Реализация понятия последовательного процесса в ОС
Для того чтобы операционная система могла управлять процессами, она должна располагать всей необходимой для этого информацией. С этой целью на каждый процесс заводится специальная информационная структура, называемая дескриптором процесса (описателем задачи, блоком управления задачей). В общем случае дескриптор процесса содержит следующую информацию:
¨ идентификатор процесса (так называемый PID – process identificator);
¨ тип (или класс) процесса, который определяет для супервизора некоторые правила предоставления ресурсов;
¨ приоритет процесса, в соответствии с которым супервизор предоставляет ресурсы. В рамках одного класса процессов в первую очередь обслуживаются более приоритетные процессы;
¨ переменную состояния, которая определяет, в каком состоянии находится процесс (готов к работе, в состоянии выполнения, ожидание устройства ввода/вывода и т. д.);
¨ защищённую область памяти (или адрес такой зоны), в которой хранятся текущие значения регистров процессора, если процесс прерывается, не закончив работы. Эта информация называется контекстом задачи;
¨информацию о ресурсах, которыми процесс владеет и/или имеет право пользоваться (указатели на открытые файлы, информация о незавершенных операциях ввода/вывода и т. п.);
¨ место (или его адрес) для организации общения с другими процессами;
¨ параметры времени запуска (момент времени, когда процесс должен активизироваться, и периодичность этой процедуры);
¨ в случае отсутствия системы управления файлами – адрес задачи на диске в её исходном состоянии и адрес на диске, куда она выгружается из оперативной памяти, если её вытесняет другая (для диск-резидентных задач, которые постоянно находятся во внешней памяти на системном магнитном диске и загружаются в оперативную память только на время выполнения).
Описатели задач, как правило, постоянно располагаются в оперативной памяти с целью ускорить работу супервизора, который организует их в списки (очереди) и отображает изменение состояния процесса перемещением соответствующего описателя из одного списка в другой. Для каждого состояния (за исключением состояния выполнения для однопроцессорной системы) операционная система ведет соответствующий список задач, находящихся в этом состоянии. Однако для состояния ожидания может быть не один список, а столько, сколько различных видов ресурсов могут вызывать состояние ожидания. Например, состояний ожидания завершения операции ввода/вывода может быть столько, сколько устройств ввода/вывода имеется в системе.
В некоторых операционных системах количество описателей определяется жестко и заранее (на этапе генерации варианта операционной системы или в конфигурационном файле, который используется при загрузке ОС), в других – по мере необходимости система может выделять участки памяти под новые описатели. Например, в OS/2 максимально возможное количество описателей задач определяется в конфигурационном файле CONFIG.SYS, а в Windows NT оно в явном виде не задается. Справедливости ради стоит заметить, что в упомянутом файле указывается количество не процессов, а именно задач, и под задачей в данном случае понимается как процесс, так и поток этого же процесса, называемый потоком или тредом (см. следующий раздел). Например, строка в файле CONFIG.SYS
THREADS=1024
указывает» что всего в системе может параллельно существовать и выполняться до 1024 задач, включая вычислительные процессы и их потоки.
В ОС реального времени чаще всего количество процессов фиксируется и, следовательно, целесообразно заранее определять (на этапе генерации или конфигурирования ОС) количество дескрипторов. Для использования таких ОС в качестве систем общего назначения (что сейчас встречается редко, а в недалеком прошлом достаточно часто в качестве вычислительных систем общего назначения приобретали мини-ЭВМ и устанавливали на них ОС реального времени) обычно количество дескрипторов берется с некоторым запасом, и появление новой задачи связывается с заполнением этой информационной структуры. Поскольку дескрипторы процессов постоянно располагаются в оперативной памяти (с целью ускорить работу диспетчера), то их количество не должно быть очень большим. При необходимости иметь большое количество задач один и тот же дескриптор может в разное время предоставляться для разных задач, но это сильно снижает скорость реагирования системы.
