ЛЕКЦИЯ 19. МЕТОДЫ ХЭШИРОВАНИЯ
Цели и задачи лекции.Ознакомление со с методом хэширования.
Основные вопросы:организация хранения и поиска данных при использовании метода хэширования , разрешение коллизий.
Хеширование - это способ сведения хранения одного большого множества к более меньшему.Пусть запись, для которой организуется поиск, хранится в некоторой таблице и что прежде, чем найти требуемую запись, необходимо организовать просмотр некоторого количества ключей. Очевидно, что эффективными методами поиска являются те методы, которые минимизируют число этих сравнений. В идеале мы бы хотели иметь такую организацию таблицы, при которой не было бы ненужных сравнений. Посмотрим, возможна ли такая организация.
Если каждый ключ должен быть извлечен за один доступ, то положение записи внутри такой таблицы может зависеть только от данного ключа. Оно не может зависеть от расположения других ключей, как это имеет место в дереве. Наиболее эффективным способом организации такой таблицы является массив.
Предположим, что фирма некоторая фирма выпускает детали и кодирует их семизначными цифрами. Для применения прямой индексации с использованием полного семизначного ключа потребовался бы массив из 100 млн. элементов. Ясно, что это привело бы к потере неприемлемо большого пространства, поскольку совершенно невероятно, что какая-либо фирма может иметь больше чем тысяча наименований изделий. Поэтому необходим некоторый метод преобразования ключа в какое-либо целое число внутри ограниченного диапазона.
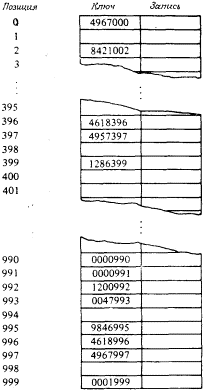
Тогда для хранения всего файла будет достаточно массива из 1000 элементов. Этот массив индексируется целым числом в диапазоне от 0 до 999 включительно. В качестве индекса записи об изделии в этом массиве используются три последние цифры номера изделия.
|
Отметим, что два ключа, которые близки друг к другу как числа (такие как 4618396 и 4618996), могут располагаться дальше друг от друга в этой таблице, чем два ключа,. которые значительно различаются как числа (такие как 0000991 и 9846995). Это происходит из-за того, что для определения позиции записи используются только три последние цифры ключа.
Хеширование - это способ сведения хранения одного большого множества к более меньшему.
Функция, которая трансформирует ключ в некоторый индекс в таблице, называется хеш-функцией.
В данном случае h(key):= key mod 1000;
Хеш-таблица - это обычный массив с необычной адресацией, задаваемой хеш-функцией.{см. рисунок}
Этот метод имеет один недостаток. Давайте добавим в таблицу запись с ключом 0596397. Увидим, что данная ячейка уже занята.
Ситуация, когда два или более ключа ассоциируются с одной и той же ячейкой называется коллизией при хешировании.
Хорошей, с точки зрения практического применения, является такая хеш-функция, которая удовлетворяет следующим условиям:
- функция должна быть простой с вычислительной точки зрения;
- функция должна распределять ключи в хеш-таблице наиболее равномерно;
- функция не должна отображать какую-либо связь между значениями ключей в связь между значениями адресов;
- функция должна минимизировать число коллизий – то есть ситуаций, когда разным ключам соответствует одно значение хеш-функции (ключи в этом случае называются синонимами).
Совершенная хеш-функция - эта функция, которая не порождает коллизий.
Наиболее распространенные методы разрешения коллизии при хешировании: метод открытой адресации, метод цепочек.
Разрешение коллизий при хешировании методом открытой адресации.
Посмотрим, что произойдет, если мы захотим ввести в таблицу некоторый новый номер изделия 0596397. Используя хеш-функцию h(key):=key mod 1000, мы найдем, что h (0596397) =397 и что запись для этого изделия должна находиться в позиции 397 в массиве. Однако позиция 397 уже занята, поскольку там находится запись с ключом 4957397. Следовательно, запись с ключом 0596397 должна быть вставлена в таблицу в другом месте.
