Методы нулевого порядка
Сеточный метод. Сеточный метод предусматривает дискретизацию допустимого множества задачи с помощью сетки, в узлах которой вычисляются значения целевой функции и среди них выбирается минимальное. Если целевая функция удовлетворяет условию Липшица, то его использование в ряде случаев помогает отбросить неперспективные области значений аргумента 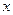 . Для функции
. Для функции 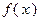 одной переменной условие Липшица имеет вид:
одной переменной условие Липшица имеет вид:
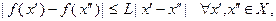 (3.5.3)
(3.5.3)
где 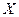 – допустимое множество задачи (3.5.1) или задачи (3.5.2). Из (3.5.3) следует:
– допустимое множество задачи (3.5.1) или задачи (3.5.2). Из (3.5.3) следует:
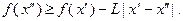 (3.5.4)
(3.5.4)
Это означает, что график целевой функции расположен над ломаной 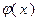 , уравнение которой определяется правой частью неравенства (3.5.4):
, уравнение которой определяется правой частью неравенства (3.5.4):
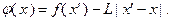 (3.5.5)
(3.5.5)
Если при некотором значении 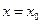 выполнено неравенство
выполнено неравенство 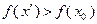 , то из дальнейшего рассмотрения исключается интервал значений аргумента
, то из дальнейшего рассмотрения исключается интервал значений аргумента 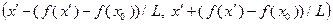 , так как он является решением неравенства
, так как он является решением неравенства  , где определяется выражением (3.5.5).
, где определяется выражением (3.5.5).
Метод покоординатного спуска. Сначала рассмотрим этот метод применительно к решению задачи (3.5.2). Пусть 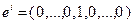 – единичный координатный вектор, у которого
– единичный координатный вектор, у которого  -я координата равна
-я координата равна 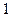 , остальные равны нулю
, остальные равны нулю 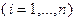 . Обозначим через
. Обозначим через 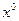 некоторое начальное приближение и через
некоторое начальное приближение и через 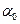 некоторое положительное число, являющееся параметром метода. Допустим, что нам уже известны точка
некоторое положительное число, являющееся параметром метода. Допустим, что нам уже известны точка 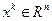 и число
и число 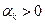 при каком-либо
при каком-либо 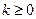 . Положим
. Положим
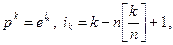 (3.5.6)
(3.5.6)
где 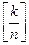 – целая часть числа
– целая часть числа 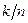 . Соотношения (3.5.6) отражают циклический перебор координатных векторов
. Соотношения (3.5.6) отражают циклический перебор координатных векторов 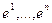 и, таким образом,
и, таким образом, 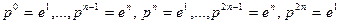 и т.д. Вычислим значение функции в точке
и т.д. Вычислим значение функции в точке 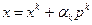 и проверим неравенство
и проверим неравенство
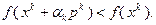 (3.5.7)
(3.5.7)
Если (3.5.7) выполняется, то примем
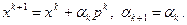 (3.5.8)
(3.5.8)
В том случае, если (3.5.7) не выполняется, вычисляем значение функции в точке 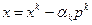 и проверяем неравенство
и проверяем неравенство
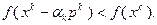 (3.5.9)
(3.5.9)
В случае выполнения (3.5.9) положим
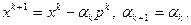 (3.5.10)
(3.5.10)
Назовем 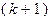 -ю итерацию удачной, если справедливо хотя бы одно из неравенств (3.5.7) или (3.5.9). Если -я итерация неудачная, т.е. не выполняются оба неравенства (3.5.7) и (3.5.9), то полагаем
-ю итерацию удачной, если справедливо хотя бы одно из неравенств (3.5.7) или (3.5.9). Если -я итерация неудачная, т.е. не выполняются оба неравенства (3.5.7) и (3.5.9), то полагаем
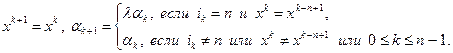 (3.5.11)
(3.5.11)
Здесь 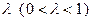 – фиксированное число, являющееся параметром метода. Условия (3.5.11) означают, что если за один цикл из
– фиксированное число, являющееся параметром метода. Условия (3.5.11) означают, что если за один цикл из 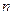 итераций при переборе направлений всех координатных осей с шагом
итераций при переборе направлений всех координатных осей с шагом 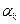 реализовалась хотя бы одна удачная итерация, то длина шага не дробится и сохраняется на протяжении по крайней мере следующего цикла из итераций. Если же среди последних итераций не оказалось ни одной удачной итерации, то шаг дробится. Таким образом, если на итерации с номером
реализовалась хотя бы одна удачная итерация, то длина шага не дробится и сохраняется на протяжении по крайней мере следующего цикла из итераций. Если же среди последних итераций не оказалось ни одной удачной итерации, то шаг дробится. Таким образом, если на итерации с номером 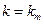 произошло дробление , то
произошло дробление , то
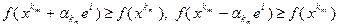 (3.5.12)
(3.5.12)
при всех 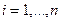 .