Для более эффективной обработки данных в системах реального времени целесообразно иметь постоянные задачи/полностью или частично всегда существующие в системе независимо от того, поступило на них требование или нет. Каждая постоянная задача обладает некоторой собственной областью оперативной памяти (ОЗУ-резидентные задачи) независимо от того, выполняется задача в данный момент или нет. Эта область, в частности, может использоваться для хранения данных, полученных задачей ранее. Данные могут храниться в ней и тогда, когда задача находится в состоянии ожидания или даже в состоянии бездействия.
Для аппаратной поддержки работы операционных систем с этими информационными структурами (дескрипторами задач) в процессорах могут быть реализованы соответствующие механизмы. Так, например, в микропроцессорах Intel 80х86 (см. главу 3 «Особенности архитектуры микропроцессоров 180х86 для организации мультипрограммных операционных систем»), начиная с 80286, имеется специальный регистр TR (task register), указывающий местонахождение TSS (сегмента состояния задачи1, см. раздел «Новые системные регистры микропроцессоров i80x86», глава 3), в котором при переключении с задачи на задачу автоматически сохраняется содержимое регистров процессора [2, 22, 84]. Как правило, в современных ОС для этих микропроцессоров дескриптор задачи включает в себя TSS. Другими словами, дескриптор задачи больше по размеру, чем TSS, и включает в себя такие традиционные поля, как идентификатор задачи, её имя, тип, приоритет и т. п.
Процессы и треды
Понятие процесса было введено для реализации идей мультипрограммирования. Напомним, в свое время различали термины «мультизадачность» и «мультипрограммирование». Таким образом, для реализации «мультизадачности» в её исходном толковании необходимо было тоже ввести соответствующую сущность. Такой сущностью и стали так называемые «легковесные» процессы, или, как их теперь преимущественно называют, – потоки или треды (нити)2. Рассмотрим эти понятия подробнее.
Когда говорят о процессах (process), то тем самым хотят отметить, что операционная система поддерживает их обособленность: у каждого процесса имеется свое виртуальное адресное пространство, каждому процессу назначаются свои ресурсы – файлы, окна, семафоры и т. д. Такая обособленность нужна для того, чтобы защитить один процесс от другого, поскольку они, совместно используя все ресурсы вычислительной системы, конкурируют друг с другом. В общем случае процессы просто никак не связаны между собой и могут принадлежать даже разным пользователям, разделяющим одну вычислительную систему. Другими словами, в случае процессов ОС считает их совершенно несвязанными и независимыми. При этом именно ОС берет на себя роль арбитра в конкуренции между процессами по поводу ресурсов.
Однако желательно иметь ещё и возможность задействовать внутренний параллелизм, который может быть в самих процессах. Такой внутренний параллелизм встречается достаточно часто и его использование позволяет ускорить их решение. Например, некоторые операции, выполняемые приложением, могут требовать для своего исполнения достаточно длительного использования центрального процессора. В этом случае при интерактивной работе с приложением пользователь вынужден долго ожидать завершения заказанной операции и не может управлять приложением до тех пор, пока операция не выполнится до самого конца. Такие ситуации встречаются достаточно часто, например, при обработке больших изображений в графических редакторах. Если же программные модули, исполняющие такие длительные операции, оформлять в виде самостоятельных «подпроцессов» (легковесных или облегченных процессов – потоков, можно также воспользоваться термином задача), которые будут выполняться параллельно с другими «подпроцессами» (потоками, задачами), то у пользователя появляется возможность параллельно выполнять несколько операций в рамках одного приложения (процесса). Легковесными эти задачи называют потому, что операционная система не должна для них организовывать полноценную виртуальную машину. Эти задачи не имеют своих собственных ресурсов, они развиваются в том же виртуальном адресном пространстве, могут пользоваться теми же файлами, виртуальными устройствами и иными ресурсами, что и данный процесс. Единственное, что им необходимо иметь, – это процессорный ресурс. В однопроцессорной системе треды (задачи) разделяют между собой процессорное время так же, как это делают обычные процессы, а в мультипроцессорной системе могут выполняться одновременно, если не встречают конкуренции из-за обращения к иным ресурсам.
