Системы итерированных функций
Метод "Систем Итерируемых Функций" (Iterated Functions System - IFS) появился в середине 80-х годов двадцатого века как простое средство получения фрактальных структур. IFS представляет собой систему функций из некоторого фиксированного класса функций, отображающих одно многомерное множество на другое. В 1988 году известные американские специалисты в теории динамических систем и эргодической теории Барнсли и Слоан предложили некоторые идеи, основанные на соображениях теории динамических систем, для сжатия и хранения графической информации. Они назвали свой метод методом фрактального сжатия информации. Происхождение названия связано с тем, что геометрические образы, возникающие в этом методе, обычно имеют фрактальную природу в смысле Мандельброта.
На основании этих идей Барнсли и Слоан создали алгоритм, который, по их утверждению, позволит сжимать информацию в 500-1000 раз. Вкратце метод можно описать следующим образом. Изображение кодируется несколькими простыми преобразованиями (в нашем случае аффинными), т.е. коэффициентами этих преобразований.
Например, закодировав какое-то изображение двумя аффинными преобразованиями, мы однозначно определяем его с помощью 12-ти коэффициентов. Если теперь задаться какой-либо начальной точкой (например X=0 Y=0) и запустить итерационный процесс, то мы после первой итерации получим две точки, после второй - четыре, после третьей - восемь и т.д. Через несколько десятков итераций совокупность полученных точек будет описывать закодированное изображение. Но проблема состоит в том, что очень трудно найти коэффициенты IFS, которая кодировала бы произвольное изображение.
Для построения IFS применяют кроме аффинных и другие классы простых геометрических преобразований, которые задаются небольшим числом параметров.
Мы обратимся теперь к одному из наиболее замечательных и глубоких достижений в построении фракталов — системам итерированных функций. Математические аспекты были разработаны Джоном Хатчинсоном , а сам метод стал широко известен благодаря Майклу Барнсли. Подход на основе систем итерированных функций предоставляет собой хорошую теоретическую базу для математического исследования многих классических фракталов, а также их обобщений. Разработанная теория используется при переходе к исследованию хаоса, связанного с фракталами.
Следует иметь в виду, что результат применения системы итерированных функций, называемый аттрактором, не всегда является фракталом. Это может быть любой компакт, включая интервал или квадрат. Тем не менее, изучение систем итерированных функций важно для фрактальной теории, так как с их помощью можно получить удивительное множество фракталов. Теория итерированных функций замечательна сама по себе и служит составной частью общей теории динамических систем, важного раздела математики.
Прежде чем углубиться в теорию систем итерированных функций, рассмотрим пример, а именно ковер Серпинского, который мы уже строили прежде. Для построения мы выбирали в качестве исходного множества треугольник и на каждом шаге выкидывали центральную треугольную часть (не включая границу) образующихся треугольников. Ниже мы рассмотрим два других метода: детерминированный и рандомизированный.

Рис. 4.1. Построение ковра Серпинского с помощью детерминорованной СИФ
Построение ковра Серпинского в детерминированном алгоритме начинается с выбора компактного множества 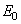 , например квадрата (рис. 4.1). Затем задаются аффинные преобразования так чтобы исходное множество было преобразовано, как показано на втором шаге построения рис. 4.1. Это достигается путем выбора следующих трех преобразований:
, например квадрата (рис. 4.1). Затем задаются аффинные преобразования так чтобы исходное множество было преобразовано, как показано на втором шаге построения рис. 4.1. Это достигается путем выбора следующих трех преобразований:
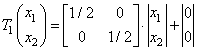 ,
,
 ,
,

и преобразование компактного множества записывается в виде
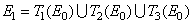 .
.
После выполнения 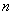 таких преобразований, получаем изображение соответствующее ковру Серпинского:
таких преобразований, получаем изображение соответствующее ковру Серпинского:
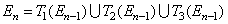 .
.
Заметим, что все множество возможных построений определяется набором аффинных преобразований 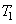 ,…,
,…, 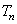 .
.
Обычно коэффициенты аффинного преобразования записываются в матрицу 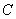 размером
размером  элементов:
элементов:
 ,
,
которая полностью описывает фрактальное множество.