.
Метод (3.5.6) – (3.5.11), как и другие методы нулевого порядка, не требует для своей реализации знания градиента минимизируемой функции. Однако если функция не является гладкой, то, как показано в [1], метод покоординатного спуска может не сходиться к множеству решений задачи (3.5.2). Проиллюстрируем это следующим примером.
Пример 3.5.1
Пусть в задаче (3.5.2) 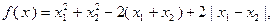
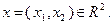
Нетрудно проверить, что данная функция сильно выпукла на 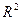 и, следовательно, достигает своего минимального значения на в единственной точке. Возьмем в качестве начального приближения точку
и, следовательно, достигает своего минимального значения на в единственной точке. Возьмем в качестве начального приближения точку 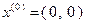 . Тогда
. Тогда 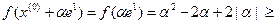
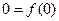 ,
, 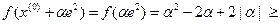
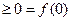 при всех действительных
при всех действительных 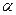 . Отсюда следует, что все итерации метода (3.5.6) – (3.5.11) при начальной точке и любом выборе начального параметра
. Отсюда следует, что все итерации метода (3.5.6) – (3.5.11) при начальной точке и любом выборе начального параметра 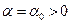 будут неудачными, т.е.
будут неудачными, т.е. 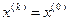 при всех
при всех 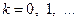 Однако в точке функция не достигает своего минимального значения на : например, при
Однако в точке функция не достигает своего минимального значения на : например, при 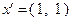 получим
получим 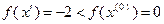 .
.
Рассмотренный метод покоординатного спуска может быть модифицирован применительно к задаче (3.5.1). Пусть – допустимое множество этой задачи:
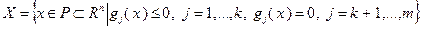
Предположим, что 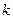 -е приближение
-е приближение 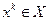 и число при некотором
и число при некотором 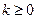 уже найдены. Выберем вектор
уже найдены. Выберем вектор 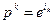 согласно (3.5.6), сформируем точку
согласно (3.5.6), сформируем точку 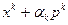 и проверим условия
и проверим условия
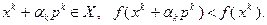 (3.5.13)
(3.5.13)
Если оба условия (3.5.13) выполняются, то следующее приближение 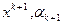 определяем по формулам (3.5.8). Если же хотя бы одно из условий (3.5.13) не выполнено, то формируем точку
определяем по формулам (3.5.8). Если же хотя бы одно из условий (3.5.13) не выполнено, то формируем точку 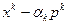 и проверяем условия
и проверяем условия
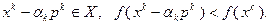 (3.5.14)
(3.5.14)
В случае выполнения условий (3.5.14) следующее приближение находим по формулам (3.5.10), а если хотя бы одно из условий (3.5.14) не выполнено, то следующее приближение определяется из соотношений (3.5.11). В [1] показано, что если является -мерным параллелепипедом, а функция выпукла и непрерывно дифференцируема на , то при любом выборе начальных 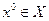 и
и 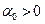 последовательность
последовательность 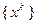 , получаемая методом (3.5.13), (3.5.8), (3.5.14), (3.5.10), (3.5.11), минимизирует функцию на и сходится к множеству решений экстремальной задачи.