Главное, что обеспечивает многопоточность, – это возможность параллельно выполнять несколько видов операций в одной прикладной программе. Параллельные вычисления (а, следовательно, и более эффективное использование ресурсов центрального процессора, и меньшее суммарное время выполнения задач) теперь уже часто реализуется на уровне тредов, и программа, оформленная в виде нескольких тредов в рамках одного процесса, может быть выполнена быстрее за счёт параллельного выполнения её отдельных частей. Например, если электронная таблица или текстовый процессор были разработаны с учётом возможностей многопоточной обработки, то пользователь может запросить пересчёт своего рабочего листа или слияние нескольких документов и одновременно продолжать заполнять таблицу или открывать для редактирования следующий документ.
Особенно эффективно можно использовать многопоточность для выполнения распределённых приложений; например, многопоточный сервер может параллельно выполнять запросы сразу нескольких клиентов. Как известно, операционная система OS/2 одной из первых среди ОС, используемых на ПК, ввела многопоточность. В середине девяностых годов для этой ОС было создано очень большое количество приложений, в которых использование механизмов многопоточной обработки реально приводило к существенно большей скорости выполнения вычислений.
Итак, сущность «поток» была введена для того, чтобы именно с помощью этих единиц распределять процессорное время между возможными работами. Сущность «процесс» предполагает, что при диспетчеризации нужно учитывать все ресурсы, закрепленные за ним. А при манипулировании тредами можно менять только контекст задачи, если мы переключаемся с одной задачи на другую в рамках одного процесса. Все остальные вычислительные ресурсы при этом не затрагиваются. Каждый процесс всегда состоит, по крайней мере, из одного потока, и только если имеется внутренний параллелизм, программист может «расщепить» один тред на несколько параллельных.
Потребность в потоках (threads) возникла ещё на однопроцессорных вычислительных системах, поскольку они позволяют организовать вычисления более эффективно. Для использования достоинств многопроцессорных систем с общей памятью треды уже просто необходимы, так как позволяют не только реально ускорить выполнение тех задач, которые допускают их естественное распараллеливание, но и загрузить процессорные элементы работой, чтобы они не простаивали. Заметим, однако, что желательно, чтобы можно было уменьшить взаимодействие тредов между собой, ибо ускорение от одновременного выполнения параллельных потоков может быть сведено к минимуму из-за задержек синхронизации и обмена данными.
Каждый тред выполняется строго последовательно и имеет свой собственный программный счётчик и стек. Треды, как и процессы, могут порождать треды-потомки, поскольку любой процесс состоит, по крайней мере, из одного треда. Подобно традиционным процессам (то есть процессам, состоящим из одного треда), каждый тред может находится в одном из активных состояний. Пока один тред заблокирован (или просто находится в очерёди готовых к исполнению задач), другой тред того же процесса может выполняться. Треды разделяют процессорное время так же, как это делают обычные процессы, в соответствии с различными вариантами диспетчеризации.
Как мы уже знаем, все треды имеют одно и то же виртуальное адресное пространство своего процесса. Это означает, что они разделяют одни и те же глобальные переменные. Поскольку каждый тред может иметь доступ к каждому виртуальному адресу, один тред может использовать стек другого треда. Между потоками нет полной защиты, так как это, во-первых, невозможно, а во-вторых, не нужно. Все потоки одного процесса всегда решают общую задачу одного пользователя, и механизм потоков используется здесь для более быстрого решения задачи путем её распараллеливания. При этом программисту очень важно получить в свое распоряжение удобные средства организации взаимодействия частей одной программы. Повторим, что кроме разделения адресного пространства, все треды разделяют также набор открытых файлов, используют общие устройства, выделенные процессу, имеют одни и те же наборы сигналов, семафоры и т. п. А что у тредов будет их собственным? Собственными являются программный счетчик, стек, рабочие регистры процессора, потоки-потомки, состояние.
Вследствие того, что треды, относящиеся к одному процессу, выполняются в одном и том же виртуальном адресном пространстве, между ними легко организовать тесное взаимодействие, в отличие от процессов, для которых нужны специальные механизмы обмена сообщениями и данными. Более того, программист, создающий многопоточное приложение, может заранее продумать работу множества тредов процесса таким образом, чтобы они могли взаимодействовать наиболее выгодным способом, а не участвовать в конкуренции за предоставление ресурсов тогда, когда этого можно избежать.