В рандомизированном алгоритме, который часто называют игрой в «Хаос», в качестве начального множества выбирают одну точку:
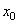 - начальная точка (с произвольными координатами)
- начальная точка (с произвольными координатами)
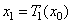 или
или 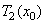 или
или 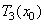
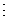
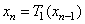 или
или 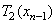 или
или 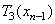
На каждом шаге, вместо того чтобы применять сразу три преобразования 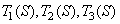 , мы применяем только одно, выбранное случайным образом. Таким образом, на каждом шаге мы получаем ровно одну точку. Оказывается, что после некоторого переходного процесса точки, сгенерированные в рандомизированном алгоритме, заполняют в точности ковер Серпинского.
, мы применяем только одно, выбранное случайным образом. Таким образом, на каждом шаге мы получаем ровно одну точку. Оказывается, что после некоторого переходного процесса точки, сгенерированные в рандомизированном алгоритме, заполняют в точности ковер Серпинского.
Замечательным свойством алгоритмов, основанных на теории систем итерированных функций, является то, что их результат (аттрактор) совершенно не зависит от выбора начального множества или начальной точки В случае детерминированного алгоритма это означает, что в качестве можно взять любое компактное множество на плоскости: предельное множество по-прежнему будет совпадать с ковром Серпинского. В случае рандомизированного алгоритма, вне зависимости от выбора начальной точки , после нескольких итераций точки начинают заполнять ковер Серпинского.
Для равномерного распределения точек по экрану в рандомизированном алгоритме аффинные преобразования следует выбирать с вероятностью
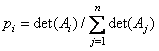 ,
,
где 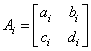 - матрица соответствующего аффинного преобразования. Очевидно, что
- матрица соответствующего аффинного преобразования. Очевидно, что 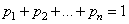 .
.
В общем случае, для чтобы построить систему итерированных функций введем в рассмотрение совокупность сжимающих отображений:
- с коэффициентом сжатия 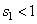 ,
,
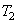 - с коэффициентом сжатия
- с коэффициентом сжатия 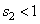 ,
,
- с коэффициентом сжатия 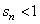 .
.
Эти отображений используются для построения одного сжимающего отображения 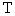 .
.
Таким образом, системой итерированных функций (СИФ) называют совокупность введенных выше отображений вместе с итерационной схемой:
- компактное множество (произвольное)
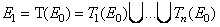 ,
,
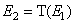 ,
,
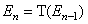 ,
,
Основная задача теории СИФ — выяснить, когда СИФ порождает предельное множество :
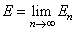 .
.
Если предел существует, то множество Е называют аттрактором системы итерированных функций. Причем аттрактор часто (но не всегда!) оказывается фрактальным множеством. Очевидно, для того чтобы обеспечить сходимость, требуется наложить определенные ограничения на введенные выше преобразования, к примеру запретить точкам уходить на бесконечность.
Основные математические идеи, необходимые для установления условий сходимости, уже были представлены. Если нам удастся показать, что Т является сжимающим отображением на метрическом пространстве (К.,Н), то мы сможем применить теорию сжимающих отображений. В этом случае аттрактор Е есть не что иное, как неподвижная точка отображения Т.

1. Системы итерированных функций
Традиционно в математике, пространства и множества содержат в себе точки. Однако же, существуют пространства, в которых “точки” сами являются множествами. С математической точки зрения, достоинство абстрагирования от точки состоит в достижении общности.
Пример этого – сжимающие отображения и связанные с ними теоремы сходимости. Сжимающие отображения определяются в метрических пространствах как отображения уменьшающие расстояния между точками. Сжимающие отображения обладают важным свойством. Если взять любую точку и начать итеративно применять к ней одно и то же сжимающее отображение: f(f(f...f(x))), то результатом будет всегда одна и та же точка. Чем больше раз применим, тем точнее найдем эту точку. Называется она неподвижной точкой и для каждого сжимающего отображения она существует, причем только одна. Системы итерированных функций (IFS) являются примером применения этой теории.
Фрактальное сжатие изображений — это алгоритм сжатия изображений c потерями, основанный на применении систем итерируемых функций (IFS, как правило являющимися аффинными преобразованиями) к изображениям. Данный алгоритм известен тем, что в некоторых случаях позволяет получить очень высокие коэффициенты сжатия (лучшие примеры — до 1000 раз при приемлемом визуальном качестве) для реальных фотографий природных объектов, что недоступно для других алгоритмов сжатия изображений в принципе. Из-за сложной ситуации с патентованием широкого распространения алгоритм не получил.