Самым простым методом разрешения коллизий при хешировании является помещение данной записи в следующую свободную позицию в массиве. Например, запись с ключом 0596397 помещается в ячейку 398, которая пока свободна, поскольку 397 уже занята. Когда эта запись будет вставлена, другая запись, которая хешируется в позицию 397 (с таким ключом, как 8764397) или в позицию 398 (с таким ключом, как 2194398), вставляется в следующую свободную позицию, которая в данном случае равна 400.
Если ячейка массива h(key) уже занята некоторой записью с другим ключом, то функция rh применяется к значению h(key) для того, чтобы найти другую ячейку, куда может быть помещена эта запись. Если ячейка rh(h(key)) также занята, то хеширование выполняется еще раз и проверяется ячейка rh(rh(h(key))). Этот процесс продолжается до тех пор, пока не будет найдена пустая ячейка. Rh - это функция повторного хеширования, которая воспринимает один индекс в массиве и выдает другой индекс.
Недостатки метода. Во-первых, он предполагает фиксированный размер таблицы. Если число записей превысит этот размер, то их невозможно вставлять без выделения таблицы большего размера и повторного вычисления значений хеширования для ключей всех записей, находящихся уже в таблице, используя новую хеш-функцию.
Во -вторых, из такой таблицы трудно удалить запись.
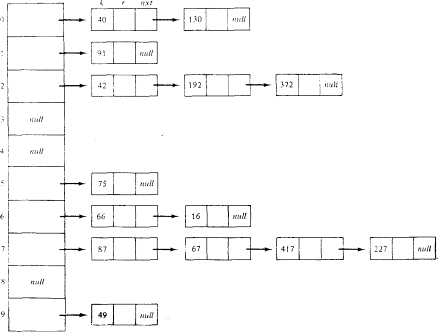
Разрешение коллизий при хешировании методом цепочек
Он представляет собой организацию связанного списка из всех записей, чьи ключи хешируются в одно и то же значение.
75 66 42 192 91 40 49 87 67 16 417 130 372 227
|
Удаление узла из таблицы, которая построена по методу цепочек, заключается просто в исключении узла из связанного списка. Удаленный узел никак не влияет на эффективность алгоритма поиска. Алгоритм будет работать так, как если бы этот узел никогда не вставлялся в таблицу. Отметим, что эти списки могут быть динамически переупорядочены для получения большей эффективности поиска.
Основным недостатком метода цепочек является то, что для узлов указателей требуется дополнительное пространство.
Выбор хеш-функции
Обратимся теперь к вопросу о том, как выбрать хорошую хеш-функцию. Ясно, что эта функция должна создавать как можно меньше коллизий при хешировании, т.е. она должна равномерно распределять ключи на имеющиеся индексы в массиве. Конечно, нельзя определить, будет ли некоторая конкретная хеш-функция распределять ключи правильно, если эти ключи заранее не известны. Однако, хотя до выбора хеш-функции редко известны сами ключи, некоторые свойства этих ключей, которые влияют на их распределение, обычно известны.
1.Метод деления. Некоторый целый ключ делится на размер таблицы и остаток от деления берется в качестве значения хеш-функции. Эта хеш-функция обозначается h (key) := key mod m.
2.Метод середины квадрата. Ключ умножается сам на себя и в качестве индекса используется несколько средних цифр этого квадрата.
3) Аддитивный метод для строк (размер таблицы равен 256). Для строк вполне разумные результаты дает сложение всех символов и возврат остатка от деления на 256.
4) Исключающее ИЛИ для строк (размер таблицы равен 256). Этот метод аналогичен аддитивному, но успешно различает схожие слова и анаграммы (аддитивный метод даст одно значение для XY и YX). Метод заключается в том, что к элементам строки последовательно применяется операция "исключающее или". В алгоритме добавляется случайная компонента, чтобы еще улучшить результат.
Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа.
Дата добавления: 2018-05-10; просмотров: 2165;
Поиск по сайту
Узнать еще
- I. История открытия и методы исследования вирусов
- II. Категории и методы политологии.
- III. Методы искусственной физико-химической детоксикации.
- Абсолютный возраст горных пород и методы его определения
- Автоматические методы изготовления фотошаблонов.
- Агротехнические методы (приемы) обработки почвы.
- Административные методы управления природопользованием
- АКТИВНЫЕ МЕТОДЫ ПРОФКОНСУЛЬТАЦИЙ И ПРОФОРИЕНТАЦИОННЫЕ ИГРЫ

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