Для того чтобы можно было эффективно организовать параллельное выполнение рассмотренных сущностей (процессов и тредов), в архитектуру современных процессоров включена возможность работать со специальной информационной структурой, описывающей ту или иную сущность. Для этого уже на уровне архитектуры микропроцессора используется понятие «задача» (task). Оно как бы объединяет в себе обычный и «легковесный» процессы. Это понятие и поддерживаемая для него на уровне аппаратуры информационная структура позволяют в дальнейшем при разработке операционной системы построить соответствующие дескрипторы, как для процесса, так и для треда. Отличаться эти дескрипторы будут, прежде всего, тем, что дескриптор треда может хранить только контекст приостановленного вычислительного процесса, тогда как дескриптор процесса (process) должен уже содержать поля, описывающие тем или иным способом ресурсы, выделенные этому процессу. Другими словами, тот же task state segment (сегмент состояния задачи), подробно рассмотренный в разделе «Адресация в 32-разрядных микропроцессорах i80x86 при работе в защищённом режиме» главы 3, используется как основа для дескриптора процесса. Каждый тред (в случае использования так называемой «плоской» модели памяти – см. раздел «Поддержка страничного способа организации виртуальной памяти», глава 3 – может быть оформлен в виде самостоятельного сегмента, что приводит к тому, что простая (не многопоточная) программа будет иметь всего один сегмент кода в виртуальном адресном пространстве.
В завершение можно привести несколько советов по использованию потоков при создании приложений, заимствованных из работы [55].
1 В случае использования однопроцессорной системы множество параллельных потоков часто не ускоряет работу приложения, поскольку в каждый отдельно взятый промежуток времени возможно выполнение только одного потока. Кроме того, чем больше у вас потоков, тем больше нагрузка на систему, потраченная на переключение между ними. Если ваш проект имеет более двух постоянно работающих потоков, то такая мультизадачность не сделает программу быстрее, если каждый из потоков не будет требовать частого ввода/ вывода.
2 Вначале нужно понять, для чего необходим поток. Поток, осуществляющий обработку, может помешать системе быстро реагировать на запросы ввода/ вывода. Потоки позволяют программе отзываться на просьбы пользователя и устройств, но при этом сильно загружать процессор. Потоки позволяют компьютеру одновременно обслуживать множество устройств, и созданный вами поток, отвечающий за обработку специфического устройства, в качестве минимума может потребовать столько времени, сколько системе необходимо для обработки запросов всех устройств.
3 Потокам можно назначить определенный приоритет для того, чтобы наименее значимые процессы выполнялись в фоновом режиме. Это путь честного разделения ресурсов CPU1. Однако необходимо осознать тот факт, что процессор один на всех, а потоков много. Если в вашей программе главная процедура передаёт нечто для обработки в низкоприоритетный поток, то сама программа становится просто неуправляемой.
4 Потоки хорошо работают, когда они независимы. Но они начинают работать непродуктивно, если вынуждены часто синхронизироваться для доступа к общим ресурсам. Блокировка и критические секции отнюдь не увеличивают скорость работы системы, хотя без использования этих механизмов взаимодействующие вычисления организовывать нельзя.
5 Помните, что память виртуальна. Механизм виртуальной памяти (см. раздел «Память и отображения, виртуальное адресное пространство», глава 2) следит за тем, какая часть виртуального адресного пространства должна находиться в оперативной памяти, а какая должна быть сброшена в файл подкачки. Потоки усложняют ситуацию, если они обращаются в одно и то же время к разным адресам виртуального адресного пространства приложения. Это значительно увеличивает нагрузку на систему, особенно при небольшом объёме кэш-памяти. Помните, что реально память не всегда «свободна», как это пишут в информационных «окошках» «О системе». Всегда отождествляйте доступ к памяти с доступом к файлу на диске и создавайте приложение с учётом вышесказанного.