Суть фрактального сжатия
Основа метода фрактального кодирования — это обнаружение самоподобных участков в изображении. Впервые возможность применения теории систем итерируемых функций (IFS) к проблеме сжатия изображения была исследована Майклом Барнсли (Michael Barnsley) и Аланом Слоуном (Alan Sloan). Они запатентовали свою идею в 1990 и 1991 гг (U.S. Patent 5,065,447 (англ.)). Джеквин (Jacquin) представил метод фрактального кодирования, в котором используются системы доменных и ранговых блоков изображения (domain and range subimage blocks), блоков квадратной формы, покрывающих все изображение. Этот подход стал основой для большинства методов фрактального кодирования, применяемых сегодня. Он был усовершенствован Ювалом Фишером (Yuval Fisher) и рядом других исследователей. В соответствии с данным методом изображение разбивается на множество неперекрывающихся ранговых подизображений (range subimages) и определяется множество перекрывающихся доменных подизображений (domain subimages). Для каждого рангового блока алгоритм кодирования находит наиболее подходящий доменный блок и аффинное преобразование, которое переводит этот доменный блок в данный ранговый блок. Структура изображения отображается в систему ранговых блоков, доменных блоков и преобразований.
Идея заключается в следующем: предположим что исходное изображение является неподвижной точкой некоего сжимающего отображения. Тогда можно вместо самого изображения запомнить каким-либо образом это отображение, а для восстановления достаточно многократно применить это отображение к любому стартовому изображению.
По теореме Банаха, такие итерации всегда приводят к неподвижной точке, то есть к исходному изображению. На практике вся трудность заключается в отыскании по изображению наиболее подходящего сжимающего отображения и в компактном его хранении. Как правило, алгоритмы поиска отображения (то есть алгоритмы сжатия) в значительной степени переборные и требуют больших вычислительных затрат. В то же время, алгоритмы восстановления достаточно эффективны и быстры. Вкратце метод, предложенный Барнсли, можно описать следующим образом. Изображение кодируется несколькими простыми преобразованиями (в нашем случае аффинными), то есть определяется коэффициентами этих преобразований (в нашем случае A, B, C, D, E, F).
Например, изображение кривой Коха можно закодировать четырмя аффинными преобразованиями, мы однозначно определим его с помощью всего 24-х коэффициентов. Далее, поставив чёрную точку в любой точке картинки мы будем применять наши преобразования в случайном порядке некоторое (достаточно большое) число раз (этот метод ещё называют фрактальный пинг-понг).
В результате точка обязательно перейдёт куда-то внутрь чёрной области на исходном изображении. Проделав такую операцию много раз мы заполним все чёрное пространство, тем самым восстановив картинку.
Основная сложность метода
Основная сложность фрактального сжатия заключается в том, что для нахождения соответствующих доменных блоков вообще говоря требуется полный перебор. Поскольку при этом переборе каждый раз должны сравниваться два массива, данная операция получается достаточно длительной. Сравнительно простым преобразованием её можно свести к операции скалярного произведения двух массивов, однако даже скалярное произведение считает сравнительно длительное время. На данный момент известно достаточно большое количество алгоритмов оптимизации перебора, возникающего при фрактальном сжатии, поскольку большинство статей, исследовавших алгоритм были посвящены этой проблеме, и во время активных исследований (1992—1996 года) выходило до 300 статей в год. Наиболее эффективными оказались два направления исследований: метод выделения особенностей (feature extraction) и метод классификации доменов (classification of domains).
Патенты
Майклом Барнсли и другими было получено несколько патентов на фрактальное сжатие в США и других. Например, U.S. Patent 4,941,193 (англ.), 5,065,447 (англ.), 5,384,867 (англ.), 5,416,856 (англ.) и 5,430,812 (англ.). Эти патенты покрывают широкий спектр возможных изменений фрактального сжатия и серьёзно сдерживают его развитие.
Данные патенты не ограничивают исследований в этой области, то есть можно придумывать свои алгоритмы на основе запатентованных и публиковать их. Также можно продавать алгоритмы в страны, на которые не распространяются полученные патенты. Кроме того срок действия большинства патентов — 17 лет с момента принятия и он истекает для большинства патентов в ближайшее время, соответственно использование методов, покрывавшихся этими патентами станет гарантированно свободным.
