Доверительные интервалы для математического ожидания и дисперсии
Пусть с испытанием связана случайная величина 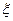 с неизвестными числовыми характеристиками (а, D) и пусть по выборке вычислены оценки
с неизвестными числовыми характеристиками (а, D) и пусть по выборке вычислены оценки 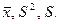
Зададимся числом р в интервале (0,1).
Теорема. В указанной ситуации при достаточно большом объеме выборки с вероятностью р имеют место неравенства
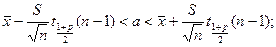
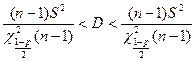 .
.
Эти интервалы называются доверительными интерваламидля математического ожидания и дисперсии. Число р называется уровнем доверияили доверительной вероятностью.
Здесь n-объем выборки, 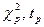 -квантили распределений Пирсона и Стьюдента.
-квантили распределений Пирсона и Стьюдента.
Указанные интервалы иногда называют интервальными оценками для математического ожидания и дисперсии.
Пример. Выполнена выборка значений случайной величины объема n = 25 и вычислены состоятельные несмещенные оценки для математического ожидания и
дисперсии: 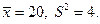 Найти доверительные интервалы для математического ожидания и дисперсии с уровнем доверия р = 0,95.
Найти доверительные интервалы для математического ожидания и дисперсии с уровнем доверия р = 0,95.
В силу неравенств (44), (45) с р = 0,95 имеют место интервальные оценки:
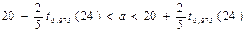 ;
;
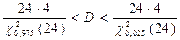 .
.
По таблице квантилей (IV, V) найдем:
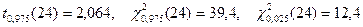 .
.
Подставляя эти значения, получим: с вероятностью 0,95 верны неравенства: 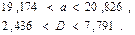
Лекция № 6
Тема: Проверка статистических гипотез
План:
1. Основные определения (статистическая гипотеза и примеры, классификация, ошибки 1-го и 2-го рода). Критерии согласия.
2. Параметрические гипотезы.
Статистикой будем называть любую функцию 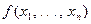 от выборки
от выборки 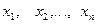 .
.
Статистической называется гипотеза о предполагаемом виде неизвестного распределения или утверждение относительно значений одного или нескольких параметров известного распределения.
Примеры статистических гипотез: генеральная совокупность наблюдаемых значений распределена по закону Пуассона, дисперсия двух нормальных совокупностей, равных между собой.
По содержанию статистические гипотезы можно классифицировать:
1. Гипотезы о типе вероятностного закона распределения случайной величины, характеризующего явление или процесс.
2. Гипотезы об однородности двух или более обрабатываемых выборок. Изучаемое свойство исследуется с помощью двух или более генеральных совокупностей. Гипотеза в этом случае может заключаться в следующем: исследуемые выборочные характеристики различаются между собой статистически значимо или нет.
3. Гипотезы о свойствах числовых значений параметров исследуемой генеральной совокупности. Больше ли значения параметров некоторого заданного номинала или меньше и т.д.
4. Гипотезы о вероятностной зависимости двух или более признаков, характеризующих различные свойства рассматриваемого явления или процесса. При этом определяется характер этой зависимости.
Наряду с выдвинутой гипотезой рассматривают и противоположную ей. Если выдвинутая гипотеза будет отвергнута, то имеет место противоположная ей. По этой причине гипотезы делят на:
1. нулевые (основная);
2. конкурирующие (альтернативной).
Гипотеза, которая подвергается проверке, называется нулевой и обозначается H0. Альтернативной гипотезой H1 (от Hypothesis – «гипотеза» (англ.)) называется гипотеза, конкурирующая с нулевой, т. е. ей противоречащая. Простой называется гипотеза, содержащая только одно предположение.
Кроме того гипотезы делят на простые и сложные. Простой называют гипотезу, содержащую только одно предположение.
Сложной называют гипотезу, состоящую из конечного или бесконечного числа простых гипотез.несколько простых гипотез. Например гипотеза Н: 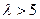 содержит бесчисленное множество простых гипотез Нi:
содержит бесчисленное множество простых гипотез Нi: 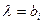 ,где
,где 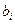 -любое число большее 5.
-любое число большее 5.
Пример. Пусть проверяется гипотеза о равенстве некоторого параметра a значению a0 , т. е. гипотеза H0: a = a0. В этом случае альтернативной гипотезой можно рассматривать одну из следующих гипотез:H1: a > a0; H1: a < a0; H1: a ≠ a0; H1: a > 2. Все приведенные гипотезы простые, и только H1: a > 2– сложная гипотеза.
