Разброс данных вокруг среднего
Разброс полученных данных в положительную и отрицательную сторону от средней величины обозначается буквой d, а вычисляется через отклонение каждого значения от средней ( 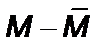 ), затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Если эта средняя невелика, то это свидетельствует в пользу того, что данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
), затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Если эта средняя невелика, то это свидетельствует в пользу того, что данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
Вычисление среднего отклонения проводится следующим образом. Собрав все данные и расположив их в ряд– 3, 5, 6, 9, 11, 14,– находят среднюю арифметическую выборки:
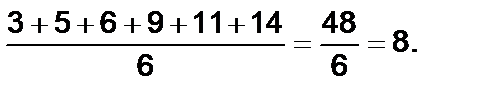
Затем вычисляют отклонения каждого значения от средней и суммируют их:
-5 -3 -2 +1 +3 +6
(3-8) + (5-8) + (6-8) + (9-8) + (11-8) + (14-8).
Но во избежание взаимоуничтожения положительных и отрицательных значений в процессе суммирования общепринято прежде возводить все значения в квадрат, а затем делить всю сумму квадратов на число данных. В нашем примере это выглядит следующим образом:
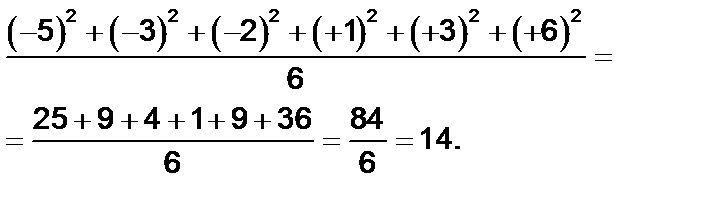
В результате такого расчета получают так называемую дисперсию. Формула для вычисления дисперсии, таким образом, следующая:
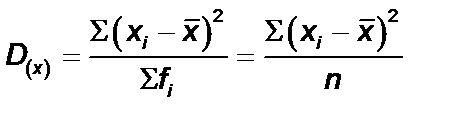 .
.
После этого из дисперсии извлекается квадратный корень. При этом получается так называемое стандартное отклонение:
Стандартное отклонение = 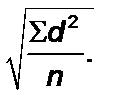
В данном примере стандартное отклонение равно 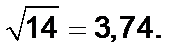
Следует еще добавить, что для того, чтобы более точно оценить стандартное отклонение для малых выборок (с числом элементов менее 30), в знаменателе выражения под корнем надо использовать не n, а n –1. Стандартное отклонение обозначается греческой буквой s (сигма):
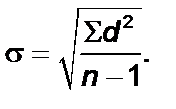
Стандартное отклонение показывает, насколько далеко от средней разбросаны результаты в положительную и отрицательную стороны. Укладывается ли этот разброс результатов в стандартное отклонение, которое равно 68% популяции.
Итак, описательная статистика необходима для представления графической и количественной оценки степени разброса данных в том или ином распределении.
Дата добавления: 2021-06-28; просмотров: 559;
Поиск по сайту
Узнать еще
- STEP – стандарт для описания данных об изделии
- АВТОМАТИЗИРОВАННАЯ ОБРАБОТКА ДАННЫХ В СЛУЖБЕ ПРИЕМА И РАЗМЕЩЕНИЯ
- Автоматизированная система технической паспортизации (АСПАД) и создание автоматизированного банка дорожных данных (АБДЦ).
- Автоматизированная система технической паспортизации дорог и создание банка дорожных данных
- АВТОМАТИЗИРОВАННЫЕ БАНКИ ДАННЫХ, ИНФОРМАЦИОННЫЕ БАЗЫ, ИХ ОСОБЕННОСТИ
- Автоматизированные банки дорожных данных.
- Адресация и протоколы данных в сети Интернет.
- Активное сопротивление трубы 1 среднего рукава

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