1.1 Определение
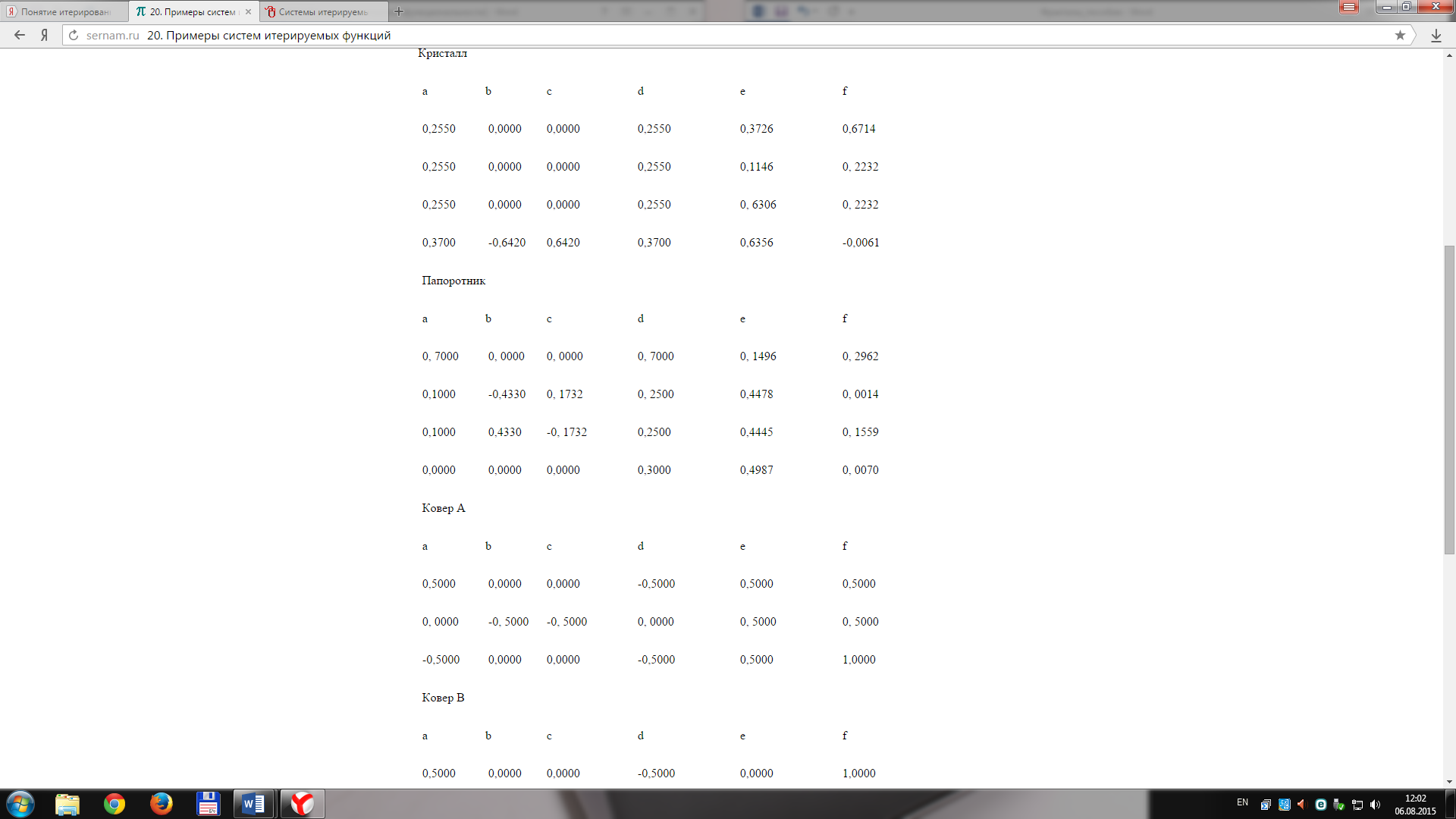
Система итерированных функций это конечный набор функций Fi: X -> X в метрическом про-странстве X. Каждая из них расширяется до отображения Fi: H(X) -> H(X), где H(X) это пространство точки которого являются непустыми сжатыми подмножествами X. Если использовать Хаусдорфову метрику, то H(X) полно если X было полным. Кроме того, сжатия FiX X остаются сжатиями и на H(X). В совокупности, {Fi} определяют новое сжатие F: H(X) -> H(X), по следующей формуле: для каждого A∈H(X), F(A) = ∪Fi(A). Из общей теории, для полного метрического пространства X, F имеет фиксированную точку AF: F(AF) = AF, которую можно достичь последовательными приближениями из любой начальной точки. Фиксированные точки IFS иногда называются аттракторами или инвариантами.
