Парный корреляционный анализ. Построение модели линейной регрессии лингвистической информации
Цель: Овладеть умением оценивать величину корреляционной зависимости лингвистических величин, практического построения простой линейной регрессии по экспериментальным данным и проверки её адекватности в пакете анализа данных SPSS.
Задание:На основе полученных статистических данных о числе существительных и местоимений в выбранных фрагментах проверить гипотезу о статистической зависимости частот появления в русских литературных текстах имён существительных и местоимений.
План выполнения работы :
1) Сформировать нулевую Н0 и альтернативную Н1 гипотезы.
2) Найти выборочный коэффициент корреляции по формуле 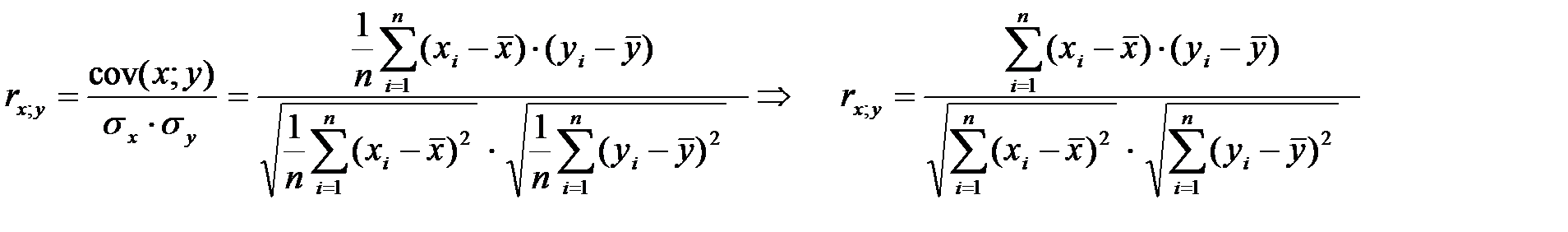
Сделать вывод о величине и знаке корреляционной зависимости.
3) Проверить значимость связи: если 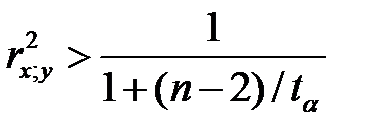 , то выборочный коэффициент корреляции значимо отличается от нуля, те связь значима с уровнем значимости α
, то выборочный коэффициент корреляции значимо отличается от нуля, те связь значима с уровнем значимости α
( 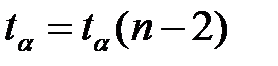 ‑ критическое значение распределения Стьюдента с n-2 степенями свободы, соответствующее уровню значимости α).
‑ критическое значение распределения Стьюдента с n-2 степенями свободы, соответствующее уровню значимости α).
Сделать вывод о значимости корреляционной зависимости.
4) Построить корреляционное поле, т.е. изобразить в координатной плоскости все выборочные точки (получим общую картину взаимной изменчивости случайных величин).
5) Найти и построить уравнения выборочных линий регрессии (уравнения прямых, с помощью которых приближённо можно описать зависимость Y(x) и X(y)) .Уравнения линий регрессий:
(у по х) 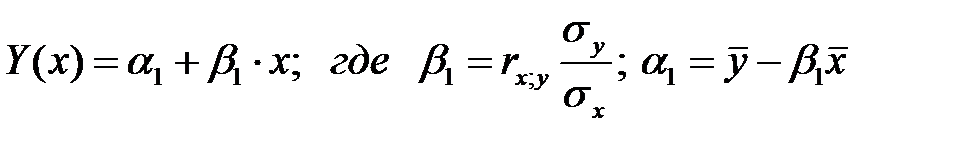 ;
;
(х по у) 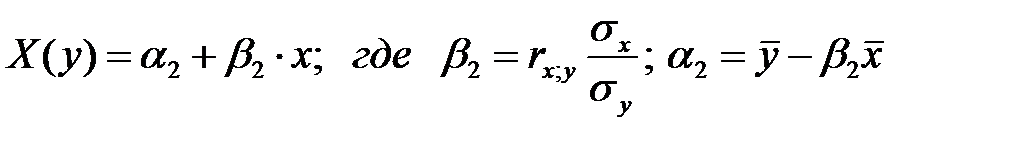
Сделать вывод о принятии или опровержении гипотезы Н0.
Для решения задачи в программе SPSS выполнить следующее.
1. Построить корреляционную матрицу для переменных Х (частсущ) и Y (частмест), предназначенную для оценки степени их зависимости. Войти в меню Анализ – корреляции – парные. В открывшемся окне "Парные корреляции" перенести с помощью стрелки переменные Х (частсущ) и Y(частмест) в окно "переменные". По умолчанию в окне "коэффициенты корреляции» отмечен коэффициент Пирсона - нажать ОК. В открывшемся окне вывода получаем квадратную корреляционную матрицу, в верхней строчке которой выведены коэффициенты корреляции, далее – уровень значимости и N – число наблюдений.
2. Для того чтобы наглядно увидеть существующую зависимость переменных, построим график двумерного рассеивания. Откроем меню Графика – устаревшие диалоговые окна – рассеяния/точки – простая диаграмма рассеяния – задать. В окне Диаграммы рассеяния переместить переменную Y(частмест) в окно Ось Y, а переменную Х(частсущ) - в окно Ось Х. Нажать ОК.
3. Построим линии регрессии. Откроем меню Анализ >Регрессия> Подгонка кривых.
В открывшемся диалоговом окне переместим в окно "Зависимые" переменную "Частмест", а в окно "Независимые" переменные переменную "Частсущ".В окне"Модели"поставим флажок в квадратике"Линейная" Нажать ОК.
В окне вывода получим точки двумерного рассеяния и линию регрессии Z(Y)
«Одной из закономерностей работы языкового механизма современного русского языка является отрицательное коррелирование имён существительных и местоимений, т. е. увеличение активности одной из этих частей речи за счёт другой».
Дата добавления: 2016-06-05; просмотров: 3052;
Поиск по сайту
Узнать еще
- D-технология построения чертежа. Типовые объемные тела: призма, цилиндр, конус, сфера, тор, клин. Построение тел выдавливанием и вращением. Разрезы, сечения.
- II. Построение продольного профиля по оси трассы
- А. Аналитические модели.
- А. Модели экономического прогноза на базе производственных функций.
- Автоматизация технологического проектирования. Основные задачи и модели автоматизации технологического проектирования
- Автоматизация ТП. Моделирование техпроцесса.
- АВТОРСКИЕ МОДЕЛИ ПСИХОЛОГИЧЕСКОЙ СЛУЖБЫ, ИЛИ КАК ОБРЕСТИ СВОЕ ЛИЦО
- Адекватность информации

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