6 Всякий раз, когда какой-либо из ваших потоков пытается воспользоваться общим ресурсом вычислительного процесса, которому он принадлежит, вы обязаны тем или иным образом легализовать и защитить свою деятельность. Хорошим средством для этого являются критические секции, семафоры и очерёди сообщений. Если вы протестировали свое приложение и не обнаружили ошибок синхронизации, то это ещё не значит, что их там нет. Пользователь может создать самые непредсказуемые ситуации. Это очень ответственный момент в разработке многопоточных приложений.
7 Не возлагайте на поток несколько функций. Сложные функциональные отношения затрудняют понимание общей структуры приложения, его алгоритм. Чем проще и менее многозначна каждая из рассматриваемых ситуаций, тем больше вероятность, что ошибок удастся избежать.
Прерывания
Прерывания представляют собой механизм, позволяющий координировать параллельное функционирование отдельных устройств вычислительной системы и реагировать на особые состояния, возникающие при работе процессора. Таким образом, прерывание – это принудительная передача управления от выполняемой программы к системе (а через неё – к соответствующей программе обработки прерывания), происходящая при возникновении определенного события.
Идея прерываний была предложена в середине 50-х годов и можно без преувеличения сказать, что она внесла наиболее весомый вклад в развитие вычислительной техники. Основная цель введения прерываний – реализация асинхронного режима работы и распараллеливание работы отдельных устройств вычислительного комплекса.
Механизм прерываний реализуется аппаратно-программными средствами. Структуры систем прерывания (в зависимости от аппаратной архитектуры) могут быть самыми разными, но все они имеют одну общую особенность – прерывание непременно влечет за собой изменение порядка выполнения команд процессором.
Механизм обработки прерываний независимо от архитектуры вычислительной системы включает следующие элементы:
1 Установление факта прерывания (прием сигнала на прерывание) и идентификация прерывания (в операционных системах иногда осуществляется повторно, на шаге 4).
2 Запоминание состояния прерванного процесса. Состояние процесса определяется, прежде всего, значением счетчика команд (адресом следующей команды, который, например, в i80x86 определяется регистрами CS и IP – указателем команды [2, 22, 84]), содержимым регистров процессора и может включать также спецификацию режима (например, режим пользовательский или привилегированный) и другую информацию.
3 Управление аппаратно передаётся подпрограмме обработки прерывания. В простейшем случае в счётчик команд заносится начальный адрес подпрограммы обработки прерываний, а в соответствующие регистры – информация из слова состояния. В более развитых процессорах, например в том же i80286 и последующих 32-битовых микропроцессорах, начиная с i80386, осуществляется достаточно сложная процедура определения начального адреса соответствующей подпрограммы обработки прерывания и не менее сложная процедура инициализации рабочих регистров процессора (см. раздел «Система прерываний 32-разрядных микропроцессоров i80x86», глава 3).
4 Сохранение информации о прерванной программе, которую не удалось спасти на шаге 2 с помощью действий аппаратуры. В некоторых вычислительных системах предусматривается запоминание довольно большого объёма информации о состоянии прерванного процесса.
5 Обработка прерывания. Эта работа может быть выполнена той же подпрограммой, которой было передано управление на шаге 3, но в ОС чаще всего она реализуется путем последующего вызова соответствующей подпрограммы.
6 Восстановление информации, относящейся к прерванному процессу (этап, обратный шагу 4).
7. Возврат в прерванную программу.
Шаги 1-3 реализуются аппаратно, а шаги 4-7 – программно.
На рис. 1.4 показано, что при возникновении запроса на прерывание естественный ход вычислений нарушается и управление передаётся программе обработки возникшего прерывания. При этом средствами аппаратуры сохраняется (как правило, с помощью механизмов стековой памяти) адрес той команды, с которой следует продолжить выполнение прерванной программы. После выполнения программы обработки прерывания управление возвращается прерванной ранее программе посредством занесения в указатель команд сохранённого адреса команды. Однако такая схема используется только в самых простых программных средах. В мультипрограммных операционных системах обработка прерываний происходит по более сложным схемам, о чём будет более подробно написано ниже.