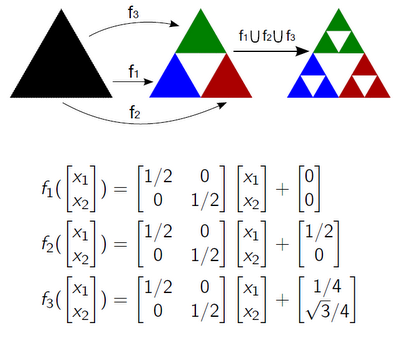
Рисунок 6. Пример построения треугольника Серпинского с помощью IFS.
Таким образом, возникают две задачи. Первая – это нахождение аттрактора заданной IFS. Вто-рая проблема противоположна первой: для заданного множества A∈H(X), найти IFS {Fi} для которой A является аттрактором.
1.2 Детерминированный алгоритм
Первая проблема решается с помощью детерминированного алгоритма.
Начнем с множества A0∈H(X) и станем последовательно вычислять
Ak = ∪Fi(Ak-1) = F(Ak-1), k > 1. Ряд {Ak) сходится к аттрактору AF при k.
1.3 Алгоритм случайных итераций
Математика альтернативного алгоритма – алгоритма случайных итераций, сложнее, но его при-менение проще. Сопоставим позитивные частоты pi отображениям Fi. Начнем с произвольной точки x0∈X. На каждом шаге k+1, выберем xk+1 из множества {Fi(xk)}. Fj(xk) выбирается с веро-ятностью pj / pi. Последовательность[5] {xk} сходится к AF. На практике, чтобы изобразить при-ближение AF на компьютере, точки последовательности выводятся на экран. Числа {pi} никак не изменяют AF, но существенно влияют на процесс отображения его приближений.
1.4 Теорема коллажа
Обратная задача приближенно решается теоремой коллажа. Цитируя М. Барнсли: “теорема го-ворит нам, что чтобы найти IFS аттрактор которой “похож” на данное множество необходимо найти набор сжимающих отображений некоторого большего множества включающего своим подмножеством исходное множество, таких, что объединение, или коллаж, отображений этого множества аппроксимировало бы исходное множество”.
1.5 Использование
[2]
Основной областью применения IFS является сжатие изображений. Произвольные изображения, в отличие от фракталов, не самоподобны, так что так просто эта задача не решается. Как это сделать придумал в 1992 году Арнольд Жакин, в то время — аспирант Майкла Барнсли.
Самоподобие необходимо — иначе ограниченные в своих возможностях аффинные преобразо-вания не смогут правдоподобно приблизить изображения. А если его нет между частью и целым, то можно поискать между частью и частью.
Упрощенная схема кодирования выглядит так:
· Изображение делится на небольшие неперекрывающиеся квадратные области, называе-мые ранговыми блоками.
· Строится пул всех возможных перекрывающихся блоков в четыре раза больших ранго-вых — доменных блоков.
· Для каждого рангового блока по очереди «примеряем» доменные блоки и ищем такое преобразование, которое делает доменный блок наиболее похожим на текущий ранго-вый.
· Пара «преобразование — доменный блок», которая приблизилась к идеалу, ставится в соответствие ранговому блоку. В закодированное изображение сохраняются коэффициенты преобразования и координаты доменного блока. Содержимое доменного блока нам ни к чему — вы же помните, нам все равно с какой точки стартовать.
На картинке ранговый блок обозначен жёлтым, соответствующий ему доменный — красным. Также показаны этапы преобразования и результат.