Выбор альтернативной гипотезы определяется формулировкой решаемой задачи. Причина выделения нулевой гипотезы состоит в том, что чаще всего такие гипотезы рассматриваются как утверждения, которые более ценны, если они опровергаются. Это основано на общем принципе, в соответствии с которым теория должна быть отвергнута, если есть противоречащий ей факт, но не обязательно должна быть принята, если противоречащих ей фактов на текущий момент нет.
Правило, по которому выносится решение принять или отклонить гипотезу H0, называется статистическим критерием. Проверка статистических гипотез осуществляется по результатам наблюдений (экспериментов, опытов), из которых формируют функцию результатов наблюдений, называемую проверочной статистикой. Таким образом, статистический критерий устанавливает, при каких значениях этой статистики проверяемая гипотеза принимается, а при каких она отвергается.
Правило проверки гипотезы о законе распределения:
1. Задаются уровнем значимости 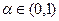 и вычисляют квантиль
и вычисляют квантиль 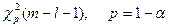 .
.
2. Выполняют выборку 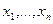 и по формуле вычисляют
и по формуле вычисляют 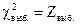 .
.
3. Если 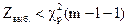 , гипотеза принимается.
, гипотеза принимается.
Если 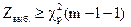 , гипотеза отвергается.
, гипотеза отвергается.
При проверке гипотез по указанному правилу возможны ошибки двух типов:
1. Ошибка первого рода:отвергается верная гипотеза. Вероятность этой ошибки равна уровню значимости a. Действительно, из определения a имеем:
 Р (ошибки 1-го рода)=
Р (ошибки 1-го рода)= 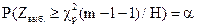
2. Ошибка второго рода: принимается неверная гипотеза. Вероятность этой ошибки обозначают b:
Р (ошибки второго рода)= 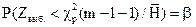 .
.
В конкретной ситуации эта вероятность может быть вычислена.
В математической статистике доказывается: при фиксированном объеме выборки уменьшение уровня значимости a влечет увеличение b и обратно, уменьшение b влечет увеличение a.
Единственный способ уменьшения одновременно a и b - это увеличение объема выборки.
В конкретных ситуациях можно минимизировать вероятность той ошибки, которая ведет к менее тяжелым последствиям. Рекомендуется, если это возможно, проводить проверку более одного раза (набрать хотя бы еще одну выборку).
Мощностью критерия называется вероятность отвергнуть неверную гипотезу:
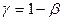 ,где b - вероятность ошибки второго рода.
,где b - вероятность ошибки второго рода.
Малое значение вероятности α, используемое при проверке гипотезы, называется уровнем значимости критерия. Интервал значений 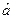 , для которых гипотезу следует отвергнуть, называется областью отклонения гипотезы, или критической областью. Интервал значений , при которых гипотезу следует принять, носит название области принятия гипотезы (см. рис. 1).
, для которых гипотезу следует отвергнуть, называется областью отклонения гипотезы, или критической областью. Интервал значений , при которых гипотезу следует принять, носит название области принятия гипотезы (см. рис. 1).
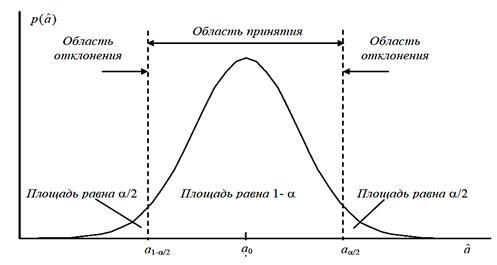
Рис.1. Области принятия и оклонения при проверке гипотез
Приведенный способ проверки гипотезы называется двусторонним критерием, так как если гипотеза H0 верна, то величина может быть как больше, так и меньше a0. Необходимо проверять значимость расхождения между и a0 с обеих сторон. В некоторых задачах может оказаться достаточно одностороннего критерия.
Например, пусть гипотеза состоит том, что a ≥ a0. В этом случае гипотеза будет ошибочной только тогда, когда a < a0, а критерий будет использовать только нижнюю границу плотности распределения p( ).
Как видно на рис. 1, ошибка первого рода происходит в том случае, когда при справедливости гипотезы попадает в область ее отклонения. Таким образом, вероятность ошибки первого рода равна α, т. е. уровню значимости критерия.
Для того чтобы найти вероятность ошибки второго рода, следует определить каким-тообразом величину отклонения истинного значения параметра a от гипотетического значения параметра a0, которое требуется определить. Предполагается, что истинное значение параметра a0 в действительности равно a0 + d или a0 − d (см. рис. 2).
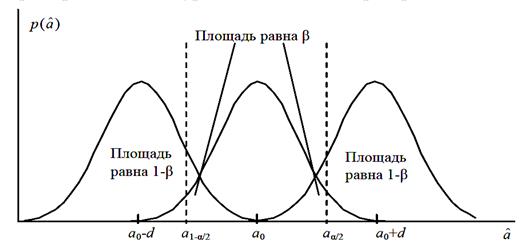
Рис.2. Ошибка второго рода при проверке гипотезы.