, получаемая методом (3.5.13), (3.5.8), (3.5.14), (3.5.10), (3.5.11), минимизирует функцию на и сходится к множеству решений экстремальной задачи.
Известны и другие варианты метода покоординатного спуска. Например, последовательность может быть построена по правилу
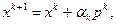 (3.5.15)
(3.5.15)
где 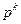 определяется согласно (3.5.6), а – условиями
определяется согласно (3.5.6), а – условиями
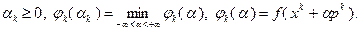 (3.5.16)
(3.5.16)
Метод (3.5.15), (3.5.16) имеет смысл применять тогда, когда величина из (3.5.16) может быть найдена в явном виде. Это будет иметь место, например, в случае, если целевая функция – квадратичная, т.е.
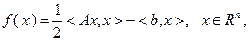 (3.5.17)
(3.5.17)
где 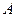 – симметрическая положительно определенная матрица,
– симметрическая положительно определенная матрица, 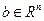 . Для функции (3.5.17) метод (3.5.15), (3.5.16) приводит к методу Зейделя решения систем линейных уравнений.
. Для функции (3.5.17) метод (3.5.15), (3.5.16) приводит к методу Зейделя решения систем линейных уравнений.
Несмотря на то, что скорость сходимости метода покоординатного спуска в общем случае невысокая, благодаря простоте каждой итерации и не слишком жестким требованиям к гладкости минимизируемой функции этот метод весьма широко применяется на практике.
Метод случайного поиска. Метод случайного поиска характеризуется намеренным введением элемента случайности в алгоритм поиска. Во многих вариантах реализации метода последовательность строится по правилу:
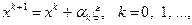 (3.5.18)
(3.5.18)
где – некоторая положительная величина, 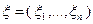 – какая-либо реализация -мерной случайной величины
– какая-либо реализация -мерной случайной величины 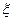 с известным законом распределения вероятностей. Например, координаты случайного вектора могут представлять собой независимые случайные величины, распределенные равномерно на отрезке
с известным законом распределения вероятностей. Например, координаты случайного вектора могут представлять собой независимые случайные величины, распределенные равномерно на отрезке 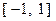 . Очевидно, что компьютерная реализация данного метода требует использования датчика (или генератора) случайных чисел, имеющегося в стандартном программном обеспечении.
. Очевидно, что компьютерная реализация данного метода требует использования датчика (или генератора) случайных чисел, имеющегося в стандартном программном обеспечении.
Рассмотрим несколько вариантов реализации метода случайного поиска минимума функции на множестве 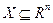 , предполагая, что -е приближение
, предполагая, что -е приближение 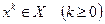 уже известно.
уже известно.
Алгоритм с возвратом при неудачном шаге. С помощью датчика случайных чисел получают некоторую реализацию случайного вектора и в пространстве 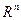 определяют точку
определяют точку 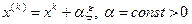 . Если
. Если 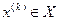 и
и 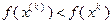 , то сделанный шаг считается удачным, и в этом случае полагается
, то сделанный шаг считается удачным, и в этом случае полагается 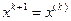 . Если , но
. Если , но 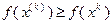 , или же
, или же 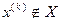 , то сделанный шаг считается неудачным и полагается
, то сделанный шаг считается неудачным и полагается 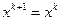 .
.
В том случае, если окажется, что 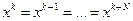 для достаточно больших
для достаточно больших 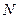 , то точка
, то точка 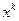 может быть принята в качестве приближения искомой точки минимума.
может быть принята в качестве приближения искомой точки минимума.
