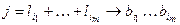 ,
,
где bs элементарный код длины s. Тогда различным представлениям числа j будут соответствовать различные кодовые слова, поскольку код является разделимым. Таким образом, 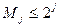 и
и 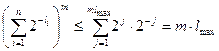 . Используя предельный переход получим
. Используя предельный переход получим 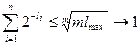 при
при 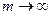 .
.
Пример. Азбука Морзе – это схема алфавитного кодирования
A®01, B®1000, C®1010, D®100, E®0, F®0010, G®110, H®0000, I®00, J®0111, K®101, L®0100, M®11, N®10, O®111, P®0110, Q®1101, R®010, S®000, T®1, U®001, V®0001, W®011, X®1001, Y®1011, Z®1100.
Неравенство МакМиллана для азбуки Морзе не выполнено, поскольку
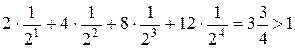
Следовательно, этот код не является разделимым. На самом деле в азбуке Морзе имеются дополнительные элементы – паузы между буквами (и словами), которые позволяют декодировать сообщение. Эти дополнительные элементы определены неформально, поэтому прием и передача сообщений (особенно с высокой скоростью) является некоторым искусством, а не простой технической процедурой.
16.4 Оптимальное алфавитное кодирование
Побуквенное кодирование пригодно для любых сообщений. Однако на практике часто доступна дополнительная информация о вероятностях символов исходного алфавита. С использованием этой информации решается задача оптимального побуквенного кодирования.
Пусть имеется дискретный вероятностный источник, порождающий символы алфавита А={a1,…,an} с вероятностями pi = p(ai), 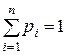 . Основной характеристикой источникаявляется его энтропия, которая представляет собой среднее значение количества информации в сообщении источника и определяется выражением (для двоичного случая)
. Основной характеристикой источникаявляется его энтропия, которая представляет собой среднее значение количества информации в сообщении источника и определяется выражением (для двоичного случая) 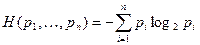 . Энтропия характеризует меру неопределенности выбора для данного источника. Например, если А={a1,a2}, p1=0, p2 =1, т.е. источник может породить только символ a2, то неопределенности нет, энтропия H(p1, p2)=0. Максимальная энтропия будет, если все символы равновероятны, например, А={a1,a2}, p1=1/2, p2 =1/2, тогда неопределенность максимальная, т.е. H(p1, p2)=1.
. Энтропия характеризует меру неопределенности выбора для данного источника. Например, если А={a1,a2}, p1=0, p2 =1, т.е. источник может породить только символ a2, то неопределенности нет, энтропия H(p1, p2)=0. Максимальная энтропия будет, если все символы равновероятны, например, А={a1,a2}, p1=1/2, p2 =1/2, тогда неопределенность максимальная, т.е. H(p1, p2)=1.
Для практических применений важно, чтобы коды сообщений имели по возможности наименьшую длину. Основной характеристикой неравномерного кода является количество символов, затрачиваемых на кодирование одного сообщения. Пусть имеется разделимый побуквенный код для источника, порождающего символы алфавита А={a1,…,an} с вероятностями pi = p(ai), , состоящий из n кодовых слов с длинами L1,…,Ln в алфавите {0,1}. Средней длиной кодового слова называется величина 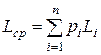 или среднее число кодовых букв на одну букву источника.
или среднее число кодовых букв на одну букву источника.
Пример. Пусть для имеются два источника с одним и тем же алфавитом А={a1,a2,a3} и разными распределениями P1={1/3, 1/3, 1/3}, P2={1/4, 1/4, 1/2}, которые кодируются одним и тем же кодом φ = {a1®10, a2® 000, a3® 01}. Средняя длина кодового слова для разных распределений будет различной
Lφ(P1)=1/3.2 + 1/3.3 + 1/3.2=7/3 ≈2.33
Lφ(P2)=1/4.2 + 1/4.3 + 1/2.2= 9/4 =2.25
Побуквенный разделимый код называется оптимальным, если средняя длина кодового слова минимальна для данного разделения вероятностей символов. Избыточность кода является показателем качества кода. Избыточностью кода называется разность между средней длиной кодового слова и энтропией источника сообщений r=Lcp-H. Задача эффективного неискажающего сжатия заключается в построении кодов с наименьшей избыточностью, у которых средняя длина кодового слова близка к энтропии источника. К таким кодам относятся классические коды Хаффмена, Шеннона, Фано, Гильберта-Мура.
Приведем некоторые свойства, которыми обладает любой оптимальный побуквенный код.
Лемма 1. Для оптимального кода с длинами кодовых слов L1,…,Ln: верно соотношение L1≤L2≤…≤Ln (p1≥p2≥…≥pn).
Доказательство (от противного): Пусть есть i и j, что Li>Lj при pi>pj. Тогда
Lipi+Ljpj=Lipi+Ljpj+Lipj+Ljpi-Lipj-Ljpi=
=pi(Li-Lj)-pj(Li-Lj)+Ljpi+Lipj=(pi-pj)(Li-Lj) +Lipj+Ljpi>Lipj+Ljpi,
т.е. если поменяем местами Li и Lj, то получим код, имеющий меньшую среднюю длину кодового слова. Противоречие с оптимальностью.