Если согласно гипотезе H0: a = a0, а на самом деле a = a0 ± d, то вероятность того, что попадет в область принятия гипотезы H0, т.е. в интервал (a1−α  2, aα 2), составляет β. Таким образом, вероятность ошибки второго рода равна β при выявлении отклонения истинного значения параметра a на ± d от гипотетической величины a0.
2, aα 2), составляет β. Таким образом, вероятность ошибки второго рода равна β при выявлении отклонения истинного значения параметра a на ± d от гипотетической величины a0.
Под статистическим критерием называется случайная величина К с известным законом распределения, служащая для проверки нулевой гипотезы.
Различают три вида критериев:
1) Параметрические критерии- критерии значимости, которые служат для проверки гипотез о параметрах распределения генеральной совокупности при известном виде распределения.
2) Критерии согласия - позволяют проверить гипотезы о соответствии распределений генеральной совокупности известной теоретической модели.
3) Непараметрические критерии- используются в гипотезах, когда не требуется знаний о конкретном виде распределения.
Задача проверки статистических гипотезсводится к исследованию генеральной совокупности по выборке. Множество возможных значений элементов выборки может быть разделено на два непересекающихся подмножества- критическую область и область принятия гипотезы.
Наблюдаемые значения критерия (статистика) Kнабл называют такое значение критерия, которое находится по данным выборки.
Границы критической области, отделяющие ее от области принятия гипотезы, называют критическими точками и обозначают Kкр.
Критической областью называют область значений критерия, при которых нулевую гипотезу отвергают, областью принятия гипотезы – область значений критерия, при которых гипотезу принимают. Итак, процесс проверки гипотезы состоит из следующих этапов:
· выбирается статистический критерий К;
· вычисляется его наблюдаемое значение Кнабл по имеющейся выборке;
· поскольку закон распределения К известен, определяется (по известному уровню значимости α) критическое значение kкр, разделяющее критическую область и область принятия гипотезы (например, если р(К > kкр) = α, то справа от kкр располагается критическая область, а слева – область принятия гипотезы);
· если вычисленное значение Кнабл попадает в область принятия гипотезы, то нулевая гипотеза принимается, если в критическую область – нулевая гипотеза отвергается.
Различают разные виды критических областей:
· правостороннюю критическую область, определяемую неравенством K > kкр (kкр > 0);
· левостороннюю критическую область, определяемую неравенством K < kкр ( kкр < 0);
· двустороннююкритическую область, определяемую неравенствами K < k1, K > k2 (k2 > k1).
Критерии согласия
Критериями согласия называют критерии, в которых гипотеза определяет закон распределения либо полностью, либо с точностью до небольшого числа параметров. Существует несколько различных критериев согласия: критерий Смирнова, критерий Колмогорова, критерий χ2- Пирсона и др.
Рассмотрим универсальный критерий согласия Пирсона. Проверка гипотезы о том, что эмпирическая частота мало отличается от соответствующей теоретической частоты, осуществляется с помощью величины χ2- меры расхождения между ними.
Любая аналитическая функция f(x), с помощью которой аппроксимируется статистическое распределение, должна обладать основными свойствами плотности распределения:
 f (x) ≥ 0
f (x) ≥ 0
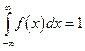
Чтобы оценить, насколько хорошо выбранный теоретический закон распределения согласуется с экспериментальными данными, используются так называемые критерии согласия. Таких критериев существует несколько, но наиболее часто применяется критерий согласия χ2, предложенный Пирсоном. Является непараметрическим критерием проверки статистических гипотез.
Пусть проведено n независимых опытов, в каждом из которых случайная величина X приняла определенное значение. Результаты опытов сведены в k интервалов, и построены статистический ряд, выборочная функция распределения и гистограмма, т.е. экспериментальные данные описываются выборочным законом распределения P*(x). Необходимо проверить, согласуются ли экспериментальные данные с гипотезой H0: P(x) = P*(x) о том, что случайная величина X имеет выбранный теоретический закон распределения P(x), который может быть задан функцией распределения F(x) или плотностью f(x). Альтернативная гипотеза в этом случае – H1: P(x) ≠ P*(x).
Знание теоретического закона распределения позволяет найти теоретические вероятности попадания случайной величины в каждый интервал
(xi, xi+ 1), i = 1, k: p1, p2, K, pk.