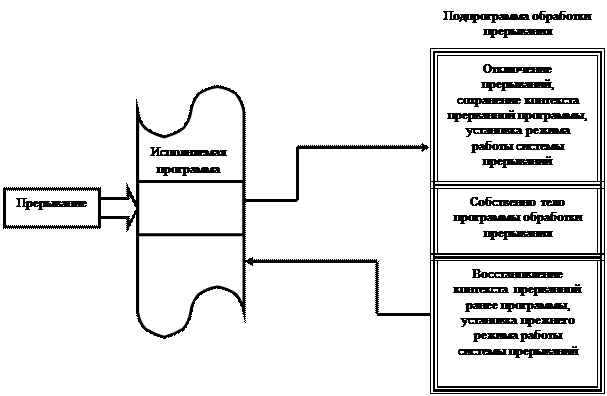 |
Рис. 1.4. Обработка прерывания
Итак, главные функции механизма прерываний:
¨ распознавание или классификация прерываний;
¨ передача управления соответственно обработчику прерываний;
¨ корректное возвращение к прерванной программе.
Переход от прерываемой программы к обработчику и обратно должен выполняться как можно быстрей. Одним из быстрых методов является использование таблицы, содержащей перечень всех допустимых для компьютера прерываний и адреса соответствующих обработчиков. Для корректного возвращения к прерванной программе перед передачей управления обработчику прерываний содержимое регистров процессора запоминается либо в памяти с прямым доступом, либо в системном стеке – system stack.
Прерывания, возникающие при работе вычислительной системы, можно разделить на два основных класса: внешние (их иногда называют асинхронными) и внутренние (синхронные).
Внешние прерывания вызываются асинхронными событиями, которые происходят вне прерываемого процесса, например:
¨ прерывания от таймера;
¨ прерывания от внешних устройств (прерывания по вводу/выводу);
¨ прерывания по нарушению питания;
¨ прерывания с пульта оператора вычислительной системы;
¨ прерывания от другого процессора или другой вычислительной системы.
Внутренние прерывания вызываются событиями, которые связаны с работой процессора и являются синхронными с его операциями. Примерами являются следующие запросы на прерывания:
¨ при нарушении адресации (в адресной части выполняемой команды указан запрещённый или несуществующий адрес, обращение к отсутствующему сегменту или странице при организации механизмов виртуальной памяти);
¨ при наличии в поле кода операции незадействованной двоичной комбинации;
¨ при делении на нуль;
¨ при переполнении или исчезновении порядка;
¨ при обнаружении ошибок чётности, ошибок в работе различных устройств аппаратуры средствами контроля.
Могут ещё существовать прерывания при обращении к супервизору ОС – в некоторых компьютерах часть команд может использовать только ОС, а не пользователи. Соответственно в аппаратуре предусмотрены различные режимы работы, и пользовательские программы выполняются в режиме, в котором эти привилегированные команды не исполняются. При попытке использовать команду, запрещённую в данном режиме, происходит внутреннее прерывание и управление передаётся супервизору ОС. К привилегированным командам относятся и команды переключения режима работа центрального процессора.
Наконец, существуют собственно программные прерывания. Эти прерывания происходят по соответствующей команде прерывания, то есть по этой команде процессор осуществляет практически те же действия, что и при обычных внутренних прерываниях. Данный механизм был специально введен для того, чтобы переключение на системные программные модули происходило не просто как переход в подпрограмму, а точно таким же образом, как и обычное прерывание. Этим обеспечивается автоматическое переключение процессора в привилегированный режим с возможностью исполнения любых команд.
Сигналы, вызывающие прерывания, формируются вне процессора или в самом процессоре; они могут возникать одновременно. Выбор одного из них для обработки осуществляется на основе приоритетов, приписанных каждому типу прерывания. Очевидно, что прерывания от схем контроля процессора должны обладать наивысшим приоритетом (если аппаратура работает неправильно, то не имеет смысла продолжать обработку информации). На рис.1.5 изображен обычный порядок (приоритеты) обработки прерываний в зависимости от типа прерываний. Учет приоритета может быть встроен в технические средства, а также определяться операционной системой, то есть кроме аппаратно реализованных приоритетов прерывания большинство вычислительных машин и комплексов допускают программно-аппаратное управление порядком обработки сигналов прерывания. Второй способ, дополняя первый, позволяет применять различные дисциплины обслуживания прерываний.