Алгоритм наилучшей пробы. Формируются какие-либо 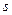 реализаций
реализаций 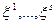 случайного вектора и вычисляются значения целевой функции в тех точках
случайного вектора и вычисляются значения целевой функции в тех точках 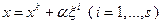 , которые принадлежат множеству . Затем полагается
, которые принадлежат множеству . Затем полагается 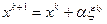 , где индекс
, где индекс 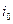 определяется условием
определяется условием
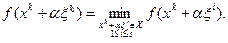
Здесь 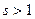 и
и 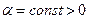 являются параметрами алгоритма.
являются параметрами алгоритма.
Алгоритм статистического градиента. Генерируются реализаций случайного вектора и вычисляются разности 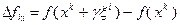 для всех
для всех 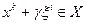 . Затем находят вектор
. Затем находят вектор 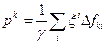 , где сумма берется по всем тем
, где сумма берется по всем тем 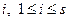 , для которых . Если
, для которых . Если 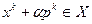 , то принимается
, то принимается 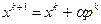 . Если же
. Если же 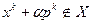 , то повторяют описанный процесс с новым набором из реализаций случайного вектора . Величины
, то повторяют описанный процесс с новым набором из реализаций случайного вектора . Величины 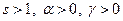 являются параметрами алгоритма. Вектор называется статистическим градиентом. Если
являются параметрами алгоритма. Вектор называется статистическим градиентом. Если 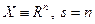 и векторы
и векторы 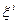 являются неслучайными и совпадают с соответствующими единичными векторами
являются неслучайными и совпадают с соответствующими единичными векторами 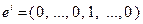
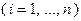 , то описанный алгоритм превращается в разностный аналог градиентного метода.
, то описанный алгоритм превращается в разностный аналог градиентного метода.
В рассмотренных вариантах метода случайного поиска закон распределения вероятностей случайного вектора предполагался не зависящим от номера итерации. Такой поиск называют случайным поиском без обучения. В алгоритмах, реализующих случайный поиск без обучения, отсутствуют анализ результатов выполненных итераций и определение перспективных направлений продолжения поиска точки минимума, в силу чего скорость сходимости в общем случае оказывается невысокой. Однако если на каждой очередной итерации учитывать накопленный опыт поиска минимума на предыдущих итерациях и перестраивать вероятностные свойства поиска так, чтобы направления , более перспективные в смысле убывания функции, становились более вероятными, то от метода случайного поиска можно ожидать большей эффективности. Таким образом, желательно иметь алгоритмы случайного поиска, обладающие способностью к самообучению и самоусовершенствованию в процессе поиска минимума в зависимости от конкретных особенностей минимизируемой функции. Такой поиск называют случайным поиском с обучением. Обучение осуществляется путем целенаправленного изменения закона распределения вероятностей случайного вектора в зависимости от номера итерации и результатов предыдущих итераций таким образом, чтобы перспективные направления поиска сделать более вероятными, а другие направления – соответственно менее вероятными. Поскольку на различных этапах метода случайного поиска с обучением используются реализации случайных векторов с различными законами распределения вероятностей, итерационный процесс (3.5.18) удобнее записать в виде, учитывающем зависимость случайного вектора от :
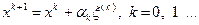 (3.5.19)
(3.5.19)
В начале поиска закон распределения случайного вектора 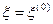 выбирают с учетом имеющейся априорной информации о минимизируемой функции . Если такая информация отсутствует, то поиск обычно начинают со случайного вектора
выбирают с учетом имеющейся априорной информации о минимизируемой функции . Если такая информация отсутствует, то поиск обычно начинают со случайного вектора 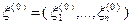 , компоненты которого являются независимыми случайными величинами, распределенными равномерно на отрезке .
, компоненты которого являются независимыми случайными величинами, распределенными равномерно на отрезке .
