Алгоритм на псевдокоде
Построение оптимального кода Хаффмена (n,P)
Обозначим
n – количество символов исходного алфавита
P – массив вероятностей, упорядоченных по убыванию
C – матрица элементарных кодов
L – массив длин кодовых слов
Huffman(n,P)
IF (n=2) C[1,1]:=0, L[1]:=1
C[2,1]:=1, L[2]:=1
ELSE q:=P[n-1]+P[n]
j:=Up(n,q) <поиск и вставка суммы>
Huffman(n-1,P)
Down(n,j) <достраивание кодов>
FI
Функция Up (n,q) находит в массиве P место, куда вставить число q и вставляет его, сдвигая вниз остальные элементы.
DO (i=n-1, n-2,…,2)
IF (P[i-1]≤q) P[i]:=P[i-1]
ELSE j:=I
OD
FI
OD
P[j]:=q
Процедура Down (n,j) формирует кодовые слова.
S:=C[j,*] <запоминание j-той строки матрицы элементарных кодов в массив S>
L:=L[j]
DO (i=j,…,n-2)
C[i,*]:=C[i+1,*] <сдвиг вверх строк матрицы С>
L[i]:=L[i+1]
OD
C[n-1,*]:= S, C[n,*]:= S <восстановление префикса кодовых слов из массива S >
C[n-1,L+1]:=0, C[n,L+1]:=1
L[n-1]:=L+1, L[n]:=L+1
16.5 Почти оптимальное алфавитное кодирование
Рассмотрим несколько классических побуквенных кодов, у которых средняя длина кодового слова близка к оптимальной. Пусть имеется дискретный вероятностный источник, порождающий символы алфавита А={a1,…,an} с вероятностями pi = p(ai), 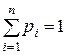 .
.
Код Шеннона
Код Шеннонапозволяет построить почти оптимальный код с длинами кодовых слов Li < - log pi +1. Тогда Lcp <H(p1, …,pn)+1. Код Шеннона строится следующим образом.
1. Упорядочим символы исходного алфавита А={a1,a2,…,an} по убыванию их вероятностей: p1≥p2≥p3≥…≥pn.
2. Составим нарастающие суммы вероятностей Qi:
Q0=0, Q1=p1, Q2=p1+p2, Q3=p1+p2+p3, … , Qn=1.
3. Представим Qi в двоичной системе счисления и возьмем в качестве кодового слова первые é- log2più знаков после запятой .
Для вероятностей, представленных в виде десятичных дробей, удобно определить длину кодового слова Li из соотношения
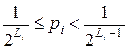 ,
, 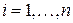 .
.
Пример.Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице.
Таблица 11 Код Шеннона
| ai | Pi | Qi | Li | кодовое слово |
| a1 a2 a3 a4 a5 a6 | 1/22≤0.36<1/2 1/23≤0.18<1/22 1/23≤0.18<1/22 1/24≤0.12<1/23 1/24≤0.09<1/23 1/24≤0.07<1/23 | 0.36 0.54 0.72 0.84 0.93 |
Построенный код является префиксным. Вычислим среднюю длину кодового слова и сравним ее с энтропией. Значение энтропии вычислено при построении кода Хаффмена (H = 2.37).
Lср= 0.36.2+(0.18+0.18).3+(0.12+0.09+0.07).4=2.92< 2.37+1
Дата добавления: 2022-02-05; просмотров: 542;
Поиск по сайту
Узнать еще
- Алгоритм анализа педагогической ситуации и решения педагогических задач.
- Алгоритм анализа последствий неадекватного поведения элемента на смежный с ним
- Алгоритм базовых реанимационных мероприятий (приложение 1)
- Алгоритм безопасного хэширования (Secure Hash Algorithm, SHA)
- Алгоритм Беллмана-Форда
- Алгоритм БПФ с прореживанием по времени
- Алгоритм ведения больных язвенной болезнью
- Алгоритм восстановления аналитической функции по её действительной или мнимой части.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