Наличие сигнала прерывания не обязательно должно вызывать прерывание исполняющейся программы. Процессор может обладать средствами защиты от прерываний: отключение системы прерываний, маскирование (запрет) отдельных сигналов прерывания. Программное управление этими средствами (существуют специальные команда для управления работой системы прерываний) позволяет операционной системе регулировать обработку сигналов прерывания, заставляя процессор обрабатывать их сразу по приходу, откладывать их обработку на некоторое время или полностью игнорировать. Обычно операция прерывания выполняется только после завершения выполнения текущей команды. Поскольку сигналы прерывания возникают в произвольные моменты времени, то на момент прерывания может существовать несколько сигналов прерывания, которые могут быть обработаны только последовательно. Чтобы обработать сигналы прерывания в разумном порядке им (как уже отмечалось) присваиваются приоритеты. Сигнал с более высоким приоритетом обрабатывается в первую очередь, обработка остальных сигналов прерывания откладывается.
 |
Рис. 1.5. Распределение прерываний по уровням приоритета
Программное управление специальными регистрами маски (маскирование сигналов прерывания) позволяет реализовать различные дисциплины обслуживания:
¨ с относительными приоритетами, то есть обслуживание не прерывается даже при наличии запросов с более высокими приоритетами. После окончания обслуживания данного запроса обслуживается запрос с наивысшим приоритетом. Для организации такой дисциплины необходимо в программе обслуживания данного запроса наложить маски на все остальные сигналы прерывания или просто отключить систему прерываний;
¨ с абсолютными приоритетами, то есть всегда обслуживается прерывание с наивысшим приоритетом. Для реализации этого режима необходимо на время обработки прерывания замаскировать все запросы с более низким приоритетом. При этом возможно многоуровневое прерывание, то есть прерывание программ обработки прерываний. Число уровней прерывания в этом режиме изменяется и зависит от приоритета запроса;
¨ по принципу стека, или, как иногда говорят, по дисциплине LCFS (last come first served – последним пришёл – первым обслужен), то есть запросы с более низким приоритетом могут прерывать обработку прерывания с более высоким приоритетом. Дли этого необходимо не накладывать маски ни на один сигнал прерывания и не выключать систему прерываний.
Следует особо отметить, что для правильной реализации последних двух дисциплин нужно обеспечить полное маскирование системы прерываний при выполнении шагов 1-4 и 6-7. Это необходимо для того, чтобы не потерять запрос и правильно его обслужить. Многоуровневое прерывание должно происходить на этапе собственно обработки прерывания, а не на этапе перехода с одного процесса на другой.
Управление ходом выполнения задач со стороны ОС заключается в организации реакций на прерывания, в организации обмена информацией (данными и программами), предоставлении необходимых ресурсов, в динамике выполнения задачи и в организации сервиса. Причины прерываний определяет ОС (модуль, который называют супервизором прерываний), она же и выполняет действия, необходимые при данном прерывании и в данной ситуации. Поэтому в состав любой ОС реального времени прежде всего входят программы управления системой прерываний, контроля состояний задач и событий, синхронизации задач, средства распределения памяти и управления ею, а уже потом средства организации данных (с помощью файловых систем и т. д.). Следует, однако, заметить, что современная ОС реального времени должна вносить в аппаратно-программный комплекс нечто большее, нежели просто обеспечение быстрой реакции на прерывания.