Проверка согласованности теоретического и статистического распределений сводится к оценке расхождений между теоретическими вероятностями pi и полученными частотами p*i. В качестве меры расхождения удобно выбрать сумму квадратов отклонений(p*i − pi), взятых с некоторыми «весами» ci:
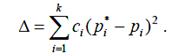
Смысл коэффициентов ci («весов» интервалов) состоит в том, что отклонения, относящиеся к разным интервалам, нельзя считать одинаковыми по значимости. То есть одно и то же по абсолютной величине отклонение p*i − pi может быть мало значимым, если сама вероятность pi велика, и, наоборот, быть заметным, если эта вероятность мала. Естественно, веса ci выбирать по величине обратно пропорционально вероятностям pi. Пирсон доказал, что если выбрать ci = n/pi, то при больших n закон распределения случайной величины практически не зависит от функции распределения F(x) и числа испытанийn, а зависит только от числа разрядов k и стремится к распределению χ2. Обозначив через χ2 меру расхождения , получаем:
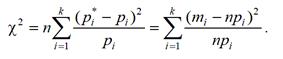
Распределение зависит от параметра r, называемого числом степеней свободы, которое равно:
r = k − s,
где k – число интервалов, s – число независимых условий («связей»), накладываемых на частоты p* и параметры распределения. Так, при аппроксимации нормального распределения s = 3, а при исследовании распределения Пуассона s = 2.
Схема применения критерия χ2 для оценки согласованности теоретического и статистического распределения сводится к следующим процедурам (этапам):
1. На основании полученных экспериментальных данных x1, x2, K, xnрассчитываются значения частот p*i в каждом из k интервалов.
2. Вычисляются, исходя из теоретического распределения, вероятности pi попадания значений случайной величины в интервалы(xi, xi + 1).
3. По формуле рассчитывается значение χ2.
4. Определяется число степеней свободы r = k − s.
5. По таблице процентных значений распределения χ2 определяется вероятность α того, что случайная величина, имеющая распределение χ2 с r степенями свободы превзойдет полученное на этапе 3 значение χ2. Если эта вероятность мала, то гипотеза H0: P(x) = P*(x) отбрасывается как неправдоподобная. Если же эта вероятность относительно велика, то гипотезу H0: P(x) = P*(x) можно признать не противоречащей опытным данным.
Пример. Пусть случайная величина X – значения напряжения на выходе генератора шума. Проверим, согласуются ли полученные данные с нормальным законом распределения.
Получено n = 500 значений, при этом оценки математического ожидания и среднего квадратичного значения соответственно равны: m = 0,344; σ = 3,2605. Для теоретического нормального распределения с полученными параметрами m и σ вычисляем вероятности попадания в каждый из 10 интервалов по формуле
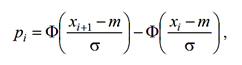
xi + 1, xi – границы i -гоинтервала,Φ(x) – функция Лапласа (табличная).
Затем создается таблица, содержащая число попаданий mi в каждый разряд и соответствующие значения npi для n = 500.

По формуле для χ2:
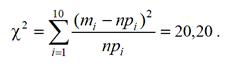
Так как число степеней свободы r = 10 − 3 = 7, то по таблице процентных точек χ2 распределения находим, что χ27; 0,01 = 18,48
Поскольку χ2 > χ27;0,01 для малой вероятности α = 0,01, следует признать: полученные экспериментальные данные противоречат проверяемой гипотезе о том, что случайная величина X распределена по нормальному закону.
При использовании критерия согласия (χ2 или любого другого) положительный ответ нельзя рассматривать как утвердительный о правильности выбранной гипотезы. Определенным является лишь отрицательный ответ, т.е. если полученная вероятность α мала, то можно отвергнуть выбранную гипотезу H0: P(x) = P*(x) и отбросить ее как явно не согласующуюся с экспериментальными данными. Если же вероятность α велика, то это не может считаться доказательством справедливости гипотезы
H0: P(x) = P*(x), а указывает только на то, что гипотеза не противоречит экспериментальным данным.
При использовании критерия согласия χ2 достаточно большими должны быть не только общее число опытов n (несколько сотен), но и значения mi в отдельных интервалах. Для всех интервалов должно выполняться условие mi ≥ 5. Если для некоторых интервалов это условие нарушается, то соседние интервалы объединяются в один.
Дата добавления: 2019-12-09; просмотров: 1139;
Поиск по сайту
Узнать еще
- Andantino con moto А. Бородин. Для берегов отчизны дальней
- I тип реакций. Реакции, характерные для органических кислот.
- I. 5. Тесты для контроля знаний раздела I
- II раздел. Организация работы логопеда в группе для детей с ОНР
- III. Здания для проживания людей
- III. Тесты для самоконтроля студентов
- III. ТРЕБОВАНИЯ РКФ ДЛЯ ДОПУСКА СОБАК В ПЛЕМЕННОЕ РАЗВЕДЕНИЕ
- IV. Сложнолегированные сплавы для горячего изостатического прессования (ГИП).

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