Лемма 2 Пусть 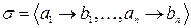 схема оптимального префиксного кодирования для распределения вероятностей Р,
схема оптимального префиксного кодирования для распределения вероятностей Р, 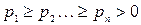 . Тогда среди элементарных кодов, имеющих максимальную длину, существуют два, которые различаются только в последнем разряде.
. Тогда среди элементарных кодов, имеющих максимальную длину, существуют два, которые различаются только в последнем разряде.
Доказательство. Покажем, что в оптимальной схеме кодирования всегда найдется два кодовых слова максимальной длины. Предположим обратное. Пусть кодовое слово максимальной длины одно и имеет вид 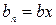 ,
, 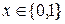 . Тогда длина любого элементарного кода не больше длины b, т.е.
. Тогда длина любого элементарного кода не больше длины b, т.е. 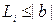 ,
, 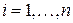 . Поскольку схема кодирования префиксная, то кодовые слова
. Поскольку схема кодирования префиксная, то кодовые слова 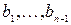 не являются префиксом b. С другой стороны, b не является префиксом кодовых слов . Таким образом, новая схема кодирования
не являются префиксом b. С другой стороны, b не является префиксом кодовых слов . Таким образом, новая схема кодирования 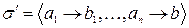 также является префиксной, причем с меньшей средней длиной кодового слова
также является префиксной, причем с меньшей средней длиной кодового слова 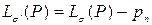 , что противоречит оптимальности исходной схемы кодирования. Пусть теперь два кодовых слова
, что противоречит оптимальности исходной схемы кодирования. Пусть теперь два кодовых слова 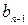 и
и 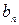 максимальной длины отличаются не в последнем разряде, т.е.
максимальной длины отличаются не в последнем разряде, т.е. 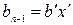 ,
, 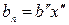 ,
, 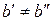 ,
, 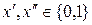 . Причем
. Причем 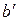 ,
, 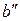 не являются префиксами для других кодовых слов
не являются префиксами для других кодовых слов 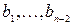 и наоборот. Тогда новая схема
и наоборот. Тогда новая схема 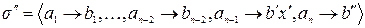 также является префиксной, причем
также является префиксной, причем 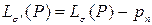 , что противоречит оптимальности исходной схемы кодирования.
, что противоречит оптимальности исходной схемы кодирования.
Рассмотрим алгоритм построения оптимального кода Хаффмена.
1. Упорядочим символы исходного алфавита А={a1,…,an} по убыванию их вероятностей p1≥p2≥…≥pn.
2. Если А={a1,a2}, то a1®0, a2®1.
3. Если А={a1,…,aj,…,an} и известны коды <aj ® bj >, j = 1,…,n ,то для {a1,…aj/ ,aj//…,an}, p(aj)=p(aj/)+ p(aj//), aj/ ® bj0, aj// ®bj1.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Будем складывать две наименьшие вероятности и включать суммарную вероятность на соответствующее место в упорядоченном списке вероятностей до тех пор, пока в списке не останется два символа. Тогда закодируем эти два символа 0 и 1. Далее кодовые слова достраиваются, как показано на рисунке 67.
 a1 0.36 0.36 0.36 0.36 0.64 0
a1 0.36 0.36 0.36 0.36 0.64 0
a2 0.18 0.18 0.28 0.36 0.36 1
a3 0.18 0.18 0.18 0.28 00
a4 0.12 0.16 0.18 000 01
a5 0.09 0.12 010 001
a6 0.07 0100 011
0101
Рисунок 67 Процесс построения кода Хаффмена
Таблица 10 Код Хаффмена
| ai | Pi | Li | кодовое слово |
| a1 a2 a3 a4 a5 a6 | 0.36 0.18 0.18 0.12 0.09 0.07 |
Посчитаем среднюю длину, построенного кода Хаффмена
Lср(P)=1.0.36 + 3.0.18 + 3.0.18 + 3.0.12 + 4.0.09 + 4.0.07 =2.44,
при этом энтропия данного источника равна
H=-(0.36.log0.36+2.0.18.log0.18+0.12.log0.12+0.09.log0.09+0.07log0.07)=2.37
Код Хаффмена обычно строится и хранится в виде двоичного дерева, в листьях которого находятся символы алфавита, а на «ветвях» – 0 или 1. Тогда уникальным кодом символа является путь от корня дерева к этому символу, по которому все 0 и 1 собираются в одну уникальную последовательность.

Рисунок 68 Кодовое дерево для кода Хаффмена
Дата добавления: 2022-02-05; просмотров: 596;
Поиск по сайту
Узнать еще
- Ipv6-адрес/длина префикса.
- А - с прямолинейной спинкой; б - с криволинейной спинкой; в - с канавкой удлиненной формы
- А) Распределение контактных напряжений по длине очага деформации
- А. Секционная система с многослойными длинными блоками
- Алгоритм проверки подлинности сообщения (Message Authenticator Algorithm, MAA)
- Б. Низкочастотный индуктивный метод длинного кабеля
- Б. Секционная система с однослойными длинными блоками из обычного бетона
- Буксирный трос; 2 – якорная скоба; 3 – удлиненное звено; 4 – якорная цепь; 5 – скоба; 6 – стальной трос (свистов); 7 – стопора якорной цепи.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