Для обучения алгоритма в процессе поиска часто используют семейство случайных векторов 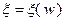 , зависящих от параметров
, зависящих от параметров 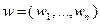 , и при переходе от -й итерации к -й итерации имеющиеся значения параметров
, и при переходе от -й итерации к -й итерации имеющиеся значения параметров 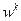 заменяют новыми значениями
заменяют новыми значениями 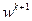 с учетом результатов предыдущего поиска.
с учетом результатов предыдущего поиска.
Рассмотрим два варианта метода случайного поиска с обучением для минимизации функции на всем пространстве .
Алгоритм покоординатного обучения. Пусть имеется семейство случайных векторов 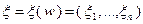 , каждая координата
, каждая координата 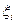 которых принимает два значения:
которых принимает два значения: 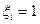 с вероятностью
с вероятностью 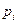 и
и 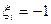 с вероятностью
с вероятностью 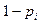 , где вероятность зависит от параметра
, где вероятность зависит от параметра 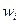 следующим образом:
следующим образом:
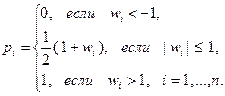 (3.5.20)
(3.5.20)
Пусть начальное приближение уже выбрано. Тогда для определения следующего приближения 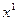 в формуле (3.5.19) при
в формуле (3.5.19) при 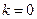 используется какая-либо реализация случайного вектора
используется какая-либо реализация случайного вектора 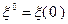 , соответствующего набору значений параметров
, соответствующего набору значений параметров 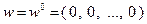 . Приближение
. Приближение 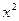 определяется по формуле (3.5.19) при
определяется по формуле (3.5.19) при 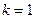 с помощью случайного вектора
с помощью случайного вектора 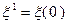 . Допустим, что известны приближения
. Допустим, что известны приближения 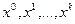 и значения параметров
и значения параметров 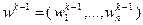 при некотором
при некотором 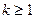 . Тогда полагаем
. Тогда полагаем
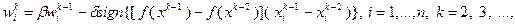 (3.5.21)
(3.5.21)
где величина 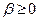 называется параметром забывания,
называется параметром забывания, 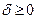 – параметром интенсивности обучения,
– параметром интенсивности обучения, 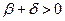 . При определении следующего приближения
. При определении следующего приближения 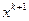 в формуле (3.5.19) используем реализацию случайного вектора
в формуле (3.5.19) используем реализацию случайного вектора 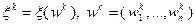 .
.
Из (3.5.20), (3.5.21) видно, что если переход от точки 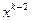 к
к 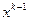 привел к уменьшению значения функции, то вероятность выбора направления
привел к уменьшению значения функции, то вероятность выбора направления 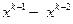 на следующем шаге увеличивается. Если же при переходе от к значение функции увеличилось, то вероятность выбора направления на последующем шаге уменьшается. Таким образом, посредством формул (3.5.21) осуществляется обучение алгоритма. Величина в (3.5.21) регулирует скорость обучения: чем больше
на следующем шаге увеличивается. Если же при переходе от к значение функции увеличилось, то вероятность выбора направления на последующем шаге уменьшается. Таким образом, посредством формул (3.5.21) осуществляется обучение алгоритма. Величина в (3.5.21) регулирует скорость обучения: чем больше 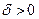 , тем быстрее обучается алгоритм; при
, тем быстрее обучается алгоритм; при 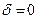 обучение отсутствует. Величина в (3.5.21) регулирует влияние предыдущих значений параметров на обучение алгоритма; при
обучение отсутствует. Величина в (3.5.21) регулирует влияние предыдущих значений параметров на обучение алгоритма; при 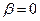 алгоритм «забывает» предыдущие значения
алгоритм «забывает» предыдущие значения 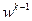 . Для устранения возможного чрезмерного детерминирования алгоритма и сохранения его способности к достаточно быстрому обучению на параметры
. Для устранения возможного чрезмерного детерминирования алгоритма и сохранения его способности к достаточно быстрому обучению на параметры 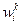 накладываются ограничения
накладываются ограничения 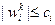 и при нарушении этих ограничений заменяются ближайшим из чисел
и при нарушении этих ограничений заменяются ближайшим из чисел 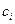 и
и 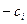 ,
, 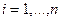 . Величины
. Величины 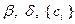 являются параметрами алгоритма.