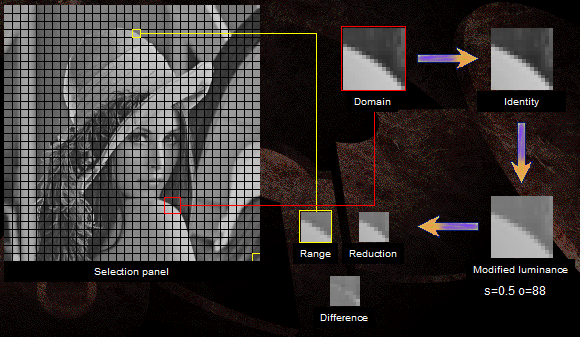
Рисунок 7. Пример сжатия изображения.
Получение оптимального преобразования — отдельная тема, однако большого труда оно не составляет. Но другой недостаток схемы виден невооруженным глазом. Двухмегапиксельное изображение будет содержать огромное число доменных блоков размером 32x32. Полный их перебор для каждого рангового блока и есть основная проблема такого вида сжатия — коди-рование занимает очень много времени. С этим борются при помощи различных ухищрений, вроде сужения области поиска или предварительной классификации доменных блоков.
Декодирование же производится просто и довольно быстро. Берем любое изображение, делим на ранговые области, последовательно заменяем их результатом применения соответствующего преобразования к соответствующей доменной области (что бы она ни содержала в данный мо-мент). После нескольких итераций исходное изображение станет похоже на себя:

Рисунок 8. Пример восстановления сжатого изображения.
1. Системы Линденмайера
Красота растений привлекала внимание математиков веками. Активнее всего изучались интересные геометрические свойства растений, такие как симметрия листьев относительно центральной оси, радиальная симметрия цветов, и спиральное расположение семечек в шишках. «Красота связана с симметрией» (H. Weyl. Symmetry). Во время роста живых организмов, особенно растений, можно четко видеть регулярно повторяющиеся многоклеточные структуры. В случае составных листьев, например, маленькие листочки, которые являются частью большого взрослого листа, имеют ту же форму, что весь лист имел на раннем этапе формирования.
В 1968 г. Венгерский биолог и ботаник Аристид Линденмайер (Aristid Lindenmayer) предложил математическую модель для изучения развития простых многоклеточных организмов. Позже она была расширена и используется для моделирования сложных ветвящихся структур — разнообразных деревьев и цветов. Эта модель получила название Lindenmayer System, или просто L-System.
2.1 Основные идеи
Основная идея L-систем — постоянная перезапись (rewriting) элементов строки. Перезапись — это способ получения сложных объектов путем замены частей простого начального объекта по некоторым правилам. Классическим примером является снежинка Коха. На рисунке инициатор — это начальный объект, грани которого заменяются на объект-генератор. Далее с новым объектом проделывается то же самое.
Рисунок 1. Снежинка Коха.
Возвращаясь к L-системам и проводя аналогию с фракталами, можно сказать, что L-система оперирует со строкой символов по специальным правилам, начиная с первоначальной простой аксиомы. Таким образом, L-система является математической грамматикой. Но фундаментальное отличие L-систем от формальных грамматик состоит в том, что правила применяются одновременно ко всей строке, к каждому символу, плюс, нет понятий терминальных и нетерминальных символов. То есть «вывод» по этой грамматике может продолжаться бесконечно.
На следующей картинке видно соотношение между контекстно-свободными (OL), контекстно-зависимыми (IL) L-системами и другими формальными грамматиками в иерархии Хомского.
Рисунок 2. Иерархия Хомского.
2.2 Простейшие L-системы
Также, как и в классификации Хомского, L-системы имеют и свою классификацию от простых до сложных и мощных.
Самым простым примером являются детерминированные контекстно-свободные L-системы или сокращенно DOL. Я не люблю формальные определения грамматик, так что скажу просто своими словами. Есть некоторый набор символов — алфавит. Этим алфавитом записывается строка, с которой работает L-система. Есть аксиома — первоначальная строка из одной или более буквы и набор правил вида a → ab. Во время каждой итерации алгоритма, применяя правило к букве из текущей строки, она (буква) заменяется на набор букв справа от стрелки. Проще рассмотреть конкретный пример развития многоклеточного организма Anabaena catenula, который изучал Линденмайер, когда он предложил модель L-систем.
Пусть наш алфавит состоит из следующих символов, каждый из которых обозначает некоторую клетку: alar bl br.