Как мы уже знаем, при появлении запроса на прерывание система прерываний идентифицирует сигнал и, если прерывания разрешены, управление передаётся на соответствующую подпрограмму обработки. Из рис.1.4 видно, что в подпрограмме обработки прерывания имеются две служебные секции. Это – первая секция, в которой осуществляется сохранение контекста прерванной задачи, который не смог быть сохранен на 2-м шаге, и последняя, заключительная секция, в которой, наоборот, осуществляется восстановление контекста. Для того чтобы система прерываний не среагировала повторно на сигнал запроса на прерывание, она обычно автоматически «закрывает» (отключает) прерывания, поэтому необходимо потом в подпрограмме обработки прерываний вновь включать систему прерываний. Установка рассмотренных режимов обработки прерываний (с относительными и абсолютными приоритетами, и по правилу LCFS) осуществляется в конце первой секции подпрограммы обработки. Таким образом, на время выполнения центральной секции (в случае работы в режимах с абсолютными приоритетами и по дисциплине LCFS) прерывания разрешены. На время работы заключительной секции подпрограммы обработки система прерываний должна быть отключена и после восстановления контекста вновь включена. Поскольку эти действия необходимо выполнять практически в каждой подпрограмме обработки прерываний, во многих операционных системах первые секции подпрограмм обработки прерываний выделяются в специальный системный программный модуль, называемый супервизором прерываний
Супервизор прерываний прежде всего сохраняет в дескрипторе текущей задачи рабочие регистры процессора, определяющие контекст прерываемого вычислительного процесса. Далее он определяет ту подпрограмму, которая должна выполнить действия, связанные с обслуживанием настоящего (текущего) запроса на прерывание. Наконец, перед тем как передать управление этой подпрограмме, супервизор прерываний устанавливает необходимый режим обработки прерывания. После выполнения подпрограммы обработки прерывания управление вновь передаётся супервизору, на этот раз уже на тот модуль, который занимается диспетчеризацией задач (см. раздел «Качество диспетчеризации и гарантии обслуживания», глава 2). И уже диспетчер задач, в свою очередь, в соответствии с принятым режимом распределения процессорного времени (между выполняющимися процессами) восстановит контекст той задачи, которой будет решено выделить процессор. Рассмотренная нами схема проиллюстрирована на рис. 1.6.
 |
Рис. 1.6. Обработка прерывания при участии супервизоров ОС
Как мы видим из рис. 1.6, здесь нет непосредственного возврата в прерванную ранее программу непосредственно из самой подпрограммы обработки прерывания. Для прямого непосредственного возврата достаточно адрес возврата сохранить в стеке, что и делает аппаратура процессора. При этом стек легко обеспечивает возможность возврата в случае вложенных прерываний, поскольку он всегда реализует дисциплину LCFS (last come – first served).
Однако если бы контекст процессов сохранялся просто в стеке, как это обычно реализуется аппаратурой, а не в описанных выше дескрипторах задач, то у нас не было бы возможности гибко подходить к выбору той задачи, которой нужно передать процессор после завершения работы подпрограммы обработки прерывания. Естественно, что это только общий принцип. В конкретных процессорах и в конкретных ОС могут существовать некоторые отступления от рассмотренной схемы и/или дополнения к ней. Например, в современных процессорах часто имеются специальные аппаратные возможности для сохранения контекста прерываемого процесса непосредственно в его дескрипторе, то есть дескриптор процесса (по крайней мере, его часть) становится структурой данных, которую поддерживает аппаратура.
Для полного понимания принципов создания и механизмов реализации рассматриваемых далее современных ОС необходимо знать архитектуру персональных компьютеров и, в частности, особенности системы прерывания. Этот вопрос более подробно рассмотрен в главе 4 «Управление вводом/выводом и файловые системы», посвящённом архитектуре микропроцессоров i80x86.
Дата добавления: 2022-02-05; просмотров: 721;
Поиск по сайту
Узнать еще
- I. Математические понятия
- I. Специфические особенности процесса воспитания в сравнении с процессом обучения.
- II. Базовые понятия музыкальной акустики
- II. Формализация процесса формирования математических моделей
- IX. ОСОБЕННОСТИ ПРОЦЕССА НАУЧНОГО ПОЗНАНИЯ
- XI. Требования к приему детей в дошкольные образовательные организации, режиму дня и организации воспитательно-образовательного процесса
- А. Составление схемы технологического процесса
- Автоматизация процесса

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