являются параметрами алгоритма.
Вместо формул (3.5.21) часто пользуются формулами
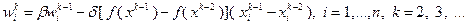 (3.5.22)
(3.5.22)
Рассмотренный алгоритм покоординатного обучения имеет недостаток, состоящий в том, что поиск и обучение происходят лишь по одному из 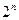 направлений , где либо , либо
направлений , где либо , либо 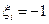 . Отсутствие «промежуточных» направлений делает покоординатное обучение немобильным в областях с медленно изменяющимися направлениями спуска. От этого недостатка свободен следующий алгоритм.
. Отсутствие «промежуточных» направлений делает покоординатное обучение немобильным в областях с медленно изменяющимися направлениями спуска. От этого недостатка свободен следующий алгоритм.
Алгоритм непрерывного самообучения. Пусть имеется семейство случайных векторов 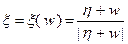 , где – параметры обучения,
, где – параметры обучения, 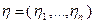 – случайный вектор, координаты
– случайный вектор, координаты 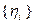 которого являются независимыми случайными величинами, распределенными равномерно на отрезке . Поиск начинается с рассмотрения случайных векторов
которого являются независимыми случайными величинами, распределенными равномерно на отрезке . Поиск начинается с рассмотрения случайных векторов 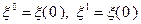 , реализации которых используются при определении приближений
, реализации которых используются при определении приближений 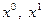 по формулам (3.5.19). Обучение алгоритма при
по формулам (3.5.19). Обучение алгоритма при 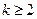 производится так же, как в алгоритме покоординатного обучения, с помощью формул (3.5.21) или (3.5.22). При больших значениях
производится так же, как в алгоритме покоординатного обучения, с помощью формул (3.5.21) или (3.5.22). При больших значениях 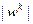 влияние случайной величины
влияние случайной величины 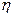 уменьшается, и направление
уменьшается, и направление 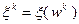 становится более детерминированным и близким к направлению . Во избежание излишней детерминированности метода на параметры
становится более детерминированным и близким к направлению . Во избежание излишней детерминированности метода на параметры 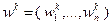 накладывают ограничения
накладывают ограничения 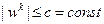 , и при нарушении этих ограничений заменяется на
, и при нарушении этих ограничений заменяется на 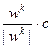 . Рассмотренный алгоритм, также как и алгоритм покоординатного обучения, характеризуется уменьшением фактора случайности и увеличением степени детерминированности в ходе поиска минимума, следуя преимущественно направлению убывания функции. В то же время наличие случайного фактора в выборе направления дает возможность придать алгоритму большую гибкость, особенно в тех случаях, когда свойства целевой функции в районе поиска изменились или предыдущее обучение оказалось недостаточно точным.
. Рассмотренный алгоритм, также как и алгоритм покоординатного обучения, характеризуется уменьшением фактора случайности и увеличением степени детерминированности в ходе поиска минимума, следуя преимущественно направлению убывания функции. В то же время наличие случайного фактора в выборе направления дает возможность придать алгоритму большую гибкость, особенно в тех случаях, когда свойства целевой функции в районе поиска изменились или предыдущее обучение оказалось недостаточно точным.
Дата добавления: 2021-05-28; просмотров: 588;
Поиск по сайту
Узнать еще
- I. Гидрометаллургические методы
- I. Погрешности механической обработки. Точность обработки. Методы их расчёта
- II. Методы исследования истории медицины.
- II. Пирометаллургические методы.
- II. Шкала порядка (шкала рангов)
- II.II. Репродуктивные методы.
- II.III. Частично - поисковые или эвристические методы.
- II.V. Проблемные методы обучения.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
