Архитектура ЦП Pentium
Эволюция центральных процессоров Intel – от первого 16-разрядного Intel 8086 до Pentium IV – составила значительное число шагов. Основные вехи этой эволюции отражены в табл. 3.1. Первой существенной вехой явилось расширение разрядности внутренних регистров ЦП с 16 до 32 и увеличение адресного пространства до 4 Гбайт при переходе к ЦП Intel 80386. Немаловажным явилось событие в размещении на одном кристалле ЦП и АП, а также появление внутренней кэш-памяти у ЦП Intel 80486.
Кэш первого уровня процессора Intel 80486 имеет четырехканальную структуру (рис. 3.1). Каждый канал состоит из 128 строк по 16 байт в каждой. Одноименные строки всех четырех каналов образуют 128 наборов из четырех строк, каждый из которых обслуживает свои адреса памяти. Каждой строке соответствует 21-разрядная информация об адресе скопированного в нее блока системной памяти. Эта информация называется тегом (tag) строки.
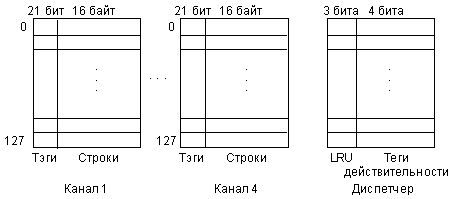
Рис. 3.1. Структура внутреннего кэша ЦП Intel 80486
Кроме того, в состав кэша входит так называемый диспетчер, то есть область памяти с организацией 128 х 7, в которой хранятся 4-битные теги действительности (достоверности) для каждого из 128 наборов и 3-битные коды LRU (Least Recently Used) для каждого из 128 наборов. Тег действительности набора включает в себя 4 бита достоверности каждой из 4 строк, входящих в данный набор. Бит достоверности, установленный в единицу, говорит о том, что соответствующая строка заполнена; если он сброшен в нуль, то строка пуста. Биты LRU говорят о том, как давно было обращение к данному набору. Это нужно для того, чтобы обновлять наименее используемые наборы.
Адресация кэш-памяти осуществляется с помощью 28 разрядов адреса. Из них 7 младших разрядов выбирают один из 128 наборов, а 21 старший разряд сравнивается с тегами всех 4 строк выбранного набора. Если теги совпадают с разрядами адреса, то получается ситуация кэш-попадания, а если нет, то ситуация кэш-промаха.
В случае цикла чтения при кэш-попадании байт или слово читаются из кэш-памяти. При кэш-промахе происходит обновление (перезагрузка) одной из строк кэш-памяти. В случае цикла записи при кэш-попадании производится запись как в кэш-память, так и в основную системную память. При кэш-промахе запись производится только в системную память, а обновление строки кэш-памяти не производится. Эта строка становится недостоверной (ее бит достоверности сбрасывается в нуль).
Такая политика записи называется сквозной или прямой записью (Write Through). В более поздних моделях процессоров применяется и обратная запись(Write Back), которая является более быстрой, так как требует гораздо меньшего числа обращений по внешней шине. При использовании обратной записи в основную память записываемая информация отправляется только в том случае, когда нужной строки в кэше нет. В случае же попадания модифицируется только кэш. В основную память измененная информация попадет только при перезаписи новой строки в кэш. Прежняя строка при этом целиком переписывается в основную память, и тем самым восстанавливается идентичность содержимого кэша и основной памяти.
В случае, когда требуемая строка в кэше не представлена (ситуация кэш-промаха), запрос на запись направляется на внешнюю шину, а запрос на чтение обрабатывается несколько сложнее. Если этот запрос относится к кэшируемой области памяти, то выполняется цикл заполнения целой строки кэша (16 байт из памяти переписывается в одну из строк набора, обслуживающего данный адрес). Если затребованные данные не укладываются в одной строке, то заполняется и соседняя строка.
Внутренний запрос процессора на данные удовлетворяется сразу, как только данные считываются из памяти, а дальнейшее заполнение строки может идти параллельно с обработкой данных. Если в наборе, который обслуживает данный адрес памяти, имеется свободная строка, заполнена будет именно она. Если же свободных строк нет, заполняется строка, к которой дольше всех не обращались. Для этого используются биты LRU, которые модифицируются при каждом обращении к строке данного набора. Кроме того, существует возможность аннулирования строк (объявления их недостоверными) и очистки всей кэш-памяти. При сквозной записи очистка кэша проводится специальным внешним сигналом процессора, программным образом с помощью специальных команд, а также при начальном сбросе – по сигналу RESET. При обратной записи очистка кэша подразумевает также выгрузку всех модифицированных строк в основную память.
Появление процессора Pentium MMX (Multi Media Extension), существенно расширило систему команд ЦП, введением специальных команд для нужд мультимедийных приложений. Этот процессор положил начало новой технологии обработки данных – SIMD (Single Instruction Multiply Data), при которой одна команда обрабатывает параллельно несколько данных.
Выпуск процессора Pentium III, также добавил большое число новых команд для потоковой обработки чисел с плавающей запятой. Эта новация носит название SSE (Streaming SIMD Extention) – потоковое SIMD расширение.
Наконец, большие успехи в технологии изготовления кристаллов микросхем позволили практически на порядок повысить их сложность, благодаря чему появился процессор Pentium IV, обладающей внутренней двухуровневой КЭШ памятью и достигшему в настоящее время огромного быстродействия, превышающего 3 ГГц.
Таблица 3.1
| Модель | Год | Млн. тр-ров | Ч-та (Мгц) | Регистры (бит) | ШД (бит) | Адреса (Гбайт) | КЭШ (Кбайт) |
| Intel 8086 | 0.029 | 0.001 | Нет | ||||
| Intel 386 | 0.275 | Нет | |||||
| Intel 486 | 1.2 | 8 + 8 | |||||
| Pentium | 3.1 | 8 + 8 | |||||
| Pentium Pro | 5.5 | 8 + 8 | |||||
| Pentium MMX | 1997, янв | 6.5 | 32 / 64 | 8 + 8 | |||
| Pentium II (Xeon) | 1997, май | 7.5 | 32 / 64 | 16 + 16 | |||
| Celeron | 7.5 | 32 / 64 | |||||
| Pentium III | 8.5 | 32 / 64 / 128 | 16 + 16 | ||||
| Pentium IV | 42.0 | 32 / 64 / 128 | 256 / 12 / 8 |
Совокупность технических решений, применённых в процессоре Pentium IV, получила собственное название: «архитектура NetBurst (пакетно-сетевая)». Архитектура процессора Pentuim IV представлена на рис. 3.2.
Дата добавления: 2018-11-26; просмотров: 1153;
Поиск по сайту
Узнать еще
- III. Архитектура Древнего Египта
- Архитектура OLAP-приложений
- АРХИТЕКТУРА «КЛИЕНТ - СЕРВЕР» АВТОМАТИЗИРОВАННОЙ ИНФОРМАЦИОННОЙ ТЕХНОЛОГИИ КАЗНАЧЕЙСТВА
- Архитектура античного мира
- Архитектура арифметического процессора
- Архитектура архаического периода.
- Архитектура Балканских и Придунайских стран VII-XV в.в.
- АРХИТЕКТУРА БАРОККО ХАРАКТЕРНЫЕ ЧЕРТЫ АРХИТЕКТУРЫ БАРОККО

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