Аксиома состоит из одного символа:
ω: ar
И четырех правил.
p1: ar → albr
p2: al → blar
p3: br → ar
p4: bl → al
Правила говорят, какие символы меняются на какие в процессе роста организма. На картинке видно как, применяя правила мы наблюдаем «деление» клеток и развитие.
Рисунок 3. L-система симулирующая развитие Anabaena catenula.
2.4 Использование LOGO
Пока мы видели как нарисовать одномерную бактерию, но с помощью известного детского языка программирования LOGO, в котором предлагается управлять черепашкой и рисовать фи-гуры на экране, можно будет уже рисовать двумерные и трехмерные фракталы и повторяющие-ся структуры. Как? Все просто. Берем алфавит, в котором каждый символ означает некоторую команду для двумерной или трехмерной черепашки:
· F — продвинуться вперед и нарисовать линию
· f — продвинуться вперед ничего не рисуя
· + — повернуть влево
· — — повернуть вправо
· & — повернуть вниз
· ^ — повернуть вверх
· \ — наклониться влево
· / — наклониться вправо
· | — развернуться на 180 градусов
Эти команды используют стандартные значения угла поворота δ, длины шага и базисные векторы двумерного и трехмерного пространства. Примеры двумерных фракталов и порожда-ющих их L-системы можно увидеть на следующей картинке:
Рисунок 4. Примеры L-систем.
2.5 Растения и ветвящиеся структуры
Все, что было до этого является, в общем-то, непрерывными кривыми. Такой способ моделирования не подходит для моделирования растений с их ветвящейся топологией. Для этого в алфавит были добавлены символы [ и ], которые обозначают начало и конец ветвления соответственно. Когда черепашка встречает символ [, ее текущее состояние пишется в стек и извлекает-ся оттуда при встрече символа ]. Уже такой простой грамматикой можно сгенерировать доволь-но интересные двумерные и трехмерные объекты похожие на деревья.
Рисунок 5. Примеры ветвящихся L-систем.
2.6 Стохастические L-системы
Стохастические L-системы добавляют возможность задания вероятности выполнения того или иного правила, и в общем случае не являются детерминированными, ибо разные правила могут иметь один и тот же символ слева. Это вносит некоторый элемент случайности в получающиеся структуры.
2.7 Контекстно-зависимые L-системы
Так же, как и контекстно зависимость в формальных грамматиках, в L-системы синтаксис пра-вил усложняется и принимает во внимание окружение заменяемого символа.
2.8 Параметрические L-системы
К каждому символу добавляется параметр-переменная (возможно не одна), которая позволяет, например, указывать величину угла поворота для + и -, длину шага и толщину линии, проверять условия для применения правила, считать количество итераций и передавать «сигналы» вперед и назад. Пример параметрической L-системы.
ω: B(2)A(4, 4)
p1: A(x, y) :y <= 3 → A(x ∗ 2, x + y)
p2: A(x, y) :y > 3 → B(x)A(x/y, 0)
p3: B(x) :x < 1 → C
p4: B(x) :x >= 1 → B(x − 1)
Параметрические контекстно-зависимые L-системы позволяют моделировать рост многокле-точных организмов и растений с учетом биохимических процессов и окружающей среды.
2.9 Использование
Еще в конце 80х L-системы использовались для визуализации моделей растений. Сейчас воз-можности компьютеров ушли далеко вперед. Многие игры и инструменты 3d моделирования используют процедурную генерацию контента, в том числе и L-системы. Как видите, из набора простых правил можно получить огромное количество разных растений и засадить ими целые поля.
Реализация СИФ
Имеется два подхода к реализации СИФ: детерминированный и рандомизированный. В качестве примера рассмотрим салфетку Серпинского, построение которой рассматривалось ранее (1.1.6). В качестве исходного множества брался треугольник и на каждом шаге построения удалялась центральная часть образующихся треугольника (не включая границу). Т.е. для построения использовались следующие три аффинных преобразования (рис.1):
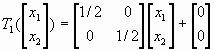
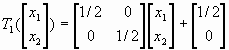
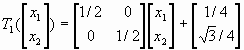
Если S — замкнутое множество в виде треугольника с вершинами (0, 0), (1, 0) и (1/2, 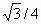 ), то образы
), то образы 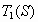 ,
, 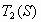 и
и 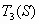 суть три меньшие треугольные области, изображённые на рисунке справа.
суть три меньшие треугольные области, изображённые на рисунке справа.
В детерминированном алгоритме рассматривают следующую последовательность множеств:
 компактное множество (произвольное)
компактное множество (произвольное)
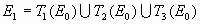
…
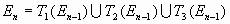
…
Если в качестве 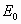 выбрать замкнутую треугольную область S, то множества
выбрать замкнутую треугольную область S, то множества 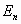 , построенные указанным способом, будут в точности те же, что и при удалении центральных треугольных частей.
, построенные указанным способом, будут в точности те же, что и при удалении центральных треугольных частей.
В рандомизированном алгоритме, который часто называют игрой “Хаос”, в качестве начального множества выбирают одну точку:
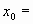 начальная точка (произвольная)
начальная точка (произвольная)
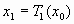 или
или 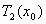 или
или 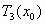
…
 или
или 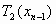 или
или 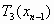
…
На каждом шаге, вместо того чтобы применять сразу три преобразования 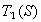 , , , применяется только одно, выбранное случайным образом. Таким образом, на каждом шаге получается ровно одна точка. Оказывается, что после некоторого переходного этапа точки, сгенерированные в рандомизированном алгоритме, заполняют в точности салфетку Серпинского.
, , , применяется только одно, выбранное случайным образом. Таким образом, на каждом шаге получается ровно одна точка. Оказывается, что после некоторого переходного этапа точки, сгенерированные в рандомизированном алгоритме, заполняют в точности салфетку Серпинского.
Замечательным свойством алгоритмов, основанных на теории систем итерированных функций, является то, что их результат (аттрактор) совершенно не зависит от выбора начального множества или начальной точки  . В случае детерминированного алгоритма это означает, что в качестве можно взять любое компактное множество на плоскости: предельное множество по-прежнему будет совпадать с салфеткой Серпинского. В случае рандомизированного алгоритма, вне зависимости от выбора начальной точки , после нескольких итераций точки начнут заполнять салфетку Серпинского.
. В случае детерминированного алгоритма это означает, что в качестве можно взять любое компактное множество на плоскости: предельное множество по-прежнему будет совпадать с салфеткой Серпинского. В случае рандомизированного алгоритма, вне зависимости от выбора начальной точки , после нескольких итераций точки начнут заполнять салфетку Серпинского.
Рис.2 Рис.3
Заметим, что любое аффинное преобразование в 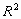 определяется всего шестью коэффициентами, поэтому СИФ реализует фрактальное сжатие салфетки Серпинского. Множество
определяется всего шестью коэффициентами, поэтому СИФ реализует фрактальное сжатие салфетки Серпинского. Множество 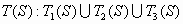 представляет собой композицию (коллаж) трёх уменьшенных копий S. Нахождение коэффициентов аффинных преобразований по фрагменту коллажа называют обратной задачей в теории фракталов. В её решении важную роль играет следующая теорема о коллаже.
представляет собой композицию (коллаж) трёх уменьшенных копий S. Нахождение коэффициентов аффинных преобразований по фрагменту коллажа называют обратной задачей в теории фракталов. В её решении важную роль играет следующая теорема о коллаже.
Теорема: Пусть I — непустое компактное множество (исходное изображение), 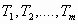 — сжимающие отображения с коэффициентами сжатия
— сжимающие отображения с коэффициентами сжатия 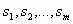 соответственно, Е — аттрактор СИФ, связанной с этими отображениями, и
соответственно, Е — аттрактор СИФ, связанной с этими отображениями, и 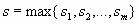 . Тогда, если для некоторого >0 выполняется неравенство:
. Тогда, если для некоторого >0 выполняется неравенство:
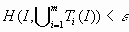 ,
,
то 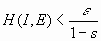
Таким образом, для решения обратной задачи следует выбирать I, “похожее” на фрагмент коллажа.
Дата добавления: 2021-09-07; просмотров: 1321;
Поиск по сайту
Узнать еще
- F45.38 другие органы или системы
- F82 Специфическое расстройство развития двигательных функций
- I. История возникновения и развития классно-урочной системы.
- I. Развитие Донбасса в условиях кризиса феодально-крепостнической системы
- I. Создание системы управленческого учета.
- III. Филогенез эндокринной системы.
- IV. Движение поездов при неисправности электрожезловой системы и порядок регулировки количества жезлов в жезловых аппаратах
- L.3. Состояние российской системы образования и необходимость ее

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
